Flink流批一体是否能真正取代Spark引擎
摘要:2022年Flink作为流批一体引擎,曾经火爆一时,但是实止今日,spark 引擎任然作为批处理引擎的首选,flink引擎作为流处理的引擎,为什么flink 都可以作为流批一体了,为什么没有替代spark引擎,本文将从flink引擎的功能,和spark引擎的对比,以及技术生态角度介绍,flink引擎为什么没有替代spark引擎。
01
—
Flink引擎的功能
前面有文章介绍了流批一体的技术架构,以及flink引擎的功能,可以参考文章:
Flink 如何做容错?
Flink的Datastream 核心API的应用场景
Flink的高阶API-Table API&SQL
实时数仓&流批一体技术发展趋势
如下图所示:
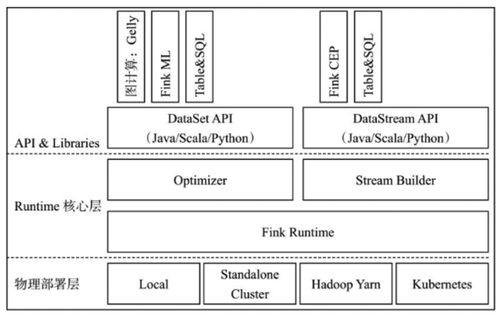
以上架构图可以看出,flink的功能架构主要分为API&Libraries层和Runtime核心层两层。
Flink的API&Libraries层提供了丰富的接口和库,以支持流处理和批处理计算。对于流处理,Flink提供了DataStream API,允许开发者以高级和可维护的方式编写复杂的流处理程序。同时,Flink还提供了大量的库,如CEP(复杂事件处理),Table API等,用于处理流式数据的常见场景和问题。
对于批处理,Flink提供了DataSet API,它允许用户以类似于传统批处理系统的方式处理有界数据集。用户可以使用丰富的操作符和函数对数据进行转换和操作。
Flink的API&Libraries层的设计目标是提供灵活、高级和可扩展的接口,以满足不同类型的计算需求。同时,Flink还提供了对Java和Scala编程语言的支持,使得开发者可以使用他们熟悉的编程语言进行开发。
Flink的Runtime核心层是Flink框架的核心,它提供了基础的服务来支持分布式流处理作业的执行。这一层面对上层不同接口(比如DataStream和DataSet)提供了统一的基础服务,使得在流式引擎下能够同时处理批量计算和流式计算。
在这一层,Flink可以将DataStream和DataSet转换成统一的可执行的Task Operator,然后将JobGraph转换成ExecutionGraph,进行任务的调度和执行。这样,Flink能够像批处理一样高效地处理大规模的数据,同时又能够处理实时的数据流,实现了流批一体的能力。
这种流批一体的能力是Flink的一大优势,它使得用户可以在同一个引擎上运行不同类型的作业,并且能够实现更低的延迟和更高的吞吐量。与其他引擎相比,Flink在流处理方面的特点更加突出,能够在处理实时数据的同时保持一定的容错性和一致性。而在批处理方面,Spark由于其广泛的应用和优秀的性能,目前在批处理领域处于首选地位。
02
—
Flink引擎和Spark引擎的对比
在上一文中介绍了spark引擎的主要功能,可以参考文章:
一文了解Spark引擎的优势及应用场景
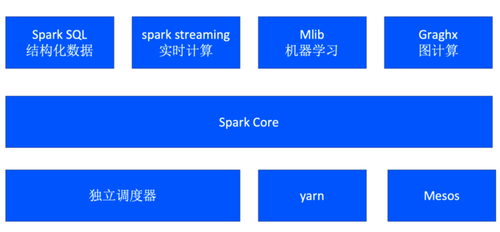
从两个引擎的功能架构上好似差不多,都支持SQL,实时计算,机器学习库和图计算。也有大数据开发对两个引擎进行的详细的对比:
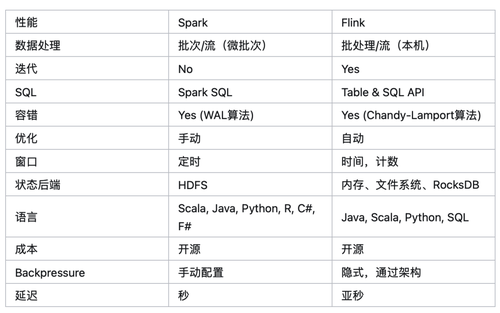
功能上的主要区别是:
1、Spark 和Flink 在流处理上,spark是利用的微批处理模拟流数据,而flink是采用的真正的流数据处理方式,flink是采用流数据模拟批数据处理。
在执行引擎这一层,流处理系统与批处理系统最大不同在于节点间的数据传输方式:
对于一个流处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,然后立刻通过网络传输到下一个节点,由下一个节点继续处理
对于一个批处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,并不会立刻通过网络传输到下一个节点,当缓存写满,就持久化到本地硬盘上,当所有数据都被处理完成后,才开始将处理后的数据通过网络传输到下一个节点。
对于Spark来说默认是批处理的模式,流处理模式是采用微批来处理,而Flink采用的是缓存块的超时时间参数来控制是流处理还是批处理。
如果缓存块的超时值为0,则Flink的数据传输方式类似上文所提到流处理系统的标准模型,此时系统可以获得最低的处理延迟
如果缓存块的超时值为无限大/-1,则Flink的数据传输方式类似上文所提到批处理系统的标准模型,此时系统可以获得最高的吞吐量
timeoutMillis > 0 表示最长等待 timeoutMillis 时间,就会flush//是批处理
timeoutMillis = 0 表示每条数据都会触发 flush,直接将数据发送到下游,相当于没有Buffer了(避免设置为0,可能导致性能下降)//流处理
timeoutMillis = -1 表示只有等到 buffer满了或 CheckPoint的时候,才会flush。相当于取消了 timeout 策略 //批处理。
2、计算窗口,SPARK是基于窗口时间,而flink可以基于时间也可以基于计数。
3、状态后端不同;Spark的状态后端是指用于存储和管理Spark应用程序中的状态数据的存储系统。在Spark中,状态是指在执行计算过程中需要持久化和共享的数据,例如累加器和广播变量等。Spark提供了不同的状态后端选项,包括内存、磁盘和HDFS等、
Flink的状态后端是用于存储和管理作业状态的一种机制。它用于存储当前作业的状态、检查点数据以及保存的用户状态。通过状态后端,Flink能够在发生故障时保证作业的一致性和容错性。
Flink支持多种类型的状态后端,包括内存、文件系统和分布式存储系统等。
4、延迟,spark是秒级,flink是亚秒级。
从以上的功能分析,好像是flink更具优势,那么为什么flink没有替代spark引擎了?
03
—
Flink引擎为什么没能替代Spark引擎?
Flink引擎和Spark引擎作为流和批处理引擎,处理的数据大部分来源数据湖,数据仓库的数据是结构化的数据,一般采用批处理就可以,那么数据湖的管理框架是哪些了?之前有文章介绍了数据湖相关技术框架:
数据湖:从前世到今身的演进与选型探索
管理引擎如何实现数据湖的ACID特性
其中说到数据湖目前主要的三个管理引擎DeltaLake、Hudi、Iceberge;其中也做了对比分析。
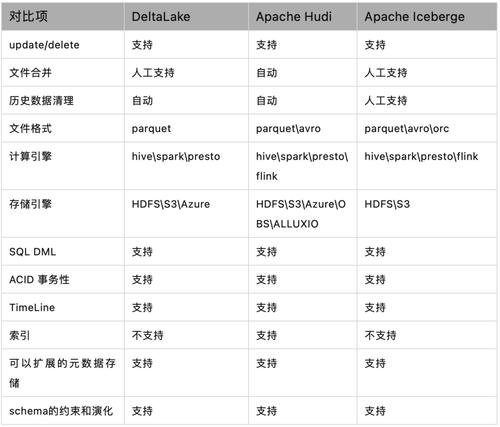
可以看到,DeltaLake对flink引擎不支持,因为flink引擎并不是hadoop生态下的引擎,spark引擎是hadoop生态下的引擎。而另外两个数据湖管理引擎都支持spark引擎。而hudi管理引擎是用 Spark 实现的一个通用数据湖框架,它与 Spark 的绑定可谓是深入骨髓。如果要使用flink引擎,需要将hudi和spark引擎解藕。而对于Iceberge引擎,flink支持的也是不够完善。主要体现在:
1、Iceberg目前不支持Flink SQL 查询表的元数据信息,需要使用Java API 实现。
2、Flink不支持创建带有隐藏分区的Iceberg表
3、Flink不支持带有WaterMark的Iceberg表
4、Flink不支持添加列、删除列、重命名列操作。
5、Flink对Iceberg Connector支持并不完善。
以上一些重要的功能在Iceberg上支持的不好,也导致flink在Iceberg上使用的并不好。
由于spark引擎已经和DeltaLake、Hudi做了强的技术绑定,以及三个管理引擎的运营情况来看,SPARK依然是最顶流的计算引擎。
我们再来看看 DeltaLake、Hudi、Iceberge三个管理引擎的社区情况:
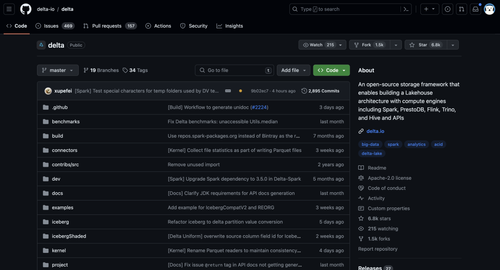
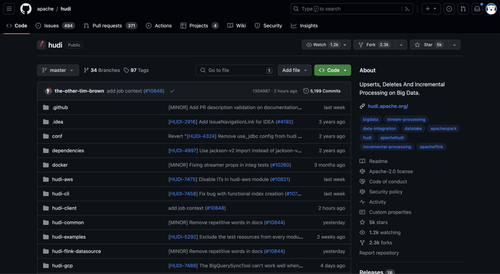
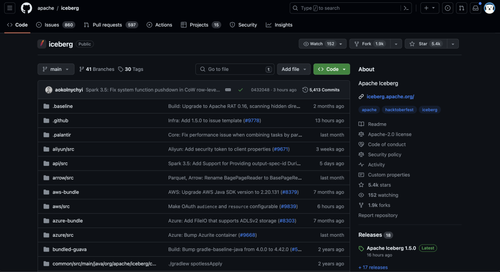
引擎名称 star值 PR值 贡献人数
DeltaLake 6.8k 157 279
Hudi 5k 371 445
Iceberge 5.4k 597 457
从社区运营的数据来看,DeltaLake、Iceberge相对要好一些。而spark和flink引擎的社区运营情况如下图所示:
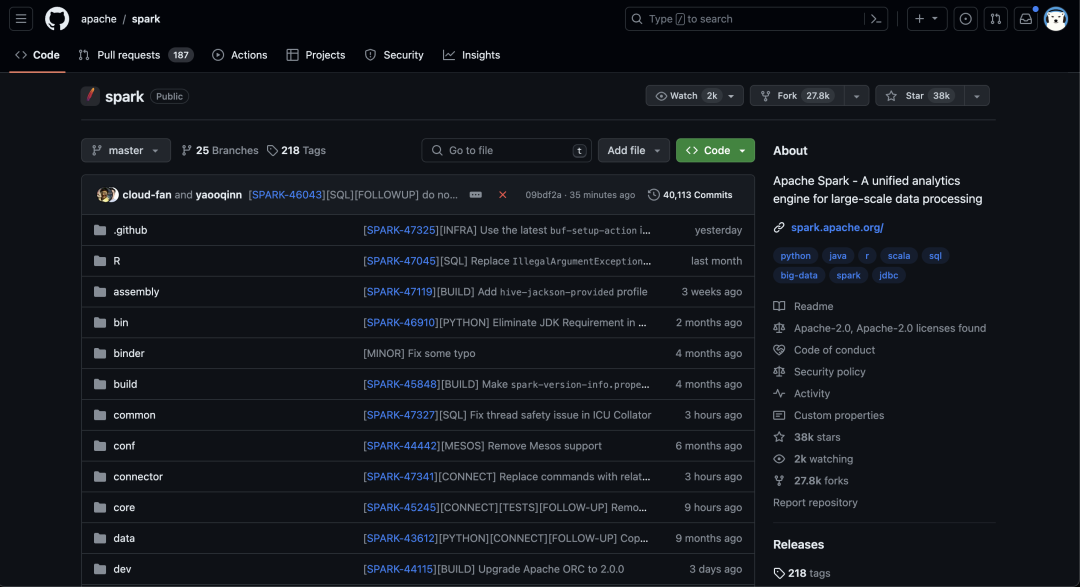
引擎名称 star值 PR值 贡献人数
Spark 38k 187 2058
Flink 22.9k 1.1k 1202
从社区运营的数据来看,Spark还是使用人数最多,但是相比flink来说,flink获取代码的次数远超过spark,使用前景还是很活跃。
从以上分析,spark 目前依然是批处理首选引擎,因为和数据湖的管理引擎有强的技术绑定原因成分,而flink不是hadoop的生态圈的引擎,目前主要发展和实时数据仓库的结合以及应用场景,例如StarRocks、Doris。

