一、背景
随着微服务架构的流行,越来越多的企业开始将应用程序根据业务领域拆分成多个小型服务,以便更好地管理和维护。在这种架构下,批处理也越来越重要,它可以帮助企业在多个微服务之间同步数据和进行业务处理。
然而,批处理的实现方式和位置不同,会影响到系统的性能和可维护性。在本文中,我们将探讨批处理的实践方案,并提供一些有关在不同层面和场景下使用批处理的建议。
二、 批处理的定义,和数据仓库的职责分工
批处理(Batch processing)通常是指一次处理一批作业(jobs)的计算方式,而非一次只处理一个作业。
很多人对批处理和数据仓库可能有些理解偏差,实际二者的职责有一些不同。批处理主要负责对数据的批量处理,一般包括数据的采集、清洗、加工、计算等工作。批处理的主要目标是提高数据处理的效率和准确性,为数据分析和业务决策提供支持。
数据仓库则是一个面向主题的、集成的、反映历史变化的、可供查询和分析的数据集合。数据仓库主要用于支持企业的数据分析和决策,包括数据的存储、管理、检索、分析和报告等功能。
因此,批处理和数据仓库虽然都涉及到数据处理和管理,但其职责和目标是不同的。批处理主要是针对数据的加工和处理,而数据仓库则主要是为了提供数据分析和决策支持。
通常情况下,批处理会将处理后的数据存储到数据仓库中,以供后续的数据分析和决策使用。 但是批处理可以在数据仓库中进行,数据仓库中的ETL(Extract-Transform-Load)过程本质上就是一种批处理。ETL通常用于将不同的数据源中的数据进行提取、转换和加载,以便于进行数据分析和报表生成等操作。
因此,在一些场景下,可以将批处理的逻辑直接放在数据仓库中实现,以实现数据的批量处理和转换。不过需要注意的是,数据仓库的主要职责是支持数据分析和报表生成,如果批处理逻辑过于复杂或者需要处理的数据量过大,可能会影响数据仓库的性能和稳定性,因此需要进行权衡和优化。
三、批处理的位置和角色
批处理在微服务架构中通常被用于数据同步和业务处理。对于简单的数据同步任务,可以将其交给数据同步工具完成,这种方式可以减少对批处理的依赖,并且使得数据同步更加稳定可靠。对于复杂的业务处理任务,批处理通常需要进行一定的业务处理。
进程间架构批处理的位置在微服务架构中,批处理可以放置在不同的位置。最常见的做法是将批处理作为单独的服务,放在微服务架构的最上层,也就是渠道层,场景层,中台层的上层,通过调用其他微服务的API实现业务逻辑。

在微服务架构中,批处理可以放置在不同的层次,例如渠道层、场景层、业务中台等,以实现不同的业务需求和性能要求。
首先,批处理可以放置在渠道层。在这种情况下,批处理可以针对不同的渠道(例如手机、Web页面、微信小程序等)进行不同的数据处理。这种方式可以将不同渠道的数据处理分离出来,使得代码更加清晰简洁。但是,由于每个渠道的数据处理需求和性能要求可能不同,因此需要根据实际情况进行具体的设计和实现。
其次,批处理可以放置在场景层。在这种情况下,批处理可以针对不同的业务场景进行不同的数据处理。例如,在电商网站中,批处理可以针对不同的商品分类进行数据处理,例如处理促销商品、热销商品等。这种方式可以将不同业务场景的数据处理分离出来,使得代码更加清晰简洁。但是,由于每个业务场景的数据处理需求和性能要求可能不同,因此需要根据实际情况进行具体的设计和实现。
第三,批处理可以放置在业务中台。在这种情况下,批处理可以针对不同的业务能力进行不同的数据处理。例如,在电商网站中,批处理可以针对不同的业务能力进行数据处理,例如订单处理、库存处理等。这种方式可以将不同业务能力的数据处理分离出来,使得代码更加清晰简洁。但是,由于每个业务能力的数据处理需求和性能要求可能不同,因此需要根据实际情况进行具体的设计和实现。
进程内架构批处理的位置
另一种实现方式是将批处理集成到业务微服务中,这样可以减少网络通信的开销并增加性能,但是维护成本较高,难以统一。批处理可以属于DDD分层架构中的应用层,原因如下:
批处理是一种应用程序,负责对系统中的数据进行批量处理,属于业务逻辑的一部分。
在DDD分层架构中,应用层是负责处理业务逻辑的层,它位于领域层之上,负责协调各个领域对象,实现具体业务逻辑,并向上层(用户界面或接口层)提供服务。
批处理通常需要调用多个领域对象,进行业务处理,因此应该放在应用层中实现。
批处理通常需要访问外部数据源,如数据库、文件系统等,也可以通过应用层提供的接口进行访问和处理。
因此,批处理作为一种业务逻辑处理程序,需要调用多个领域对象和访问外部数据源,因此它应该属于DDD分层架构中的应用层。
但是如果批处理主要用于数据清洗和转换,则可以放置在Infrastructure层。架构如下:
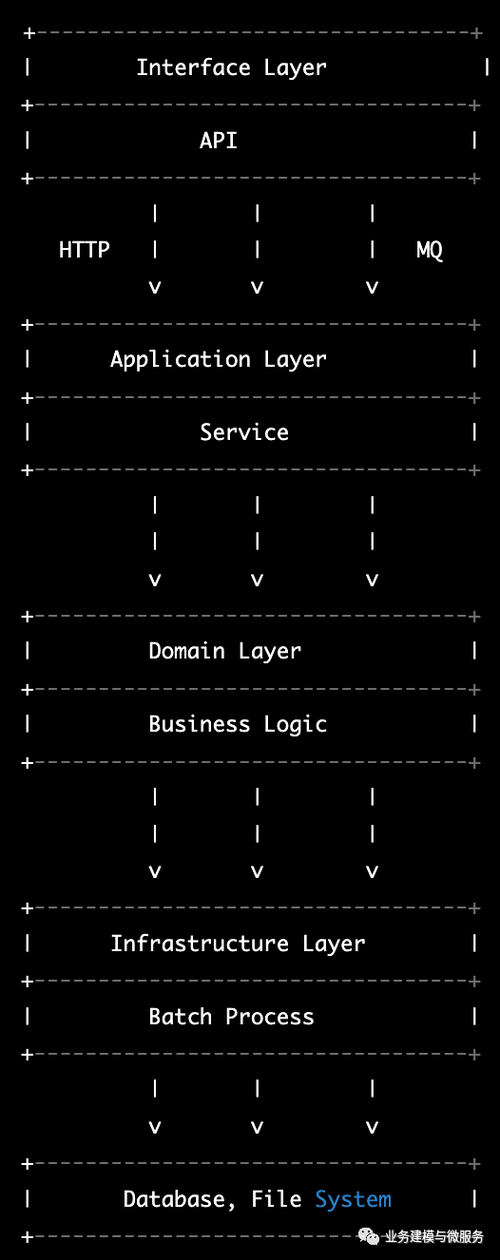
总之,在进行决策时,需要考虑系统的性能、可维护性和扩展性等因素。
如果批处理需要访问多个微服务的数据,那么将其作为单独的服务是比较合适的,而如果批处理只需要访问单个微服务的数据,那么将其集成到该微服务中更为合适。在设计批处理时,需要考虑到数据的来源和去向。
如果批处理需要访问不同的微服务数据库,可以考虑使用分布式事务或者分布式缓存等技术来保证数据的一致性和可靠性。
同时,批处理的性能也需要考虑。如果需要处理大量数据或者处理时间较长,可以考虑使用分布式计算技术,例如MapReduce等。
最后,对于批处理的维护和管理,可以根据具体情况进行设计。如果不同层次的批处理需要访问不同的数据库,可以将批处理的维护和管理交给相应的团队负责。
四、批处理的访问方式
如果批处理需要访问多个微服务的数据,那么最好的方式是使用事件驱动架构。在这种架构下,批处理通过订阅各个微服务的事件,以最小的延迟同步数据。这种方式可以减少网络通信的开销,提高性能,并且使得各个微服务之间的解耦更加明显。
如果事件驱动架构比较复杂的话,可以考虑通过不同微服务的接口访问对应微服务的数据进行批量处理。
另一种方式是直接访问各个微服务的数据库,这种方式的优点是实现简单,但是存在一定的安全风险,因为批处理可能会访问其他微服务的敏感数据。因此,需要进行严格的访问控制,确保只有合法的操作可以执行。
五、如何选择合适的批处理架构
当我们面对需要进行批量处理的业务场景时,选择合适的批处理架构至关重要。在进行选择时,需要考虑多个因素,包括业务复杂度、数据一致性、安全性、性能、可靠性和可扩展性等方面。下面我们将从这些方面来探讨如何选择合适的批处理架构。
业务复杂度
业务复杂度是选择批处理架构时需要优先考虑的因素之一。如果业务比较简单,可以将批处理作为各个微服务中的一个模块进行处理。但如果业务比较复杂,单纯地将批处理作为模块放入微服务中可能会导致模块之间的耦合度过高,影响后续的维护和扩展。此时可以考虑将批处理作为一个独立的服务来进行处理,从而降低模块之间的耦合度。
数据一致性
数据一致性也是选择批处理架构时需要考虑的重要因素。如果批处理需要访问多个微服务的数据库,可能会出现数据一致性的问题。此时可以考虑使用分布式事务来保证数据一致性,或者将批处理放在业务中台层,由业务中台统一管理数据库访问。
安全性
安全性也是选择批处理架构时需要考虑的重要因素之一。如果批处理需要访问敏感数据,需要考虑如何保证数据的安全性。可以采用数据加密、访问控制等措施来保证数据的安全性。
性能
性能是选择批处理架构时需要考虑的重要因素之一。如果批处理需要处理大量数据,需要考虑如何提高处理性能。可以采用分布式批处理、多线程等方式来提高处理性能。
可靠性
可靠性也是选择批处理架构时需要考虑的重要因素之一。如果批处理出现问题,可能会影响业务的正常运行。可以采用重试机制、异常处理等方式来提高批处理的可靠性。
可扩展性
可扩展性也是选择批处理架构时需要考虑的重要因素之一。如果业务需要不断扩展,需要考虑如何扩展批处理的能力。可以采用分布式架构、云计算等方式来提高批处理的可扩展性。

需要注意的是,这个表格只是一个简单的参考,具体选择方式还需要根据具体情况进行综合考虑,包括但不限于业务需求、系统性能、安全性要求、可靠性要求和可扩展性要求等。
六、总结
在微服务架构中,批处理是一种常见的数据处理方式,可以用于数据清洗、数据迁移、数据分析等任务。在决定将批处理放在哪一层时,需要考虑业务复杂性、性能需求、数据访问方式等因素。
通常情况下,建议将批处理放在中台层,以便共享中台的企业级能力和数据。不过,如果不同层有不同的团队负责,那么可以考虑在各个层级上都建立批处理。
同时,批处理的实现方式也需要结合业务情况进行选择,可以是在批处理服务中进行业务逻辑处理,也可以将业务逻辑处理放在各个微服务中。总之,在微服务架构中,合理利用批处理可以提高数据处理效率,从而更好地支持业务发展。

