Kafka和Redis如何解决流处理挑战
虽然流可以是处理大量数据的有效方式,但它们也有自己的挑战。让我们看看其中的一些。
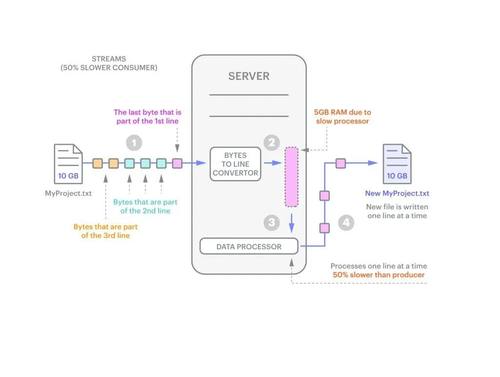
1. 如果消费者无法像制作人创建块那样快速处理块,会发生什么?一个例子:如果消费者比生产者慢50%,会怎么样?如果我们从一个10GB的文件开始,这意味着当生产者处理完所有10GB时,消费者只处理了5GB。剩余的5GB在等待处理时会发生什么情况?突然之间,分配给仍然需要处理的数据的50到100字节必须扩展到5GB。
图1:如果消费者的速度比生产者慢,则需要额外的内存。
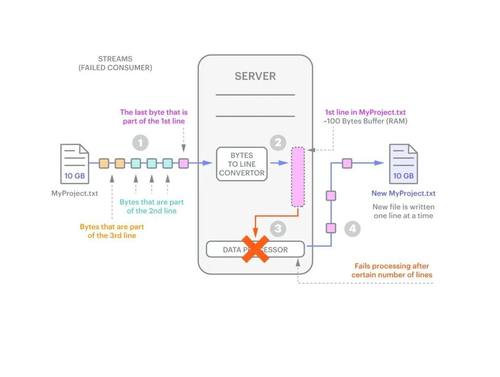
2. 这只是一个噩梦场景。还有其他的。例如,如果消费者在处理一条生产线时突然失效,会发生什么情况?你需要一种跟踪正在处理的行的方法,以及一种允许重新读取该行和随后的所有行的机制。
图2:当消费者失效时。
3. 最后,如果你需要能够处理不同的事件并将其发送给不同的消费者,会发生什么?此外,如果增加额外的复杂性,一个消费者的进程依赖于另一个消费者,那么就有相互依赖的进程,会怎么样?一个真正的风险是,你最终会遇到一个复杂的、紧耦合的、难以管理的单体系统——随着不断添加和删除不同的生产者和消费者,这些需求将不断变化。
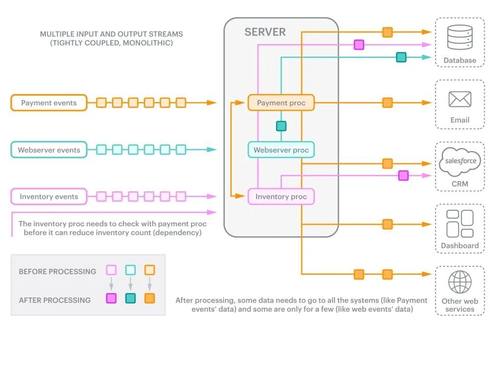
举个例子(图3),假设我们有一家大型零售店,拥有数千台服务器,支持通过网络应用和移动应用进行购物。
假设我们正在处理三种与支付、库存和Web服务器日志相关的数据,每种数据都有一个相应的消费者:“支付处理器”、“库存处理器”和“Web服务器事件处理器”。此外,两个消费者之间存在着重要的相互依赖关系。在处理库存之前,需要先验证付款。最后,每种类型的数据都有不同的目的地。如果是支付事件,则将输出发送到所有系统,如数据库、电子邮件系统、CRM等。如果是Web服务器事件,则仅将其发送到数据库。如果是库存事件,则将其发送到数据库和CRM。
你可以想象,这很快就会变得非常复杂和混乱。这还不包括我们需要为每个消费者处理的慢消费者和容错问题。
图3:紧耦合的挑战,因为有多个生产者和消费者。
当然,所有这些都假设你正在处理一个单体架构,你有一台服务器接收和处理所有事件。你将如何处理微服务架构?在这种情况下,许多小型服务器,即微服务,将处理事件,它们都需要能够相互通信。突然间,你不仅仅有多个生产者和消费者,它们还分散在多个服务器上。
微服务的一个关键好处是,它们解决了根据不断变化的需求扩展特定服务的问题。不幸的是,微服务只解决了一些问题。我们的生产者和消费者之间仍然存在紧耦合,我们保留了库存微服务和支付服务之间的依赖关系。我们在最初的流媒体示例中指出的问题仍然存在:
——我们还没有弄清楚当消费者崩溃时该怎么办。
——我们还没有找到一种管理慢消费者、不会迫使我们大幅扩大缓冲区规模的方法。
——我们还没有办法确保数据不会丢失。
这些只是一些主要挑战。让我们看看如何解决这些问题。
图4:微服务世界中紧耦合的挑战
专用流处理系统
正如我们所看到的,流可以非常适合处理大量数据,但也带来了一系列挑战。为了解决这些挑战,引入了新的专用系统,如Apache Kafka和Redis Streams。在Kafka和Redis流的世界中,服务器不再像流那样位于中心,其他一切都围绕着它们。
数据工程师和数据架构师经常共享这种以流为中心的世界观。当流成为中心时,一切都是流水线型的,这并不奇怪。
图5显示了前面看到的紧耦合示例的直接映射。让我们看看它在高层次上是如何工作的。
——在这里,流和数据(事件)是一等公民,而不是处理它们的系统。
——任何有兴趣发送数据(生产者)、接收数据(消费者)或同时发送和接收数据(生产者和消费者)的系统都连接到流处理系统。
——由于生产者和消费者是解耦的,因此可以随意添加其他消费者或生产者。你可以听任何你想听的事件。这使得它非常适合微服务架构。
——如果消费者速度较慢,则可以通过添加更多消费者来增加消费。
——如果一个消费者依赖于另一个消费者,你可以简单地监听该消费者的输出流,然后进行处理。例如,在上图中,库存服务在处理库存事件之前从库存流(紫色)和支付处理流(橙色)的输出接收事件。这就是解决相互依赖问题的方法。
——流中的数据是持久的(与在数据库中一样)。任何系统都可以随时访问任何数据。如果由于某种原因数据没有被处理,你可以重新处理它。
许多流挑战一度看似艰巨,甚至无法克服,但只要把流放在中心,就可以轻易解决。这就是为什么越来越多的人在他们的数据层中使用Kafka和Redis Streams,这也是为什么数据工程师将流视为世界的中心。

