近年来,Serverless 服务崛起的趋势有目共睹,华为云、AWS、Google 等头部厂商亦纷纷推出 Serverless 产品。Serverless 解放了用户管理和使用复杂云计算资源的双手,犹如第二次工业革命中内燃机汽车的出现解决了马车夫养马的麻烦,也推动高效、稳定的交通工具走进寻常百姓家。如同汽车由内燃机和转向机构等组件构成,Serverless 平台可大致分为资源管理和任务编排,分别致力于提供高效且灵活的算力以及提供方便的用户程序执行方式。在 Serverless 如火如荼的同时,Regionless 也是不可忽视的一个方向。Regionless实际上是华为云提出的概念,即为屏蔽掉云平台 Region 的差异,使得云服务的租户能像“用水和用电”一样随时随地使用云服务。Regionless 的内涵实际上是丰富的,囊括了多个学术研究方向:可以是 geo-distributed cloud,也可以是 multi-cloud,还可以是 cloud-edge computing、 hybrid cloud 等,分别对应不同的能力。恰好,以上都涵盖在华为云分布式云原生服务提供的offerings中。
既然 Serverless 和 Regionless 都是当前云原生发展的重要方向,也都基于同一个云平台资源底座构建,那么两者的发展必然不会是平行的:Serverless 对基础设施进行了标准化,为应用 Regionless 化减少了管理和适配的成本;反过来, Regionless 也是 Serverless 的重要组成,因其可以避免用户感知 Region 间的差异。事实上,早在 2018 年,就有学者关注到 Serverless 对底层差异的屏蔽以及平台提供商数量的快速增长,用户必然会有将 Serverless 业务部署至 Regionless 平台的诉求。在此场景下,用户和平台设计者首当其中考虑到的就是如何充分利用分布在各个区域的计算资源以提升如并发度、时延等性能;同时,使用成本也是用户核心关注点,所以如何充分利用各个厂商的定价差异消减成本,同时也避免与厂商绑定( vendor lock-in )带来潜在的成本问题也需要充分考虑。因此,本文尝试基于分析现有的学术文章,剖析 Serverless 与 Regionless 并存时,在性能提升和成本控制两个方向的现状与挑战,以期抛砖引玉。
性能提升
早在2019年,来自华盛顿大学的研究者已经注意到 Serverless 工作流中的计算任务会涉及存储在不同区位的数据,并且这些数据在对应区位会存在隐私性等问题,因此需要将任务分布到对应数据所在的云平台 Region 进行计算。为此,作者设计了跨 Region 的调度器 GlobalFlow,其核心思想是将工作流中的任务根据对 Region 的依赖关系进行分组,形成子工作流调度到对应 Region,并且在子工作流之间设计 Connector 以便于数据交换。
同样考虑到数据分布的问题,即数据可能分布在不同的区域,而且由于数据隐私性、传输开销等问题,并不能方便地集中在一个区域内处理,中的作者设计了 FaDO 系统用以编排 Serverless 计算任务和数据。如图1所示,FaDO 通过 Backend Server 记录每个区域存储的数据,这些信息则被提供给 Load Balancer 用于将用户请求的计算任务匹配并发送到对应的区域。并且在规则允许范围内, Backend Server 还会将数据备份在不同的区域间进行复制,以配合计算任务的并发度。
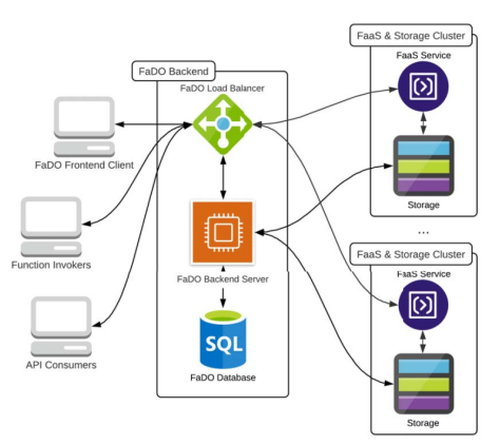
图1 FaDO系统执行流程
除了数据的分布会促使 Serverless 必须接受 Regionless,[6]的作者还观察到:一个云厂商的每个 Region、每个厂商都有不同的并发度限制,并且之间的数据传输时延、存储的数据、每种任务执行的速度等能力均不一致。简单的将应用分发到多云/多 Region 上并不一定能充分提升并发度和整体完成时间。例如图2左侧所示(每种颜色标记的云上并发度限制为 1000,整体应用由 f1-f4 任务构成,也需要运行 1000 次),如果f1在蓝色标识的云资源上运行地快,而 f4 则在橙色上快时,均匀分布则不能利用这个性能差异,而且在橙色云上,f2 和 f3 并不能充分并行(完全并行需要 1200 并发度),进一步影响整体执行时间。在此情况下,如何合理选择任务所使用的云资源(如图2右侧所示),以有效地提升并发度是[6]所研究的重点。为此,中提出了基于三层数学抽象构建的调度器算法 FaaSt。FaaSt 能够合理地将各个任务调度和合适的云厂商 Region上,使得整体的任务完成时间最短。经过在 AWS 和 IBM 云上 4 个 Region 的实验对比,FaaSt 调度后的任务完成时间比单云提升 2.82 倍。
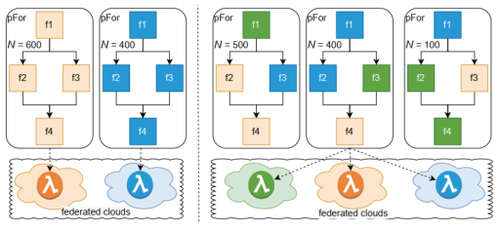
图2 Serverless 并发度示意图
成本控制
为了协助用户选择合适的平台以执行 Serverless 任务,中提出了 MPSC 框架,其核心思想是通过实时监控 Serverless 任务在不同平台上执行的性能,进而选择最具性价比的平台。MPSC 的架构如图3所示,其中 Monitoring Controller 为核心组件,用于协调监控指标采集分析和任务调度。Function Executor 则负责将任务分发至各个平台执行,并采集对应指标。除此之外,还有三个存储模块分别用于储存用户配置、监控指标、用户定义的调度逻辑。
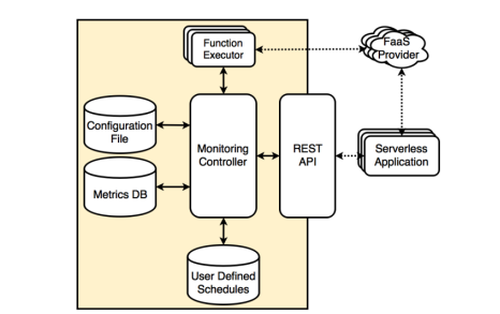
图3 MPSC系统架构
在 Serverless 任务能够合理分发的基础之上,来自 CMU 和 UBC 的学者提出了虚拟 Serverless 提供商( virtual Serverless provider, VSP )的概念。VSP 作为第三方的平台,聚合了各个厂商的 Offerings,为用户提供统一的使用接口,为用户动态选择最具性价比的 Offering。VSP 整体架构如图4 所示,其中核心组件包括:Scheduler 用以根据性能指标和花费计算最合适的云平台;Controller 则负责将应用请求映射到 Scheduler 选择的云平台上;Bridge 用于不同云平台之间任务的交互;Monitor 用以记录调度到不同平台上任务的执行性能;Pre-Load 用于初始化新接入的云平台;而 Cache 则记录了平台执行情况用于后续分析优化。通过在 AWS 和 Google 云平台上的测试,VSP 将 Serverless 任务的吞吐量提升了 1.2-4.2 倍,同时降低了 54% 的云资源使用成本。
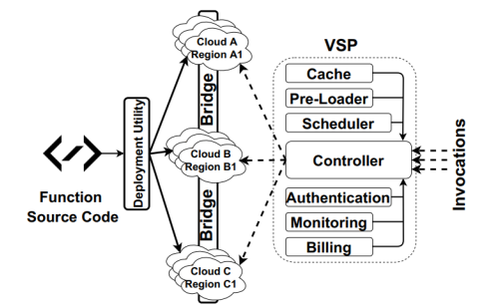
图4 VSP系统架构
进一步地,一个面向多云 Serverless 的开源 library 在中提出了。此 library 主要包括两部分内容(如图5 所示):
1)统一的 API 和 SDK ,用于让用户不需要感知底层差异即可将不同人物部署在不同的云平台上,并且为了降低用户的学习门槛,还提供了基于某一家云平台提供商的 API 和 SDK(如 AWS)拓展出来的、可以将任务部署在其他云平台的 API 和 SDK;2)分析系统( EAS ),用于分析每个任务最适合的云平台,包含用于将任务分发至不同平台的 adaptor、各个平台log的收集器 Cloud Logging Query、各个云厂商的计费模型 Cost Model、接入各个云平台的鉴权组件 Authentication、任务执行的记录 Local Logging 以及性能分析器 Analysis。
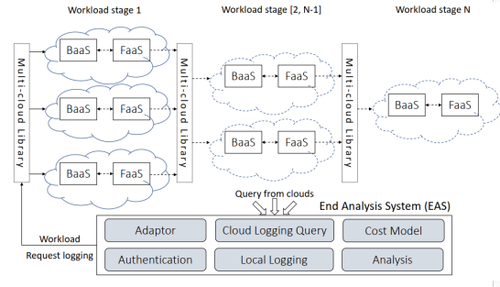
图5 面向多云的 Serverless 开源 library
挑战
从上述现有工作可以看出,当前学术界对于 Regionless 和 Serverless 结合的研究主要面向 geo-distributed cloud 和 multi-cloud 这两个场景下的任务编排系统架构和算法。然而这还远远不足以构建高效、易用的 Regionless 化的 Serverless 平台。类似于 Berkeley 将 Serverless 分成 Backend-as-a-Service (BaaS) 和 Function-as-a-Service (FaaS) 两个层级[1],我们也可以将当前所面临的挑战拆分成底层资源供给以及上层应用管理在 Regionless 场景的 Serverless 化:
底层资源上,我们需要考虑:
1) 通盘考虑每个区域计算资源池的异构性、资源余量、成本等因素的情况下,提供足够的资源同时又不因为 Serverless 极强的弹性而造成过多浪费[9];
2) 从网络角度,在规避部分地理区位间带宽、时间等限制的同时,提供支持动态创删的低性能损失、免配置的网络;
3) 存储上,提供用户无感知的跨 Region 数据预存取与缓存。
应用管理层面上看,需要达到如下:
1) 任务编排上,需要对计算、网络、存储联合进行调度以避免其中某项瓶颈对整体应用的影响;
2) 编程框架上,需要在最小甚至没有侵入式修改的前提下,将用户应用构建或迁移至该平台;
3) 从监控运维角度,需要实现非侵入式、高精度地采集 Serverless 实例的指标,并基于分布在各个区域的监控数据进行智能异常检测、根因分析。
以上也将云厂商和学术界共同打造高效且易用的 Regionless 下 Serverless 平台,共同面临的挑战。

