大数据湖仓一体架构对分布式存储有哪些技术需求?
分布式存储作为湖仓一体技术的重要支撑,也随着湖仓一体技术在不断演进。作为存储系统,除了提供原有的数据共享访问、灵活扩展、快照、克隆、容灾等功能外,还需要为湖仓一体的上层应用提供特定的服务能力。
随着云计算、大数据的快速发展,数据体量急速增长,与之相应,数据管理技术也在快速演进,其中,就包括湖仓一体( Lakehouse )技术。在咨询公司 Gartner 发布的“数据管理技术成熟度曲线”中,湖仓一体技术处于高速发展阶段。
按照云计算提供商亚马逊的定义,湖仓一体是一种新的数据管理模式,它将数据仓库和数据湖两者之间的差异进行融合,并将数据仓库构建在数据湖上,从而有效简化了企业数据的基础架构,提升数据存储弹性和质量的同时还能降低成本,减小数据冗余。
湖仓一体架构中所包含的数据既有“仓里”的结构化数据,更多的则是“湖里”的半结构化和非结构化数据。数据湖仓一体架构主要一点是实现“湖里”和“仓里”的数据能够无缝打通,对数据仓库的弹性和数据湖的灵活性进行有效集成,让湖中的数据可以”流到“数据仓中,并能直接进行数据调用;而数据仓中的数据也可以保存于数据湖中,供未来数据挖掘使用。在该架构中,主要将数据湖作为中央存储库,将机器学习、数据仓库、日志分析、大数据等技术进行整合,形成一套数据服务环,更好地分析、整合数据,让数据仓库和数据湖中的数据可以自由流动,用户可以更便捷地调取其中的数据,让数据“入湖”、“出湖”更为便捷。
湖仓一体技术不是凭空产生的,它是在数据仓库和数据湖的基础上发展而来的。从数据管理架构的发展来看,湖仓一体技术的发展可分为三个阶段。第一阶段是上世纪 80 年代开始的“数据仓库”阶段,第二阶段是 2012 年伴随着大数据发展普及而产生的“数据湖”技术,第三阶段就是近年来开始的数据湖与数据仓库的融合趋势,即“湖仓一体”。
近年来,各大云计算厂商以及众多的 Startup 公司纷纷推出自己的湖仓一体技术方案。典型国外厂商如 Amazon 的 Redshift Spectrum,Microsoft 的 Asure Synapse Analytics,Google 的Dataplex,Databrics 的 Lakehouse Platform 等;国内厂商如阿里云的 Maxcompute,腾讯云的云原生数据湖,华为云的 Fusion Insight 等。
分布式存储作为湖仓一体技术的重要支撑,也随着湖仓一体技术在不断演进。作为存储系统,除了提供原有的数据共享访问、灵活扩展、快照、克隆、容灾等功能外,还需要为湖仓一体的上层应用提供特定的服务能力。图示如下:
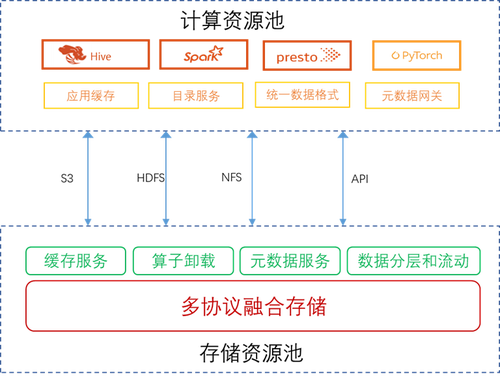
存储资源池首先要提供的就是多协议融合存储能力。
湖仓一体架构中的数据是异构、多源、海量的。既包含以 S3 写入的对象存储数据、也包括以 HDFS/NFS/CIFS/FTP 等写入的文件数据 , 还包含以 iSCSI/FC 等写入的块存储数据,以及特定私有 API 写入的存储数据。要使湖仓内数据高效流动,就必须实现多种存储访问协议间的 IO 语义互通,在元数据的层面打通不同存储协议间的壁垒。这样,在不同的协议访问同一份数据时,就不再需要数据转换和拷贝,从而大幅提升数据存储、转换、处理效率。
除了多协议融合的基本能力,存储资源池还需要提供缓存服务、算子卸载、元数据服务、数据分层和流动等高级能力。
缓存服务
从整体架构上说,要达到良好的数据加速效果,缓存服务需要在计算层面和数据存储层面进行统一考虑。在计算层面,首先要具备本地的应用缓存能力。基于特定的应用,基于局部性原理(时间局部性和空间局部性),实现数据和元数据的缓存。基于应用的缓存层,一方面可以提升数据访问速度,还可以提升数据使用效率(避免对于远端数据(其他 AZ 的数据,甚至第三方云平台数据)的重复访问)。在存储层面,基于本地数据的访问热度提供缓存服务。这个缓存服务既可以以缓存池的形式,也可以以分级存储热数据层的形式提供。不管哪种形式,都可以为本地或者远端提供低时延、高吞吐的访问性能。对于写缓存,目前已经有较为成熟的 IO 聚合方法;对于读缓存,目前一些厂商在探索利用 AI 方法进行智能预读提升命中率。
算子卸载
算子卸载主要是利用存储系统的算力以及数据布局特点对数据进行高效的处理,实现访问加速。一个熟知的算子卸载的例子是 VMWare 的 VAAI 接口。目前已有的算子卸载应用包括视频处理的流直存、数据库的 SQL 查询加速、 KV 访问加速等。
元数据服务
提供元数据的多维检索、标记、批量变换等操作。这里的元数据是指从存储协议( S3/NFS/HDFS 等)角度看的元数据,非应用角度元数据。在湖仓上层应用处理过程中,往往涉及对海量小文件元数据的查询,由存储层提供特定的元数据访问引擎,可以大幅提升数据处理效率。
数据分层和流动
这里的数据分层和流动既包含本地数据的分层和流动,也包含不同数据中心间的数据分层和流动。数据的访问和处理往往具有一定的时效性特征,为了取得良好的性价比,数据会存储在 SSD、HDD、磁带、蓝光等不同介质中;为了保证的更高可靠性,还可能在多个数据中心保存冗余数据。此时,全局优化的数据保存策略以及智能的数据调度算法可以助力数据分层和流动效率的提升。

