这两年,Kubernetes 击败了 Swarm 和 Mesos,几乎成为容器编排的事实标准,BAT、滴滴、京东、头条等大厂,都争相把容器和 K8S 项目作为技术重心。
为什么在众多容器平台中,Kubernetes能够脱颖而出,是因为Kubernetes的接口和概念设计是完全站在应用角度而非运维角度的。
如果站在传统运维人员的角度看 Kubernetes,会觉得他是个奇葩所在,容器还没创建出来,概念先来一大堆,文档先读一大把,编排文件也复杂,组件也多,让很多人望而却步。
但是如果开发人员的角度,尤其是从微服务应用的架构的角度来看Kubernetes,则会发现,他对于微服务的运行生命周期和相应的资源管控,做了非常好的抽象。
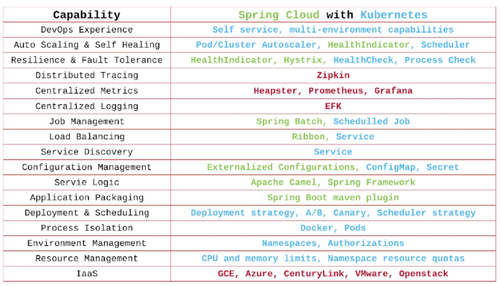
如图中所示,和虚拟机运行传统应用,只需要创建出资源来,并且保证网络畅通即可的方式不同,微服务的运行,需要完成左面的一系列工具链。
为什么要使用这些工具链,以及如何使用这些工具链,请参考我的另外两篇文章以业务为核心的云原生体系建设和从1到2000个微服务,史上最落地的实践云原生25个步骤。
你会发现,Kubernetes都有相应的工具链可以匹配。
微服务设计重要的一点就是区分无状态和有状态,在 K8S 中,无状态对应 deployment,有状态对应 StatefulSet。
deployment 主要通过副本数,解决横向扩展的问题。
而 StatefulSet 通过一致的网络 ID,一致的存储,顺序的升级,扩展,回滚等机制,保证有状态应用,很好地利用自己的高可用机制。因为大多数集群的高可用机制,都是可以容忍一个节点暂时挂掉的,但是不能容忍大多数节点同时挂掉。而且高可用机制虽然可以保证一个节点挂掉后回来,有一定的修复机制,但是需要知道刚才挂掉的到底是哪个节点,StatefulSet 的机制可以让容器里面的脚本有足够的信息,处理这些情况,实现哪怕是有状态,也能尽快修复。
微服务少不了服务发现,除了应用层可以使用 SpringCloud 或者 Dubbo 进行服务发现,在容器平台层当然是用 Service了,可以实现负载均衡,自修复,自动关联。
服务编排,本来 K8S 就是编排的标准,可以将 yml 文件放到代码仓库中进行管理,而通过 deployment 的副本数,可以实现弹性伸缩。
对于配置中心,K8S 提供了 configMap,可以在容器启动的时候,将配置注入到环境变量或者 Volume 里面。但是唯一的缺点是,注入到环境变量中的配置不能动态改变了,好在 Volume 里面的可以,只要容器中的进程有 reload 机制,就可以实现配置的动态下发了。
统一日志中心,监控中心,APM往往需要在 Node 上部署 Agent,来对日志和指标进行收集,当然每个 Node 上都有,daemonset 的设计,使得更容易实现。
Kubernetes本身能力比较弱的就是服务的治理能力,这一点 Service Mesh,可以实现更加精细化的服务治理,进行熔断,路由,降级等策略。Service Mesh 的实现往往通过 sidecar 的方式,拦截服务的流量,进行治理。这也得力于 Pod 的理念,一个 Pod 可以有多个容器,如果当初的设计没有 Pod,直接启动的就是容器,会非常的不方便。
所以,掌握容器技术成为很多公司招聘时的重要选项。
这两年,跟朋友探讨 K8S落地时,也有一些问题被反复提及,比如:
为什么容器里只能跑“一个进程”?
之前一直用的某个 JVM 参数,在容器里怎么不好使了?
为什么 Kubernetes 不能固定 IP 地址?容器网络连不通,该如何 Debug?
K8S 中 StatefulSet 和 Operator 到底什么区别?PV 和 PVC 又该怎么用?
这些问题的答案和原理并不复杂,但很难一两句话解释清楚。因为容器技术涉及操作系统、网络、存储、调度、分布式原理等方方面面的知识,是个名副其实的全栈技术。
而其技术体系里那些“牵一发而动全身”的主线,比如 Linux 进程模型对容器本身的重要意义,“控制器”模式对整个 K8S 项目提纲挈领的作用等等,不会详细展现在 Docker 或 Kubernetes 官方文档中,但偏偏就是它们,才是掌握容器技术体系的精髓所在。

