基于 Hologres+Flink 的曹操出行实时数仓建设
摘要:本文整理自曹操出行实时计算负责人林震基于 Hologres+Flink 的曹操出行实时数仓建设的分享,内容主要分为以下六部分:
1. 曹操出行业务背景介绍
2. 曹操出行业务痛点分析 3. Hologres+Flink 构建企业级实时数仓 4. 曹操出行实时数仓实践 5. 曹操出行业务成果分析 6. 未来展望
01
曹操出行业务背景介绍
曹操出行创立于 2015 年 5 月 21 日,是吉利控股集团布局“新能源汽车共享生态”的战略性投资业务,以“科技重塑绿色共享出行”为使命,将全球领先的互联网、车联网、自动驾驶技术以及新能源科技创新应用于共享出行领域,以“用心服务国民出行”为品牌主张,致力于打造服务口碑最好的出行品牌。
作为一家互联网出行平台,曹操主要提供了网约车、顺风车和专车等出行服务。其中,打车是其核心业务之一。整体业务过程大致如下: 首先,用户在我们的平台上下单,然后曹操平台会给司机进行订单的派发,司机接到订单后,会进行履约服务。结束一次订单服务后,乘客会在平台上进行支付。
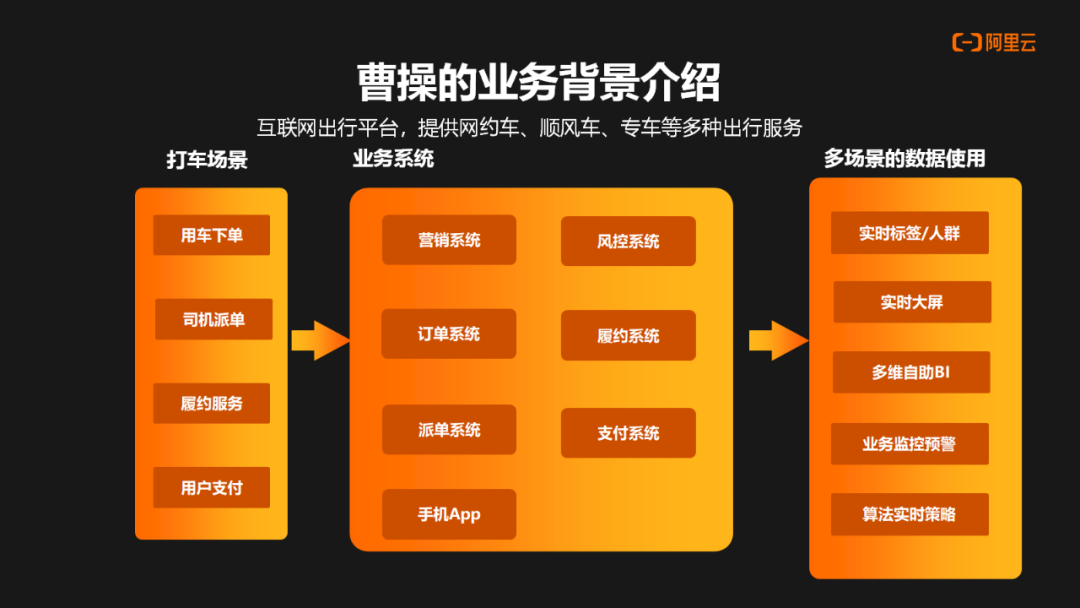
在整个流程中,涉及到的数据将会在我们的业务系统中流转,主要包括有营销、订单、派单、风控、支付、履约这些系统。这些系统产生的数据将存储在 RDS 中,并进一步流入实时数仓中以进行分析和处理。最终数据会进入到不同的使用场景中,比如实时的标签,实时大屏、多维 BI 分析,还有实时业务监控以及实时算法决策。
02
曹操出行业务痛点分析
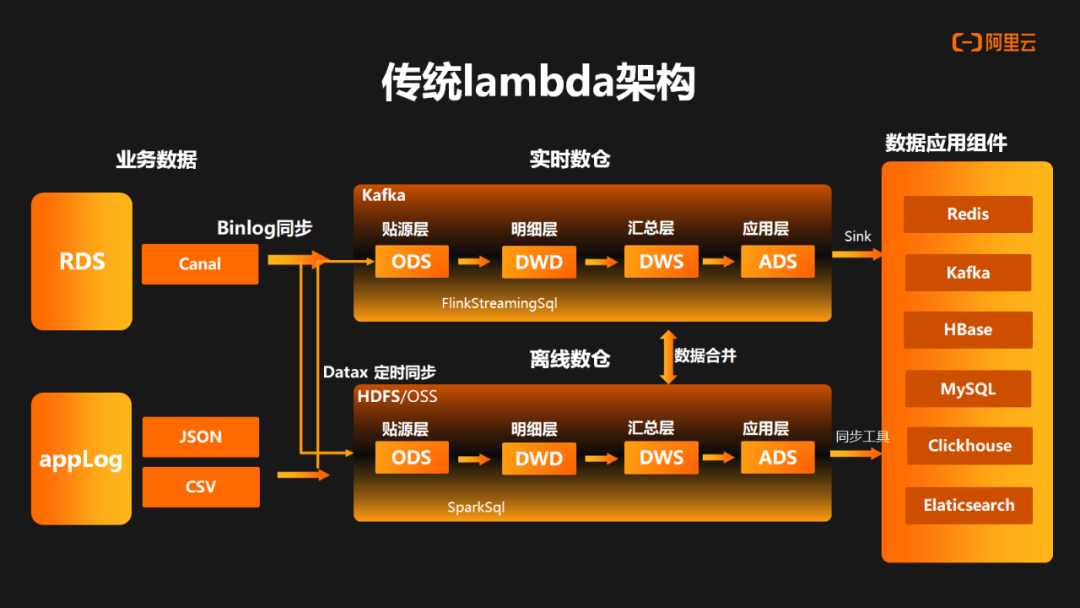
上图是一个传统 lambda 架构,在这个架构中主要会分做实时数据流和离线数据流。在实时链路中,业务数据是存放在 RDS 中,并通过 Binlog 以 Canal 同步的方式进入 Kafka ,同时应用的日志数据也会通过实时采集的方式进入到 Kafka 。数据准备工作完成后,在 Kafka 中构建实时数据仓库。整个实时数仓基于数仓分层理念进行构建的,主要包括原始数据层(ODS)、数据明细层(DWD)、数据汇总层(DWS)和应用数据层(ADS)。这些层次通过 Flink Streaming SQL 进行串联,实现数据的流转和处理。
在离线链路中,数据主要是通过 DataX 定时同步任务将 RDS 中的数据同步到 HDFS 。同时应用的日志会通过定时任务同步到 HDFS ,整个离线数仓以 Spark Sql 定时调度任务去逐层执行。数据在离线数仓中会以不同的数据域去组织满足不同粒度的数据计算,最终数据会通过 Flink Sink 以及离线同步工具写到不同的数据应用组件中。同时,为了保证某些应用场景中数据的一致性,可能需要对离线和实时两条链路的数据进行合并处理和加工。

基于曹操出行数据生产成本和研发诉求,针对传统 lambda 架构中可以看到一些问题:
为了适配不同应用场景,我们在架构中使用了非常丰富的数据组件。
研发成本非常高,不仅在实时链路中进行研发和处理,而且还需额外研发一套离线的数据链路。
运维效率较低,由于整个实时数仓是构建在 Kafka 上的,因此在数据探查以及进行数据订正就会变得非常困难。
资源成本较大,主要体现在几方面:组件多,需要专门安排人员进行运维和管理;一些需要精准一致性的场景需求,需在两个数据链路中做数据的同步和合并计算;在某些计算场景中,需要 Flink 维护大状态进行处理,也造成额外性能问题和资源的浪费。
另外从公司开发者使用的角度,我们对实时数仓提出了以下几点诉求:
统一的组件来满足不同数据应用场景。
复杂的实时数据链路中保障高效的数据订正。
能克服在 Flink 中一些大状态下的技术难点。
03
Hologres+Flink 构建企业级实时数仓
1. Hologres 能力分析
曹操出行作为 Hologres 的深度用户,在前期调研与测试阶段,我们对 Hologres 的相关能力做了比较详细的分析,主要有以下优势:
1.1 业务场景能力丰富
具备 OLAP 分析能力
具备高并发点查能力
具备半结构化日志分析能力
具备基于 PostGIS 的扩展能力,支持空间地理信息信息数据的分析与使用,对于曹操出行的业务属性来说非常重要。
1.2 一站式实时开发能力
契合数仓分层结构理念(可以像离线数仓一样去构建分层体系,数据实时流动,实时存储)
FlinkStreaming 生态高度融合 (Flink CDC 组件集成,Flink Catalog 集成)
统一的 Ad-hoc 能力,能以外表加载离线数仓中数据进行湖仓加速和联邦分析
1.3 解决的痛点问题
全链路低时延
多流 Join 场景很好的提供数据打宽的能力,支持主键模型和行级,局部字段更新的能力
CountDistinct 大状态精确去重场景的支持
2. Hologres 支持高并发更新

Hologres 的存储架构基于分布式存储系统,并在其上构建了存储引擎。在底层,Hologres 使用了分布式存储系统来管理数据的存储和分布。在此之上,存储引擎包括一些关键组件,如 Block Cache、Shard ,每个 Shard 中包含了多个 Tablet 和 Write-Ahead Log(WAL)。
市面上主流的数据湖产品通常采用 LSM(Log-Structured Merge)架构。
主流数据主键模型更新模式有 Copy On Write 和 Merge On Read,这两种场景都有各自的问题:
Copy OnWrite 具有写放大的问题,数据的延迟会比较高。
Merge OnRead(读时合并)模式在读取数据时需要进行大量的数据合并操作,因此读取性能可能较差。
在 Hologres 中,行存使用 Merge On Read 方式,列存主要基于 Merge On Write。
下面主要介绍下在基于 Merge On Write 这种模式时,一条数据在进入 Hologres 中,它首先到达 WAL Manager(Write-Ahead Log 管理器),同时也会进入到 Memtable(内存表)。在 Memtable 中,主要存储三类数据:数据文件、删除标志文件(例如基于 RoaringBitmap 的文件)和索引文件。当 Memtable 数据积累到一定阶段后,会生成不可变的 Memtable,并通过异步线程定期将其刷新(flush)到 Data File(数据文件)中。通过这种架构,Hologres 能够兼顾行存和列存的优势,并通过适当的数据合并策略来提高性能和存储效率。
3. Hologres Binlog 支持

在 Hologres 中 Binlog 也是一种物理表,其跟原表的主要区别是内置的几种自身结构,包含自身递增序列,数据修改类型以及数据修改时间,Binlog 本质上也是分 shard 进行存储,所以也为一种分布式表,并且在 WAL 之前生成,因此在数据上可以与原表保证强一致性。
其次 Hologres Binlog 修改类型也还原了 Flink 中四种 RowKind 类型。在数据更新过程中会产生两条更新记录(update_before,update_after),并且保证了更新记录是一个连续的存储。右边展示中,写入一个数据一个pk1,然后再写入一个 pk2 数据,pk2 的数据再做一次更新,那么在 Binlog 中它会产生4条数据结果。
4. Hologres 数据模型介绍

Hologres 主要分做行存引擎以及列存引擎,同时也支持行列共存场景。
在聚合场景中主要是用到列存的引擎,适合 OLAP 场景,复杂查询,统计以及关联等场景。同时也提供了非常丰富的索引,包括有:聚簇索引,位图索引,字典,以及基于时间序列的范围索引。
在 KV 场景中主要是用到行存的引擎,主要支持高并发组件查询。包括在 Flink中做维表反查也是非常适合。
在订阅场景中主要是用到行存的引擎,主要在表属性中进行声明,比如说 Binlog 是否开启,Binlog 的 TTL。在订阅方的话,Hologres 支持 CDC 以及非 CDC 的模式。
在日志场景中针对聚合场景,主要是支持 JsonB 数据类型。JsonB 数据的写入过程中,Hologres 能够将其自动地平铺成列式的存储结构,同时它可以自动对数据内容做解析,对数据类型做泛化处理,数据格式的对齐,非常适合这种非稀疏场景,因此给聚合场景提供了分析的灵活性。
04
曹操出行实时数仓实践
1. 实时数仓架构设计
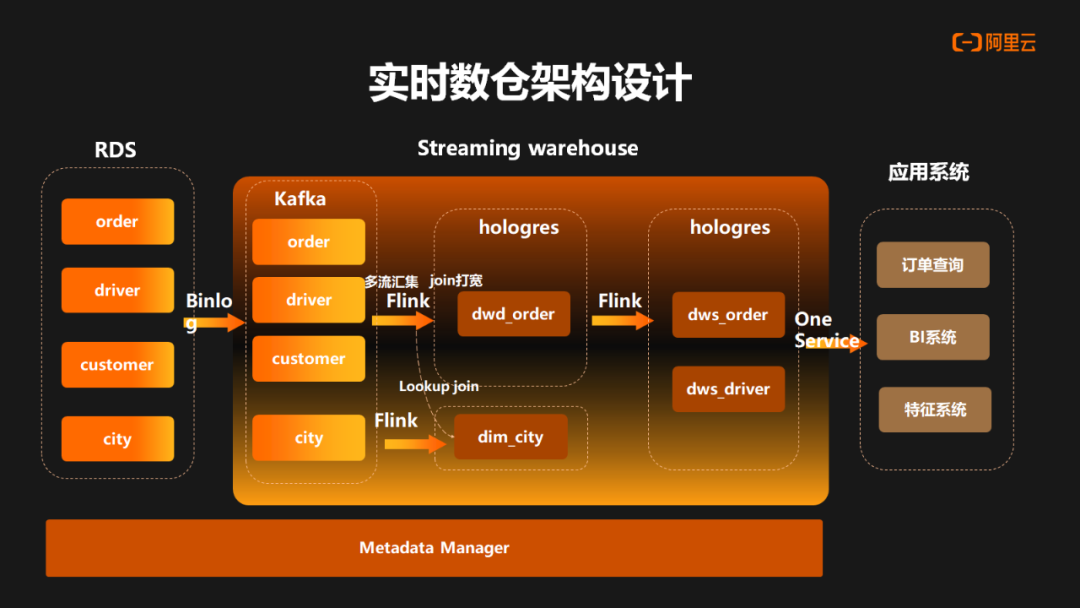
基于前面 Hologres 的能力介绍,接下来是对于曹操内部实时数仓的架构设计,最左边是 RDS 数据库,最右边是应用系统,最下边为元数据管理,中间是实时数仓的部分。数据通过 Binlog 进入到 Kafka 的 ODS 层之后,首先通过 Flink 写入到 Hologres 里的 DIM 层,然后再通过 Flink 做 ODS 的多流汇聚,写入到 Hologres 的 DWD 层。在 DWD 中可以做宽表打宽的实现。再下一层,通过 Hologres Binlog的订阅的方式,进入到 Flink 进行处理加工再写入到 Hologres 的 DWS 层。完成实时数仓分层建设后,再统一通过 OneService 的统一查询服务对外提供服务。
2. dwd 宽表构建实践

接下来介绍一下 Hologres dwd 宽表层的一个构建实践。基于之前提到的 Hologres 列更新能力,能够很好实现宽表 Join 能力。在整个生产过程中,还需重点关注维表的应用场景,其应用场景包含几种情况:一种是维表是不变的,或者缓慢的变化,另一种是维表频繁变化的。为了保障数据最终的一致,通常的设计是像离线的方式去构建一个维表拉链的数据,通过用过 Start Time 和 End Time 的方式去存储维度状态有效的一个周期。
其次需要关注维表延迟问题。在实际生产过程中,维表链路与主表的链路通常是异步的,可能会出现维表延迟导致主表关联数据为空或关联到过时的维度状态。为处理这种情况,需要在 Hologres 中实施维度缺失记录的过滤,并采取补偿机制进行维度补偿处理。同时,还需要定时调度进行维度字段和维表对比检查,以增量方式修正不一致的维度状态。
3. 聚合计算场景优化

接下来是我们对聚合场景的优化,针对许多预聚合计算场景,我们将其统一收敛到 Rollup 计算模型中,主要解决以下问题:
· 在 Flink 聚合场景中经常会出现状态兼容性的问题
· 整个数据的复用性非常差,研发人员收到新的需求,例如新的指标或者新增维度粒度时,为了不影响生产数据的稳定性,新增需求需要构建新任务,导致任务管理混乱。
因此曹操出行主要进行了两点优化:
· 构建 MapSumAgg 算子,MapSum 主要通过对 SumAgg 算子做了重新设计,使之能够支持 Map 内部结构的求和逻辑
· 对 Grouping Sets 进行动态配置化,这样 Grouping Sets 动态增加维度粒度,使整个任务在不重启的情况下也能自动去做自适应
结合这两点,把已有的指标放入 map 结构中进行封装,这样在不改变原有的算子状态,也可以得到很好的处理。在下游中可以针对不同维度组合,指标集合做好选择,然后由同步工具做实时的数据路由,为下游提供服务。
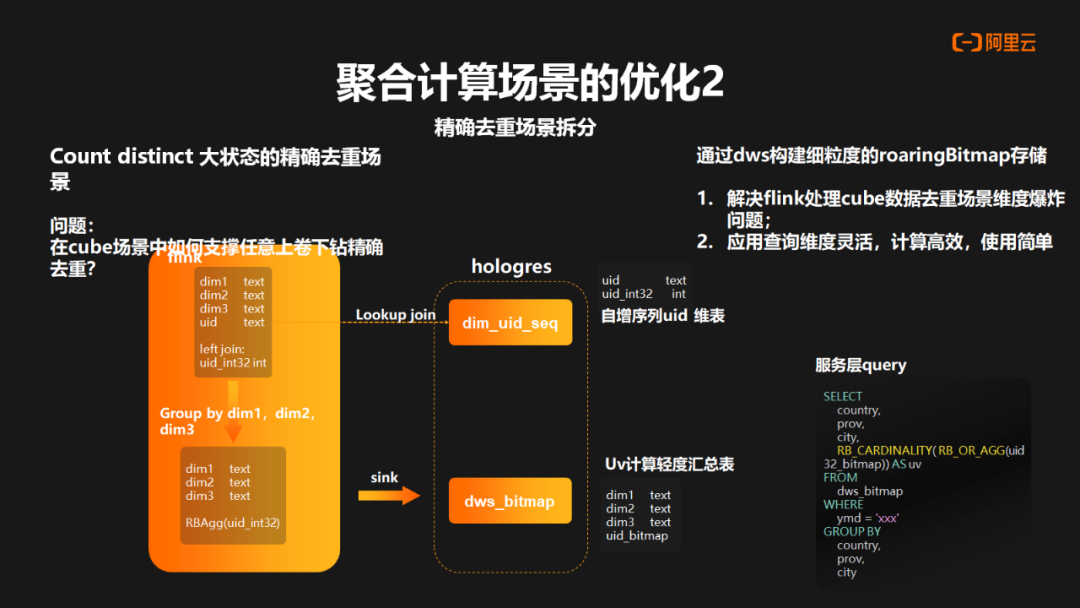
对于第二个聚合场景的优化,是对精确去重场景的拆分。在前面例子中,我们把 Count Distinct 的精确去重做了剥离,主要解决两个问题:
· 维度爆炸问题。在 Flink 的回撤机制下使用精确去重时,需要存储全量状态。然而,在 Cube 场景中,这种状态的爆炸式增长对于 Flink 的可扩展性是一个挑战。
· 查询灵活性问题。解决思路是通过 Hologres 去构建细粒度的 RoaringBitmap 存储方案。
具体流程如下:首先, 在 Hologres 中构建自身序列的 UID 维表,然后在主表中通过反差逻辑将 UID 的自身序列反查出来。接下来,在 Flink 中进行 Group by 操作,并进行聚合计算,得出 RoaringBitmap 的结果。最后,将结果写入 Hologres 的 DWS 层,形成轻度汇总表用于 UV 计算。这种方案既能解决应用端在灵活维度查询时的高效性需求,又能解决 Flink 中维度爆炸的问题。
4. 链路中吞吐能力调优
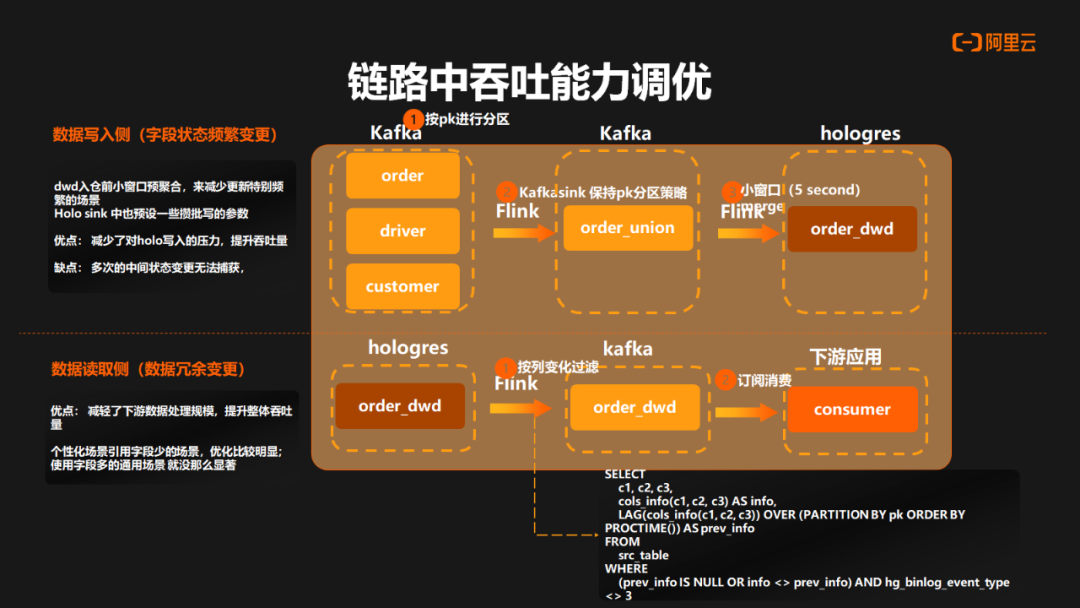
整个流链路中吞吐能力的调优主要涉及两个部分:
数据写入侧:在将数据写入 Hologres 之前,针对字段状态频繁变更的场景进行了优化。引入了一个Union 层,在 Union 层和 ODS 层中,数据根据主键进行分区。在 Union 层中,通过一个小窗口进行预聚合计算,以减少对 Hologres 的写入压力,从而提高整体数据吞吐量。然而,这种方式的缺点是无法捕获中间状态的数据。
数据读取侧:在使用 Binlog 更新数据时,会产生连续的变更前后数据。在这种场景下,可以采用lag 开窗的方式来获取一次变更中连续的上下游数据。通过比较这两个数据之间的差异,可以过滤掉冗余的变更数据,从而减轻整个处理下游数据的压力。这种方式可以提高读取数据的效率和吞吐量,减少不必要的数据处理。
5. 元数据血缘的改造
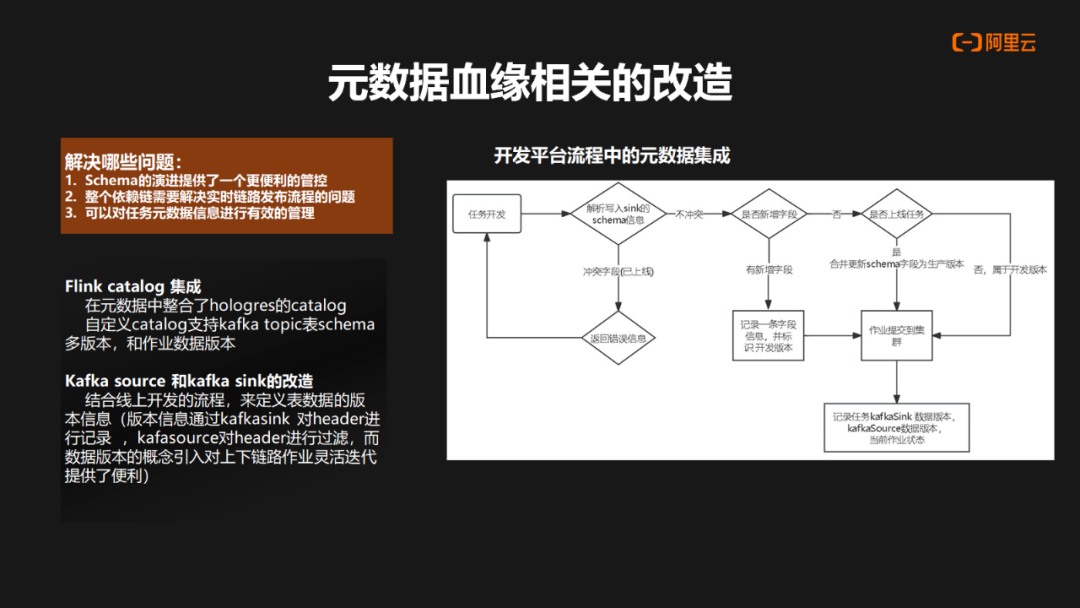
元数据血缘的改造主要解决了以下问题:
· Schema 的演进提供了一个更便利的管控
· 解决实时链路发布流程中的依赖链问题。
· 对任务元数据信息进行有效的管理
曹操出行主要进行以下措施来实现上述目标:
· Flink Catalog 集成,在元数据中去整合 Hologres 的 Catalog,也支持 Kafka Topic 表中自定义 Catalog,支持多版本 schema 和任务数据的多版本,提供更灵活的数据处理能力。
· Kafka Source 和 Kafka Sink 的改造。结合整合整个上线发布的流程,对于数据的版本信息,是通过 Kafka Sink 对 Header 进行记录,Kafka Source 对 header 的版本信息进行过滤,从而把数据版本引入到整个上下游的链路,提供上下游数据灵活的迭代。这种做法的好处是,在整个链路中可以感知到下游数据的使用情况,帮助用户快速定位是否还有任务依赖于某个版本的数据,图片主要是展示一个开发流程中元数据的集成。
6. 链路保障体系

在日常开发过程中,对于任务健康以及任务出现异常后的判断和检测,都是通过异常检测诊断工具去做支持。主要体现四个方面:
对于基础信息采集,通过采集工具,把 Flink 内置 Metric 、Yarn 的 Metric 以及 Kafka 信息进行采集,提供基础数据,包括作业信息,Kafka 一些 Topic 信息,作业最新指标情况。
对于异常的判断,通过内存以及 Topic 增长情况,包括 CPU 使用情况,以及任务有无出现反压,任务有无倾斜做出异常的判断。
对于异常原因的诊断-内部原因,内部原因主要会看 CheckPoint 的失败情况,Kafka LAG 具体是什么算子造成的反压,Restart 的次数,attempt 的次数。
对于异常原因的诊断-外部原因,外部原因主要是看 Job Manager 以及 Task Manager 所在节点自身的情况,包括 CPU 使用率、IO 利用率、内存情况等,然后做出综合判断,帮助用户去快速定位具体问题的原因。
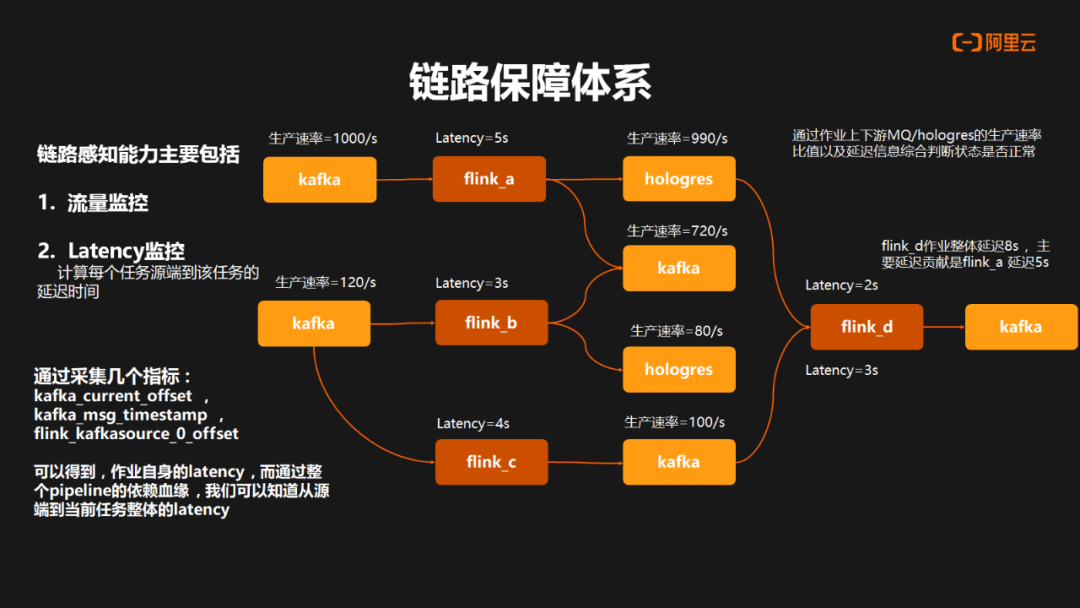
在链路保障体系中,全链路的感知能力是非常重要的。曹操出行主要通过流量监控和延迟监控来实现全链路的感知能力:
流量监控层面:通过 Kafka Cueernt Offset 以及 Hologres 内置的 Offset 信息做定时的采集,从而推算出 Kafka 以及 Hologres 表的生产速率。
Latency 监控层面:主要采集 Kafka Offset 以及 Flink Source 的 Offset 情况,结合 Kafka Massage Timestamp 去推算出每个任务自身延迟情况,再结合整个数据血缘进行一个串联,可以得出端到任务自身整体的延迟时间。
通过任务上下游生产速率比,以及任务自身延迟情况,在整个生产链路中可以快速定位出具体异常和问题发生的节点,以便及时处理和优化,提高系统的性能和稳定性。
7.数据订正能力建设
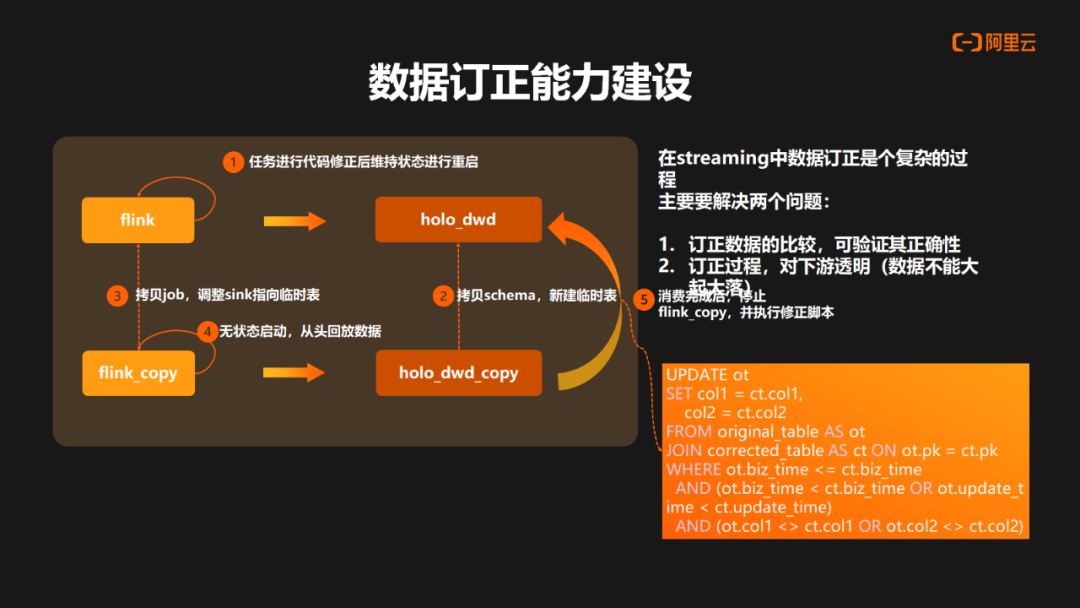
在传统的 Streaming 链路中,数据订正方案一直是个复杂工程,主要涉及以下两个方面的挑战:
如何知晓订正的数据为正确数据?验证其具有一定困难。
在整个验证过程中,如何保证对下游的透明?如果丢状态去做重启的订正,肯定会对下游造成很大的影响。
因此我们主要思路是基于 Hologres 去做实现。首先对于原始任务进行代码修正后,并维持原有状态去做重启。第二步将对 Hologres 表做 Schema 的拷贝,然后新建一个订正的临时表。第三步会将任务进行拷贝,并将 Sink 调整到订正临时表,去做无状态从头消费的重启。这样可以把订正的结果数据订正进 Hologres 订正表中。等待消费结束后停止订正任务,然后通过修正脚本去对比原表以及订正表中关键信息,去做数据的订正。由于数据的订正,它处于数据终态,对于下游来说,不会造成大起大落。并且在整个链路中,因为正确数据可以通过整个数据链路做回撤的传导,因此整个下游就可以自动完成数据的订正。
05
曹操出行业务成果分析

1. 架构清晰简单
对比原有 Lamada 架构,Hologres + Flink 整体架构更加清晰,使用数据组件大大减少
整体技术复杂难度降低,原先为了解决数据一致性问题,数据需要在不同的异构存储和异构链路中来回传输和计算,整个技术复杂度较高
2. 开发效率提高
整个开发模式变得简单易用,大大缩短人力周期
数据实时模型分层非常清晰,整体下游复用性以及使用门槛大幅度降低
3. 运维体验提升
由于数据存储在 Hologres 之上,因此数据探查更加便捷,数据订正难易程度大幅度减少。
4. 成本减少
组件维护成本减少
数据的离线存储和实时存储,从双份存储降低到一份存储,以及降低了数据在异构存储之间的同步与计算成本
解决在 Flink 中各类计算场景中大状态的资源成本,减少了计算开销并提升了处理性能。
06
未来展望

未来展望主要分为以下四个层面:
当前 Flink 集群还是一个自建的集群,对于这些集群我们业务最关心的是使用过程中,其业务的稳定性和可靠性。特别是在高峰场景,资源不足时,怎么去做快速的缩扩容。在高峰期过去后怎么去做到无缝缩容,降低业务风险,包括减少业务的数据中断时间。
在任务级别的动态感知和智能调控上。很多时候研发根据自己的经验去设置 Flink 的资源参数,往往有很多资源其实是多设或者是额外设置的。通过动态感知能力的引入,能够有效提升整体的资源使用情况,包括未来也可能会引入智能算法,包括自适应的机制去达到节约成本的目的。
FlinkCDC 来统一 ODS 入仓的方案。我们在离线使用 DataX 的入仓方案,后来实时使用了 Flink CDC 的入仓方案,其实本质上数据可以提供一个统一的解决思路,来解决数据的一致性和灵活性的诉求。包括在 CDC 方案中,也会有一些定制上的需求。比如说在 CDC 过程中数据加解密以及 RDS 数据归档一系列诉求。使用 Flink CDC 的过程中也会分阶段的做一些调整,包括一些高频迭代的诉求也会在后续的规划中更优先的解决。
关于曹操出行的数据服务规划。目前有很多数据服务场景,包括了在线应用场景,以及分析型的服务场景,业务会比较关注数据服务的高可用以及服务的可扩展性,那怎么样通过同一份数据来做到不同服务的扩展。这部分我们后续会考虑基于 Hologres 主从隔离的能力和结合数据存储计算隔离的一些特点优势,构建一主多从的架构,来支持和满足这些数据应用服务。

