持续提升虚拟机性能是所有云计算工程师研究的方向,其中一个重要方式便是使用大页内存。本文从内存映射出发为读者浅析大页内存的相关概念和基础操作,并以此为延伸,与各位分享华云产品技术中心计算团队在大页内存动态分配方面的探索与实践。
MMU 与内存映射
在计算机系统结构中,我们知道,CPU是通过寻址来访问内存的。例如,32 位 CPU 的寻址宽度是 0~0xFFFFFFFF ,通过换算可得为 4G,即可支持的物理内存最大是 4G。
然而在实践过程中会产生各种各样的问题,若某个程序需要使用 4G 内存,而此时可用的物理内存小于 4G,这就导致程序不得不降低内存的占用。因此为了解决此类问题,现代 CPU 引入了 MMU(Memory Management Unit 内存管理单元)。MMU 的核心思想是利用虚拟地址替代物理地址,即CPU寻址时使用虚址,由 MMU 负责将虚址映射为物理地址。 MMU的引入,解决了对物理内存的限制。
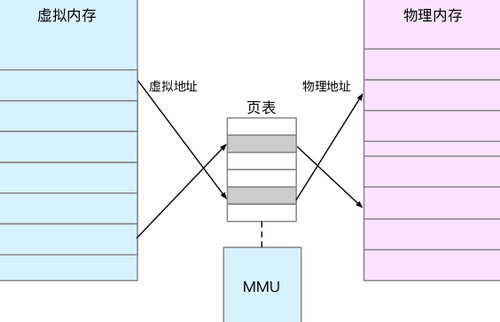
而内存映射则是将虚拟内存地址映射到物理内存地址。为了完成内存映射,内核为每个进程都维护了一张页表,记录虚拟地址与物理地址的映射关系。
页表实际上存储在 CPU 的内存管理单元 MMU 中,这样,CPU 就可以直接通过硬件,找出要访问的内存。
什么是 HugePages
大页内存(HugePages),顾名思义就是拥有更大页面的内存页,HugePages 提供了 4K 页面大小的替代方案,即提供更大的页面,在特定场景下对于性能有着非常明显的提升。
HugePages 的查看与分配
在 Linux 中,可以使用如下命令查看大页内存
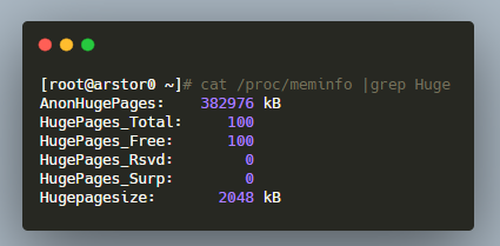
我们对其中的字段分别做一下解释
AnonHugePages: 透明大页的大小
HugePages_Total: 大页资源池中的大页总量
HugePages_Free: 池中未使用的大页的数量
HugePages_Rsvd: 已经被分配预留但是还没有使用的大页数目
HugePages_Surp: 池中大于/proc/sys/vm/nr_hugepages 中值的 HugePages 数量
HugePagesize: 单块大页的大小
通常来说,我们会使用 2M 的大页,即 HugePagesize = 2048 KB。
请注意,这里关于大页所有的单位都是数量(页),而不是大小(KB)。举个例子,如图所示,HugePages_Total 的值为 100,那么在这台机器上大页会占用多少的内存呢?
答案是 200M,即 HugePages_Total * HugePagesize,100 * 2048KB = 200M。
那么,如何分配 HugePages 呢?
分配 HugePages 主要有两种方法。
一是修改 /etc/grub2.cfg 文件中启动菜单的内核参数,这样做的好处在于,当系统启动时,拥有连续内存的空间(用于 HugePages 分配)的机会要大得多。
二是通过 sysctl vm.nr_hugepages 的命令进行临时分配,这种方式胜在分配灵活,而弊端则是,当系统内存被使用到一定程度时,连续内存页的数量会变少,即在物理内存有剩余时,却无法分配 HugePages 。
OpenStack 社区的方案
在 OpenStack 中,libvirt 的 driver 会去检查用户是否在 flavor 中配置大页的相关选项,并直接从已分配的资源池中划分相关资源给虚拟机。
这就带来了一个问题,即大页资源池需要用户提前分配。提前分配好的大页资源池会直接占据这部分的内存空间,且随着资源池内可用大页数量的降低,用户在一段时间后无法继续创建大页内存的虚拟机。
归根结底,OpenStack 本身并没有提供一套用于管理和维护大页资源池的机制。
ArStack 做了哪些尝试
这就回到了这篇分享的主题,有什么办法能够尽可能多地创建高性能的大页虚拟机,同时又避免云平台初期大页资源池分配时,过多地占用系统内存呢?
基于这一出发点,华云计算团队设计了一套动态维护大页资源池的系统。
用户可以在系统初始化时,以一个较低的值手动设置初始大页资源池的大小,Nova 的某个周期性定时任务会在一定时间间隔内检查各个计算节点的大页资源池是否满足预设的策略。
当初始资源池消耗殆尽时,Nova 会对大页资源池进行自动扩容,以维持一个资源相对富裕的状态。同时,Nova-Scheduler 在创建大页虚拟机时也会对各个节点的计算资源进行检查,若都不满足虚拟机所需资源, Nova-Scheduler 会计算相应的资源缺口,并尝试进行扩容。
在大页虚拟机被删除后,相应的大页资源会被释放,并流入大页资源池。此时,Nova 检测到该计算节点的大页资源池存在过多未被分配的大页时,会进行缩容操作,以释放被占用的物理内存,从而减少了物理内存占用过多的情况。
基于这套动态分配方案,最终实现了性能与灵活兼得的目标。
后记
OpenStack 中很多逻辑都是牵一发而动全身的,在实践过程中,Nova-Scheduler 、NUMA 以及 ArStack 的内存预分配都针对 HugePages 相关场景进行了对应的调整和优化。
在此感谢计算团队所有同学的辛勤付出。未来,ArStack 会继续努力,持续为用户提供更加优质的私有云产品。

