坐看云起时 杜甫很忙之云计算系列

1/19
云计算(cloud computing)是基于互联网的相关服务的增加、使用和交付模式,通常涉及通过互联网来提供动态易扩展且经常是虚拟化的资源。今天杜甫老师用事实说话,告诉大家云计算的来龙去脉。
2/19
“云计算”这个概念自诞生以来迅速风靡 IT 业界,业界巨擘大举杀入“言必称‘云计算’”的云时代。甲骨文 CEO 拉里-埃里森说:“如果有哪个行业比女人们的时尚业更赶潮流和时尚,那非计算机业莫属了。”更有业界大佬穿上云一样的霓裳羽衣登上时尚杂志封面博君一笑,然而从来没有人看到过云计算在霓裳轻解后的样子。

3/19
科技水平的不断发展,性能越来越高的电脑,带宽越来越大的网络,这些东西给人们的工作和生活带来了很大的便利。同时也对数据的处理提出了很高的要求。
4/19
随着社会经济的迅速发展,人口的急剧增多,人类在生产和生活过程中促进社会经济的发展、物质生活的丰富和生活福利的提高,人们对于精神生活的要求也越来越高。网络上流通的数据也越来越大。
5/19
为了处理日益增多的数据,人们不断的更新技术,更新服务器。
6/19
随着数据越来越多,服务器的使用也越来越多。越来越大的机房和数据中心不断的建设。但是这样也带来了成本以及管理上的危机。
7/19
过度繁重的结构加大了网站设计和构架的难度,而且越是复杂的系统越是不稳定。有可能一个出问题,这样一个完整的系统就彻底挂掉。如果考虑到系统的崩溃情况,那势必要引入一个更复杂的方案来保证不同的服务器可以做不同的支援。这是一个无解的循环,大量的计算资源被浪费在无限制的互相纠结中,很快到了瓶颈。

8/19
人们突然想到了一个好办法:把所有计算资源集结起来看成是一个整体(一朵云),通过并发使用资源完成操作请求。每个操作请求都可以按照一定的规则分割成小片段,分发给不同的机器同时运算,每个机器其实只要做很小的计算就可以,这是哪怕 286机器都轻松完成的。最后将这些机器的计算结果整合,输出给用户。对用户看来,他其实根本面对的不是许多机器,而是一个似乎真正存在的计算能力巨牛无比的单个服务器,比十台System z10 大型主机揉一起,或是开创了petaflop 新纪元的“拂晓”号与“红杉”号还要牛。

9/19
好比是从古老的单台发电机模式转向了电厂集中供电的模式。人们希望云计算可以将计算能力作为一种商品进行流通,就像煤气、水电一样,取用方便,费用低廉。
10/19
云计算不是弄个两三台质低价廉的服务器就可以达成的。每一朵云背后都有着一坨异构平台服务器,尤其是搭在企业防火墙里头的“私有云”。因为企业的计算需求往往是复杂的,选择不同的平台应对不同的计算需求最划算,这跟农民伯伯拉什么或选什么车的道理一样。新鲜大白菜首选摩托车,保新鲜求快就用刀片;高级大白菜首选靠谱运输工具Power 服务器;大量的高级大白菜选择大货车,正如 I/O 吞吐量大的数据适合使用大型主机 System z 一样,总比牛车一趟两趟要快吧?大型农场不会局限于某一种植物正如大型企业不会只有一种计算需求。
11/19
竖井式IT的一个简单的实例,在流程和数据停留的自己的小空间里,通常不予其他系统交互。显然,云计算中这个数据应用似乎和竖井具有同样的理念。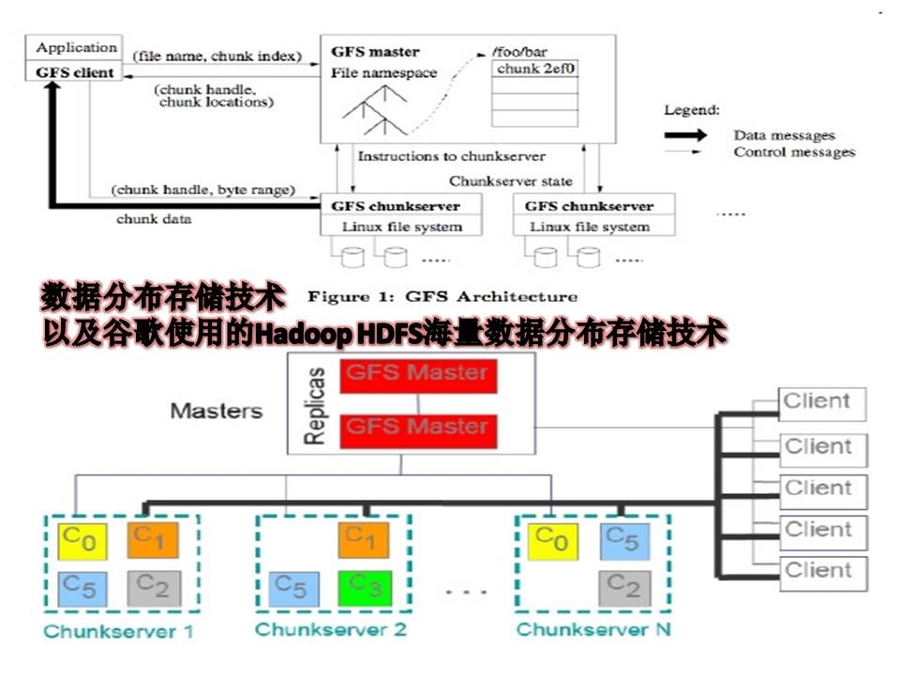
12/19
云计算系统由大量服务器组成,同时为大量用户服务,因此云计算系统采用分布式存储的方式存储数据,用冗余存储的方式保证数据的可靠性。云计算系统中广泛使用的数据存储系统是Google的GFS和Hadoop团队开发的GFS的开源实现HDFS。GFS即Google文件系统(Google File System),是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。GFS的设计思想不同于传统的文件系统,是针对大规模数据处理和Google应用特性而设计的。它运行于廉价的普通硬件上,但可以提供容错功能。
13/19
云计算需要对分布的、海量的数据进行处理、分析,因此,数据管理技术必需能够高效的管理大量的数据。云计算系统中的数据管理技术主要是Google的BT(BigTable)数据管理技术和Hadoop团队开发的开源数据管理模块HBase。BT是建立在GFS, Scheduler, Lock Service和MapReduce之上的一个大型的分布式数据库,与传统的关系数据库不同,它把所有数据都作为对象来处理,形成一个巨大的表格,用来分布存储大规模结构化数据。
14/19
数据独立性表示应用程序与数据库中存储的数据不存在依赖关系,包括逻辑数据独立性和物理数据独立性。数据独立性的好处是,数据的物理存储设备更新了,物理表示及存取方法改变了,但数据的逻辑模式可以不改变。数据的逻辑模式改变了,但用户的模式可以不改变,因此应用程序也可以不变。这将使程序维护容易,另外,对同一数据库的逻辑模式,可以建立不同的用户模式,从而提高数据共享性,使数据库系统有较好的可扩充性,给DBA维护、改变数据库的物理存储提供了方便。

15/19
NoSQL,指的是非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展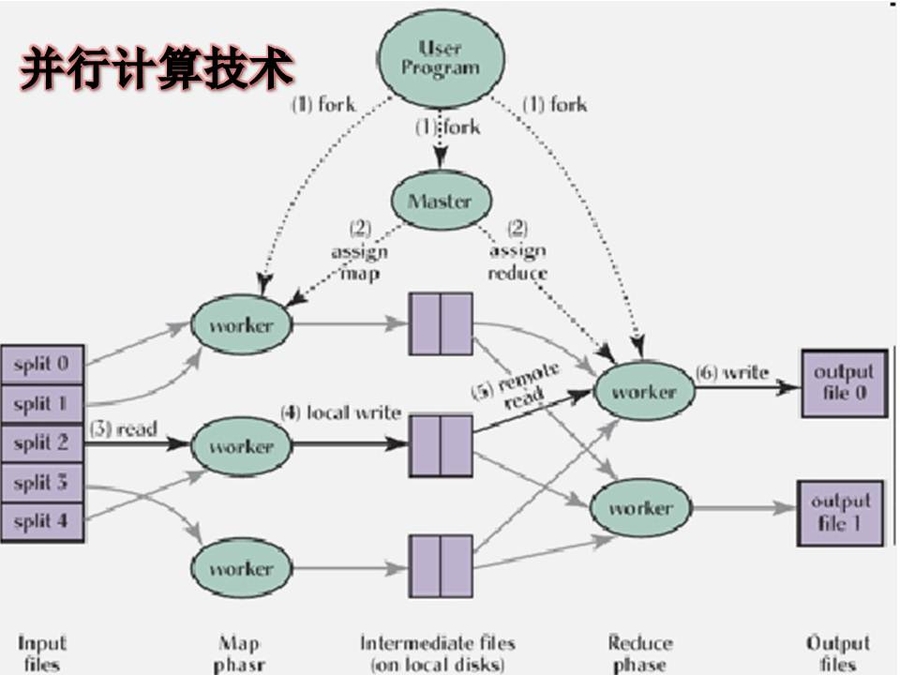
16/19
相对于串行计算,并行计算可以划分成时间并行和空间并行。时间并行即流水线技术,空间并行使用多个处理器执行并发计算,当前研究的主要是空间的并行问题。以程序和算法设计人员的角度看,并行计算又可分为数据并行和任务并行。数据并行把大的任务化解成若干个相同的子任务,处理起来比任务并行简单。并行计算机有以下五种访存模型:均匀访存模型(UMA)、非均匀访存模型(NUMA)、全高速缓存访存模型(COMA)、一致性高速缓存非均匀存储访问模型(CC-NUMA)和非远程存储访问模型(NORMA)。
17/19
通过虚拟化技术可实现软件应用与底层硬件相隔离,它包括将单个资源划分成多个虚拟资源的裂分模式,也包括将多个资源整合成一个虚拟资源的聚合模式。虚拟化技术根据对象可分成存储虚拟化、计算虚拟化、网络虚拟化等,计算虚拟化又分为系统级虚拟化、应用级虚拟化和桌面虚拟化。

18/19
VLAN网络可以是有混合的网络类型设备组成,比如:10M以太网、100M以太网、令牌网、FDDI、CDDI等等,可以是工作站、服务器、集线器、网络上行主干等等。VLAN除了能将网络划分为多个广播域,从而有效地控制广播风暴的发生,以及使网络的拓扑结构变得非常灵活的优点外,还可以用于控制网络中不同部门、不同站点之间的互相访问。VLAN是为解决以太网的广播问题和安全性而提出的一种协议,它在以太网帧的基础上增加了VLAN头,用VLAN ID把用户划分为更小的工作组,限制不同工作组间的用户互访,每个工作组就是一个虚拟局域网。虚拟局域网的好处是可以限制广播范围,并能够形成虚拟工作组,动态管理网络。
19/19
在已有的计算资源的基础不变的情况下,云计算把用户的任务请求做除法,一个请求进来,我们把它变成许多个小任务段,最后汇总出去给用户一个完整的结果。对用户来说,他根本感觉不到里面哪个cpu做了什么处理,哪部分是哪部分拼接起来的,他就感觉自己面对一台5亿内存3亿GHZ的巨无霸电脑一样。