斗鱼数据库混合云架构实践
从传统数据库架构迁移至云数据库,如何实现平滑迁移?在多云、混合云以及多机房环境下,如何解决高可用和运维挑战?本文结合斗鱼实际业务环境,具体介绍了混合云架构实践及运维过程!

▲本期分享嘉宾:赵闪 武汉斗鱼网络科技有限公司 DBA主管
嘉宾介绍:
赵闪,2014年研究生毕业,2014年中国电信DBA,2016年加入斗鱼直播;现负责斗鱼数据库的运维架构以及数据库团队的管理,发表了多篇关于数据库故障切换的专利;对多种数据库均有一定研究,主要熟悉的数据库有MySQL、postgresql、MongoDB、redis等;
熟悉多种业务场景架构,对维护高并发和海量数据业务有一定经验;目前主要工作为数据库中间件开发和相关工具平台开发。
如何实现数据库平滑迁移
企业之前的数据都在自建的IDC里,如何把PB级数据同步到云上去?每天增量的数据也是TB级,这些数据如何快速高效地同步到云上去?数据同步过程中速度比较慢,如何解决?如何把业务安全、高效地迁移到云上去 ?这些都是数据库迁移过程中,必然会遇到的问题!
具体而言,数据库上云会遇到3个重要的架构迁移问题:
1、 统一账号,流量收拢
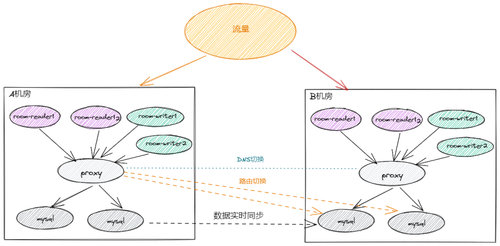
从A机房到B机房,最首要的问题就是流量、DNS切换、路由切换,如何在不停业务的情况下,通过一个统一的平台,实现账号管理以及流量的收拢,是一个重要挑战。
2、 数据实时同步
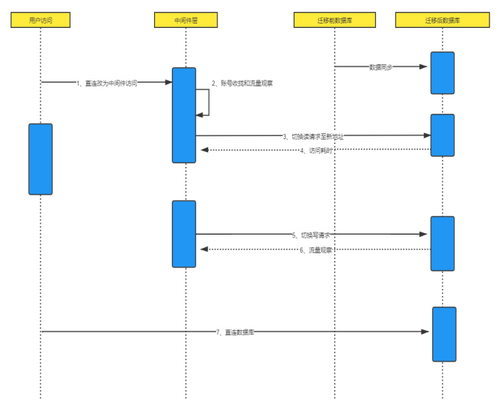
在数据库迁移之前,用户访问数据会直接到中间件层,然后再到迁移前的数据库。但是为了确保业务不受影响,迁移过程中要做一些调整。迁移前的数据库和迁移后的数据库会有一段时间并行。这时,整个业务架构要充分考虑到数据同步、请求切换以及访问耗时等问题。
3、读写流量分离
在数据库迁移时,还要考虑自动读写分离以及读写分离路由的规则。因为,大量流量来到数据库,会造成IO飙升,使得请求变慢,导致数据库CPU飙升无法响应,所以在迁移架构设计上,一般要考虑如何做到主从读写分离。
面对上述挑战,斗鱼的做法是观察业务访问形态,确定业务访问逻辑,同时关注读写比例,确定迁移顺序。为了确保数据的实时同步,还要关注时延和业务敏感性,测试直连和代理性能差异 ,测试业务兼容性。新数据库上线后,即便做了读写分离,也要随时关注流量压力以及参数对比,确保整个业务的平稳运行。
混合云场景下的负载均衡和故障切换
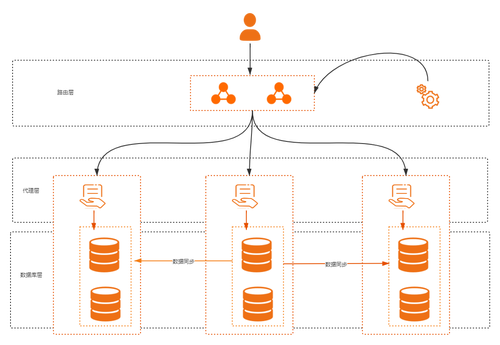
随着业务量的增加,会采用多活架构来解决负载均衡和故障切换的问题。
比如:A机房是主力机房,提供核心业务80%流量,边缘业务50%流量;B机房承载20%的核心业务流量,50%的边缘业务流量;C机房提供其他业务以及灾备,比如离线分析等场景。
具体的做法是,不管是路由层、代理层还是数据库层,全部由配置中心统一配置并下发各个机房。其中,路由层实现机房流量、读写流量的调度;数据通过专线保证一致性,实现数据响应到达秒级以内的延迟。
整个设计规则是,每个机房都有流量,每个机房都能读写,是完全的多活,遇到单元高可用以及单元故障问题,直接转移到另一个机房继续提供服务。
比如:A机房发生故障时,B机房承接流量,保证业务连续性。要根据故障时间、写沉默时间设置业务逻辑。故障发生时,未完成的处理逻辑进入异常状态,进行回滚和补偿处理。整个过程中,系统要做到读秒级切换,保证事务完整执行,避免因事务导致数据丢失或者重复操作,进而出现数据的不一致性。
混合云场景下的降级容灾
混合云、多云虽然在性能、弹性灵活、方便易用等方面有着诸多优势,但云环境同时又是个“黑盒”,仍然存在容灾和高可用的问题,需要一定的策略来确保数据不丢失。
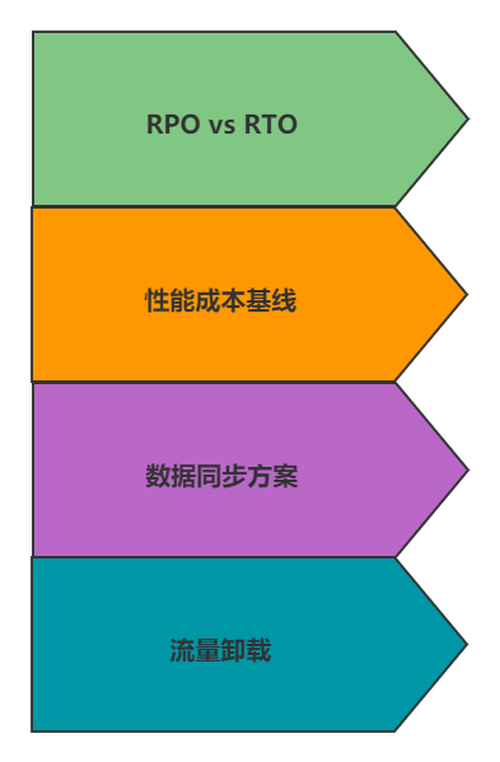
大体来看,故障容灾主要集中在四个维度:
1、 RPO VS RTO
RPO和 RPO 都是企业灾难恢复需要重点考虑的关键指标,这两个指标可以用来指导企业来制定合适的业务系统服务或数据的恢复方案。
RPO.即数据恢复点目标,主要指的是业务系统所能容忍的数据丢失量。如果以定期计划的24小时增量备份全部或大部分数据,那么在最坏的情况下,全量备份和日志恢复可能导致企业丢失1-2个事务的数据,对于大部分应用来说,是可以接受的。
RTO即恢复时间目标,主要指的是所能容忍的业务停止服务的最长时间,也就是从灾难发生到业务系统恢复服务功能所需要的最短时间周期,此两点之间的时间段称为RTO。比如: 4小时RTO允许从裸机恢复开始进行本地恢复,并以完整的应用程序和数据可用性结束。
RTO 和 RPO 都使用时间来度量,但是使用它们的目的却不相同。RTO 关注于应用或系统的可用性,RPO 关注于数据的完整性,描述所能容忍的最大数据丢失限制。
在制定容灾计划时,需要根据业务特点确定 RTO 和 RPO目标。
2、 性能成本基线
把容灾放到云上,成本会降低不少。云上应用和本地一样,当系统的操作响应时间超出可接受的程度,说明已出现了性能问题。每秒请求处理量(QPS),是对一个特定的应用系统在规定时间内所处理流量多少的衡量标准,要设定好这个基线。
3、 数据同步
常见的容灾模式比较简单,包括:数据库冷备,即每天备份一次数据库;双机本地热备,即一份数据存在不同盘阵上并多存几份,保证坏一个盘不影响数据读写;数据库热备,建立数据库灾备中心,与主库实时进行数据同步,同时应用系统保持文件实时同步,保证引用版本最新。为了实现从源数据库到目标数据库的实时数据同步,要重点关注耗时数据。
4、流量卸载
为了确保整个业务环境的健壮性,还要重点关注流量。当请求量大,但时效性不高的时候,可将限流数控制小一些;当请求量大,但时效性高的时候,可将限流数适当调高,同时要分离读写流量。
最后,要能够提供柔性有损服务,当条件有限而不能向用户提供完美服务时,可以以柔性的方式提供有损的服务,最大程度的保证关键服务的可用性。
当然,为了让容灾方案实现价值最大化,对业务进行等级划分也是重中之重。对于核心业务要实现双向同步,以两地多中心的方式进行容灾;对于关键业务,要能够实现实时同步,做到双活;对于重要业务,要实现主从同步,以主备模式保护数据和应用;对于边缘业务,要能够实现定时同步,做到灾备层面的万无一失。
云原生场景下的数据库运维挑战
如今,数据库也在拥抱云原生方向,为了让云上应用更加方便、快捷,斗鱼有三个重要实践。
1、 接口化
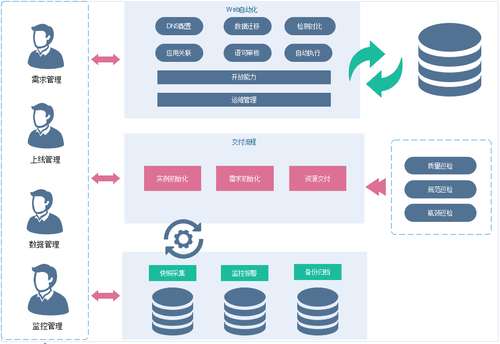
整个管理平台被分为四大层面,包括需求管理、上线管理、数据管理和监控管理。每一层分管不同的业务。
比如:需求管理解决的是DNS配置、数据迁移、检测对比等WEB自动化的能力,同时还包括其他开发能力、运维管理等。上线管理解决的是从实例初始化到需求管理再到资源交付过程的整个流程,并且与质量巡检、规范巡检、瓶颈巡检紧密关联。
所以应用与应用之间,均以接口化的形式处理,可以通过API调用的方式实现,极大地方便了云数据库层面的统一管理和快速应用。
2、 运维内部化
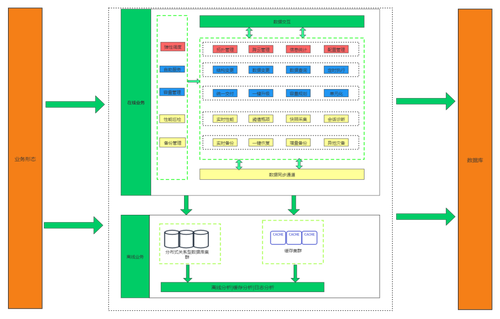
云数据库运维有多种方案,最有效的做法是,实现运维的内部化。即按照业务形态划分业务,比如划分为在线业务和离线业务,不同的业务类型设定不同的成本和SLA标准。在线业务包括弹性调度、自助服务、容量管理、性能巡检和备份管理,一般对时效性和数据准确性要求较高,这部分业务需要保障99.999%的可靠性。离线业务包括离线分析、缓存分析、日志分析,这部分业务通过分布式关系型数据库集群和缓存集群来支撑,一般对时效性要求较低,这部分业务可以提供99.95%的可靠性。同时也可以针对不同的业务性质采购不同的硬盘和设备,实现成本和性能的平衡
3、 IaC基础设施代码化
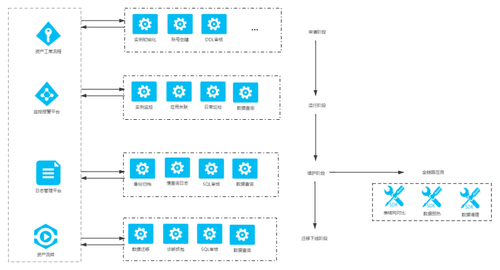
在传统IT业务环境下,IT基础设施管理都是由组织的系统管理员人工完成。他们管理应用程序运行所需的所有硬件和软件。在过去几年,随着数字化转型步伐的加快,IT技术取得了长足的进步,现在除了这种人工管理之外,还有一种替代方法,叫做“基础设施即代码(IaC)”。
不管是日志管理、还是资产流转,所有内容都可以实现自动化,并尽可能地消除所有人工工作。除了要在配置文件中明确所有基础规范,还像其他代码一样,被持续测试、持续集成和部署,检查应用部署到生产之前可能发生的错误或者不一致,确保整个基础设施的高可用性。
基础设施代码化,真正将云数据库运维实现高度自动化,运维人员可更轻松、高效地运行和管理系统。
结论:在云数据库架构改造过程中,可能会遇到的问题有千种,解决方案也不同,在具体实践中,我们可以结合传统运维方式、架构变迁等要求,对数据库架构进行更个性化的部署,而与云原生模式结合,可让开发和运维达到事倍功半的效果。

