AI 智能时代,开发者需要一个真正的向量数据库吗?
答案很简单,这取决于开发者的应用场景。举个例子,晚饭选择去一家五星级餐厅用餐或是是快餐店,往往和你的胃口和期望有关。
如果只是想简单解决一顿饭,一家快餐店就能满足你。同理,如果想为自己的个人网站快速搭建一个问答机器人,或者为相册里的十万张照片建立一个索引,你可以选择最熟悉和便捷的方法,无论是使用免费的向量检索云服务,或者安装基于 PostgreSQL 的开源向量检索插件 PG Vector,抑或是在本地通过 pip 安装 Faiss、HNSW、Annoy 等开源向量检索库,都是不错的选择。
然而,如果我们的目标是一个品质高端的晚宴,大概率会选择一个五星级餐厅。这就好像我们想要构建一个企业级的向量检索应用,数据量超过千万级,要求延迟在 10ms 以下,需要使用高级功能如标量过滤、动态架构、多租户、实时更新/删除、批量导入等。不止如此,我们甚至希望能够在短短十分钟内快速构建一个可用的 Demo……这就不得不借助原生向量数据库的能力和优势了,它就像五星级餐厅一般,不仅可以满足你的基本需求,更是质量和服务的保证。
什么是向量检索?
向量数据库具有快速计算向量相似度的优势,能在 N 个向量中找出与目标向量在高维空间中最相似的前 K 个向量。然而,这种能力并非仅有向量数据库所具备。例如,我们可以通过使用 Python 的 NumPy 库,用不到 20 行代码就能实现最近邻算法。
我们可以试着生成 100 个 2 维向量,然后找出与向量[0.5,0.5]最近的邻居。
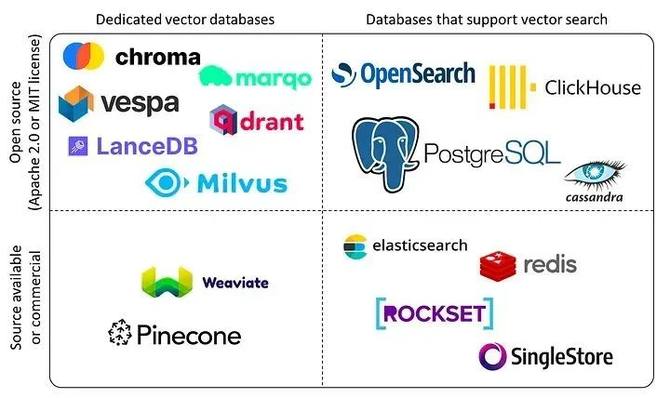
向量数据库的底层技术
向量数据库底层技术已经被研究多年,有以下3点关键技术:
第一、基于嵌入的检索( Embedding-Based Retrieval, EBR)已经被研究了十多年。
第二、相似性搜索(Similarity Search)持续了长达半个世纪。
第三、NumPy 或其他 FAISS 向量搜索库也可以用来构建向量搜索系统。
为什么最近向量数据库变成如此火热,推动力就是 LLM 大语言模型。推动从算法向应用系统转变的,是新的「数据密集型应用程序」 = 大量的「非结构化」数据存储 + 「可靠、安全、快速和可伸缩」的查询处理能力。
传统数据库以行和列的表格式存储数据,并且基于精确匹配或预定义条件搜索精确的数据。
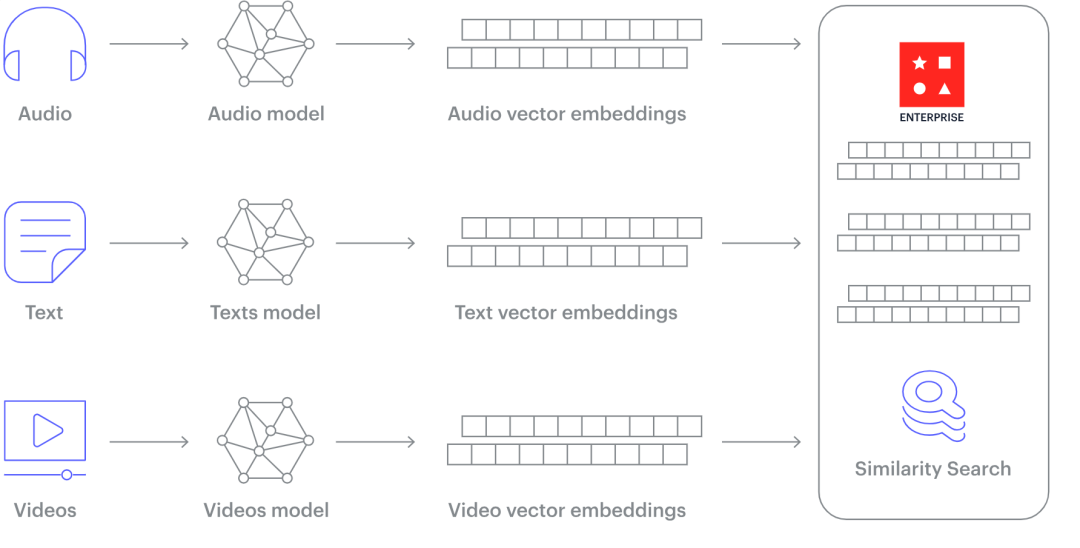
然而,大量业务数据是非结构化的,以文本、图像、音频、视频或其他格式存储,这给传统数据库带来了挑战。
Vector Database 存储的“向量数据”,通常是通过对这些非结构化数据使用某种转换或嵌入函数来生成的。
![]()

