金融企业:云原生的问题与冲突
在去集中式架构过程中,不但通过用廉价、相对可控的 PC 服务器解决海量规模的计算问题,也推动云原生技术的成熟和广泛应用。随着金融行业的业务与技术不断迭代与发展,分布式云原生技术不但要解决高性能、高可靠、高弹性、高标准的要求,同时还需要围绕安全、风险、效能、容量成本等多个方面进行全公司级的架构设计考量,也就不得不面对如下 8 大问题。
问题 1:何为云原生?何为金融级云原生?
CNCF 最初对云原生定义是一个狭义的理念,更多是聚焦在软件开发层面的新的范式,定义为容器化部署 + 微服务架构 + 持续开发持续集成 +DevOps 这四大特征的“狭义云原生”,核心是面向应用开发者层面。但是随着云计算的不断演进,云原生存储、云原生网络、云原生数据库、云原生大数据、云原生 AI、云原生业务中台等等都走向云原生的统一范畴,所以概念逐渐扩大化,说明“狭义云原生”还是聚焦在开发层面,还是不能完全解决客户的整体架构升级问题,所以形成了“广义云原生”。
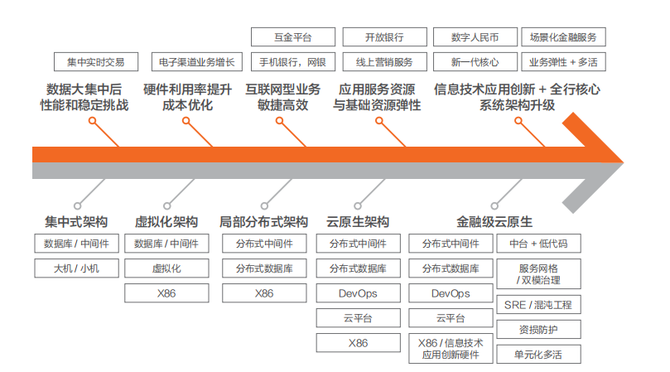
而面对金融行业更加严苛的要求,需要解决不止是开发敏捷的问题,还需要解决架构先进性,将金融对安全合规、交易强一致性、单元化扩展、容灾多活、全链路业务风险管理、运维管理等各方面行业要求与云原生技术进行深度融合,实现对传统集中架构的整体架构升级,发展为一套既符合金融行业标准和要求、同时兼具原生技术架构优势,形成了“金融级云原生架构”。
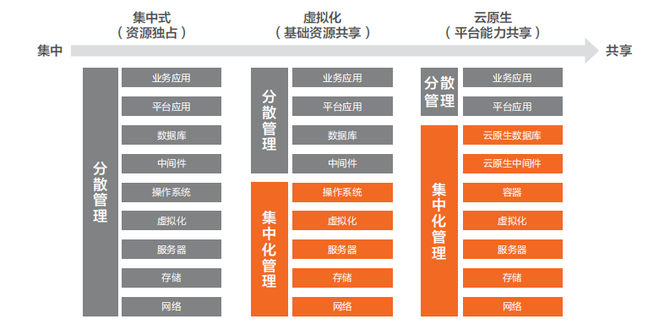
问题 2:云原生对 IT 运维管理的变化何在?
从 IT 架构演进来看,传统集中式架构虽然部署简单,但存在纵向烟囱割裂、横向管理分散的情况,每个层面和每个技术产品都独立分散管理运维。在虚拟化技术成熟后,实现了从底层服务器、存储、网络、虚拟机等层面的集中式统一管理,大幅提升了运维人员的管理半径。而云原生的核心理念是一切资源技术都以池化和服务的方式提供,不再是传统割裂烟囱式的资源供给关系。云原生架构更进一步实现了对 IaaS 资源、PaaS 资源、分布式数据库、分布式中间件、容器、研发工艺等各类技术服务的标准化和统一管理,真正实现了科技层的“车同轨、书同文”,大幅降低了运维复杂性,提高了人均管理对象规模化。
问题 3:云原生体系如何进行开源治理?
以前金融企业想使用云原生的技术或产品,需要花费大量的精力研究一些开源项目,自己做运维和管理,还需要考虑集成、稳定性保障等问题,这样才能建立一个云原生平台。金融机构开始意识到开源软件只能解决水面之上的、显性的、功能性的需求,大量的水面之下的、隐性的、非功能性的需求,开源软件并不具备,但却是金融机构在构建云原生应用时真正需要考虑的。
为了方便开发人员、运维人员更容易地使用云原生技术产品,越来越多的金融机构建立起了一套企业级云原生技术中台和技术标准,从产品集成、运行、监控、运维等多维度进行产品和架构治理,实现有 SLA 保障、有成熟案例、有技术规范、可灰度的云原生技术适配落地。
问题 4:云原生如何与信息技术应用创新结合,实现 1+1>2 ?
自顶向下的完整云原生技术栈代表着今天先进的技术体系,因此在“信息技术应用创新”的技术方案选择中不能只是单纯的硬件思路或者单纯的点对点替换思路,更多应该是用先进的云原生技术架构利用“信息技术应用创新”改造的机会实现全面能力的升级。
“信息技术应用创新”成为金融机构 IT 体系建设中不可忽略的重要因素,在构建云原生体系时,需要考虑这些方面的需求带来的挑战,例如“信息技术应用创新”软硬件供应链稳定性和国产芯片可靠性问题,“信息技术应用创新”势必会导致金融机构面临不同芯片服务器的“碎片化问题”(造成管理复杂性增加、成本增加),如果将每一种类型的芯片集群都单独建云管理,这种多云的资源池割裂和分化,很难被云原生应用进行统一资源调度和使用,无法充分地利用到不同业务的峰值和低谷来进行弹性。除此之外,多朵云还会导致运维复杂,包括部署、升级和扩容等需要单独管理,运维管理成本高,操作体验差。
问题 5:云原生架构对业务安全生产如何应对?
根据“墨菲定律”——“怀疑一切、任何节点失败都会发生!”云原生应用架构设计原则是,将影响安全生产的潜在“黑天鹅”风险作为“常态”。
云原生架构的建议是:允许失败发生,确保每个服务器,每个组件都能够在不影响系统的情况下发生故障并且具备自愈和可替代能力。立即失效(Fail fast and Fail small)是云原生系统一个重要的设计原则,它背后的哲学是既然故障无法避免,问题越及早暴露、应用越容易恢复,进入生产环境的问题就越少。Fail small 的本质在于控制故障的影响范围——爆炸半径,关注点将从如何穷尽系统中的问题转移到如何快速地发现和优雅处理失败。
金融级云原生架构来说技术风险亦是重中之重。任何一笔交易处理的差错背后都有可 能 导 致 不 可 预 计 的 资 金 损 失。需 要 建 立 一 套 专 业 的 技 术 风 险 体 系(SRE,Site Risk Engineering),确保从系统架构平台到风险文化机制,在架构设计、产品开发、变更上线、稳定性评估到故障定位恢复等等环节,都能全生命周期地确保风险质量控制,对任何系统变更作兜底保障。
问题 6:云原生架构对业务连续性如何保证?
云原生的韧性能力代表了当系统所依赖的软硬件组件出现各种异常时,整个系统表现出来的抵御能力,这些异常通常包括硬件故障、硬件资源瓶颈(如 CPU/ 网卡带宽耗尽)、业务流量超出软件设计能力、影响机房工作的故障和灾难、软件 bug、黑客攻击等对业务不可用带来致命影响的因素。韧性从多个维度诠释了系统持续提供业务服务的能力,核心是从云原生架构设计上,整体提升系统的业务连续性,提升系统韧性。
金融级云原生的韧性能力包括:服务异步化能力、重试 / 限流 / 降级 / 熔断 / 反压、主从模式、集群模式、AZ 内的高可用、单元化、跨 Region 容灾、异地多活容灾等。
问题 7:云原生架构对交易一致性如何应对?
人们希望像使用单机系统一样使用分布式系统,因此不可避免的需要面对 “分布式一致性”问题。云原生中微服务中“微”代表了服务颗粒度变小,而金融交易的复杂性又相对较大。所以在云原生系统的数据一致性是一个相对复杂的问题,不同微服务中独立的数据存储,使得维护数据的一致性变得困难。由于分布式微服务系统中的网络错误不可避免,基于 CAP 定理,当出现网络分区时,就需要云原生架构能够在一致性和可用性之间进行平衡。
所以金融级云原生架构规划时,也会遇到金融业务对一致性的挑战,这种一致性不仅体现在业务逻辑上(TCC、SAGA、XA 事务、消息队列等),也更多地需要在数据层面上一致性保障(多节点一致性、多中心一致性)。
问题 8:云原生架构与应用设计与研发有哪些挑战?
使人疲惫的不是远方的高山,而是鞋里的一粒沙子。虽然云原生技术有诸多好处,金融机构往往拥有大量的存量系统,这些存量系统的技术体系往往与云原生技术存在差异,如何对存量系统与新的云原生应用进行集成、治理?微服务的拆分策略如何制定,如何衡量拆分的维度、拆分的标准和拆分的颗粒度?如何建立云原生的可观测体系,实施有效的监控、日志管理和告警,实时监控应用性能、资源使用情况,问题发生时快速定位并解决问题?
这些问题挑战深层次解决,很多金融机构意识到需要云原生技术中台在设计态、研发态、运行态、运维态、容灾态这 5 态进行统一技术规范,能够实现标准贯穿和设计前置,将运维、容灾、安全等后端能力和要求,在设计和研发阶段就进行考虑、设计、前置,用云原生技术来解决后端人力工作量和管理复杂性。

