Uber 是一个全球品牌,在全球 10,000 多个城市运营。该公司运营规模庞大,每月为超过 1.37 亿用户提供服务,每天为 2500 万次出行提供服务。数据驱动——乘客、司机和企业经营者采取的每一个行动。在如此规模的数据中,将所有这些活动的原始数据转化为业务洞察的技术挑战尤其困难,尤其是以高效且可靠的方式做到这一点。
Uber 也是 Onehouse 起源故事的核心。Hudi 项目当时被称为“事务数据湖”,由 Onehouse 创始人兼首席执行官 Vinoth Chandar 在 Uber 发起。该项目随后于 2016 年由 Apache 软件基金会接管,Vinoth 随后创立并运营 Onehouse。
Uber 工程总监 Girish Baliga 在演讲中分享了该公司如何构建和发展其数据基础设施,以实现 Uber 帮助人们去任何地方并获得任何东西的使命。就上下文而言,Uber 的数据基础设施团队为具有不同数据需求的广泛内部客户提供支持:
• 社区运营团队与地方当局合作并提供报告,以确保业务顺利运行
• 机器学习工程师和数据科学家利用公司数据来改进产品的匹配算法和连接
• 增长营销团队利用数据洞察来激励业务增长
所有这些内部客户都有相同的基本目标:他们希望从大量的公司数据中获得业务洞察。但他们在数据新鲜度、规模或软件集成方面没有相同的期望。一些客户需要实时或近实时的洞察,以及经常更新的数据(例如,数据新鲜度不到一分钟)。其他人可以接受更长的等待时间,最多一天,例如为餐厅老板运行预定的 Uber Eats 优食报告时。
Uber 的数据分析挑战
Uber 的数据基础设施团队收到四种主要类型的分析请求。每一个都代表一个独特的用例,从技术角度来看具有不同的含义。为了说明这一点,Girish 分享了下图。

流式分析
此类别需要极其新鲜的数据,通常需要在一分钟内更新。Uber 的一个典型例子是解决激增定价失衡问题,需要立即调整定价算法。这些应用程序通常与实时系统集成,例如Kafka主题,以方便数据的快速处理和流通。
实时分析
UberEats 提供了一项功能,可以显示用户附近的热门订单。此功能是实时分析的一个重要示例,其中数据刷新很快,但不如流分析所需的那么频繁。然而,此类应用程序的流量更为密集,查询有时达到每秒 2000 次。这些应用程序通常通过查询分析引擎的 RPC(远程过程调用)接口与后端交互。
交互式分析
这里的一个典型用例包括为餐厅经理生成每日摘要报告,详细说明他们的 UberEats 订单和收入。对于交互式分析,数据新鲜度约为一天,规模约为每个餐厅老板的多份报告。这些查询由处理自动化的协调器或查询运行器执行。
批量分析
批量分析用于检查历史数据,例如过去一年的订单趋势。查询生成器等交互式工具使用户能够轻松探索和分析数据。这些应用程序按预定义的时间表运行自动查询。
统一的数据分析框架
在此架构中,传入数据流同时服务于实时和批处理情况。对于实时情况,流分析引擎将数据从数据流传输到实时数据存储中。然后数据通过查询界面暴露给最终用户。对于批处理情况,会摄取相同的数据流,但它会进入数据湖,并在数据湖上执行自定义分析和转换。然后引擎从该数据管道创建数据模型。然后将数据提供给用户进行报告和进一步分析。
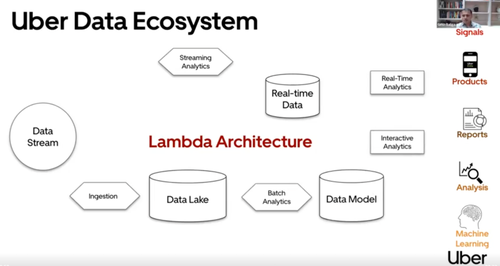
为了满足内部客户的各种需求,Uber 构建了一个遵循 Lambda 架构的数据平台,这是数据分析领域广泛采用的架构。这种方法可以处理低延迟流工作负载以及批处理工作负载。因此,Uber 的数据基础设施平台可以通过单一设计管理所有四种主要分析用例——流式分析、实时分析、批量分析和交互式分析。
在此架构中,传入数据流同时服务于实时和批处理情况。对于实时情况,流分析引擎将数据从数据流传输到实时数据存储中。然后数据通过查询界面暴露给最终用户。对于批处理情况,会摄取相同的数据流,但它会进入数据湖,并在数据湖上执行自定义分析和转换。然后引擎从该数据管道创建数据模型。然后将数据提供给用户进行报告和进一步分析。
Uber 使用开源技术作为 Lambda 架构的基础。Apache Hudi 是此设置的一个核心组件。Hudi 专为解决大规模管理数据的挑战而开发,可以将更新插入时间缩短至 10 分钟,并将端到端数据新鲜度从 24 小时缩短至仅 1 小时。在 Hudi 出现之前,该公司受到重新获取数据的速度的限制,通常速度很慢。Hudi 允许团队以低延迟增量处理新数据,从而提高了效率。
对于批处理工作负载,Uber 在 Spark 上运行摄取作业。Parquet 用于文件管理,Hadoop 作为存储层。Hive 作业从数据湖获取数据并使用非常相似的堆栈构建数据模型。
在流式分析方面,Uber 使用 Apache Kafka 进行数据流处理,并使用 Flink 进行分析。实时数据在 Pinot 上提供。在 Pinot 之上,该团队构建了一个自定义 Presto 查询界面,允许用户编写 Presto SQL 并在 Pinot 上实时运行查询,就像传统的生产后端系统一样。
赋能用户查询不同级别的数据
Lambda 架构描述了如何通过不同的分析引擎传输数据。但是一旦获得了适当的数据,内部客户如何查询数据以获得有价值的业务见解?
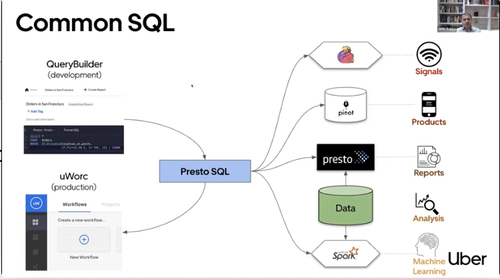
数据基础设施团队支持三种查询语言来满足客户需求 - 从高级、通用 SQL 方法到为高级用户提供更可定制的低级支持:
Presto SQL
Uber 的数据平台支持 Presto SQL 作为其默认查询语言,为数千名内部用户提供广泛的用例(从生成报告到增强产品功能)。用户在 QueryBuilder(类似于用于代码开发的本地 IDE 的工具)中制作和完善查询,然后通过通用工作流编排器 (uWorc) 部署它们以供生产使用。
自定义SQL
对于 Presto SQL 无法满足的更专业的要求,例如需要自定义用户定义函数 (UDF),或调整计算资源以支持非常大的查询,Uber 提供了 Flink SQL 和 Spark SQL。这些 SQL 变体可满足数百个内部客户的需求,为数据工程任务提供扩展功能,包括 ETL 作业和数据建模。
编程式API
对于最复杂的场景,Uber 的数据平台提供了编程 API。这些具有特定领域库(例如 Java、Scala、Python 等)的低级 API 使高级用户能够基于 Flink 和 Spark 为其用例开发自定义程序。Flink 解决实时产品用例的离线需求,例如 ETA、峰时定价和指标,而 Spark 处理仅离线用例,例如摄取、ETL 和模型训练。
超级规模的技术创新
Girish 强调了 Uber 数据基础设施团队实施的多项技术定制,以提高可靠性、增强性能并促进多云部署。
可靠性和规模改进
检查数据基础设施堆栈的一个子集,特别是 HDFS 集群(数据存储)和 Presto 集群(数据读取和数据写入),Girish 强调了一些帮助 Uber 实现可靠性和规模的创新:
• 智能查询路由,因此重型查询与轻型查询在不同的集群中运行
• 多区域部署:Hive Sync用于将数据从主区域复制到辅助区域。如果发生区域故障,备用 Presto 集群会处理需要立即运行的高优先级作业,而其他作业则以降级的 SLA 运行。
• 使用 Hudi 的记录级别索引:一种在 Apache Hudi 之上构建事务层的高级方法,不依赖 HBase 等辅助键值存储系统。
• 出现错误时运行的自动重试(例如,在集群部署或重新启动期间)
• 存储了多个数据副本,因此如果一个副本损坏,仍存在健康的数据存储。
• 可以添加新的副本来支持热分片,以便系统可以处理高水平的读取流量。
• 纠删码和分层存储用于较旧的数据,以大规模实现更高的效率。
• 单独的集群用于交互式与离线、计划的查询。
性能优化
Uber 的数据基础设施团队设计并执行了以下优化以提高性能:
• 用于读取数据的 Presto 优化,包括矢量化读取器、嵌套列和谓词下推。
• 将Alluxio库集成到Presto工作线程中,这使得本地SSD可用于缓存数据。亲和性调度用于确保缓存得到正确利用。
• 在存储方面(HDFS),Alluxio本地SSD用于缓存以加快检索速度。保留所有热数据的副本,以便大多数读取运行得非常快。
多云改进
Uber 在混合数据环境中运营。传统上,团队使用其堆栈的本地部署。但他们目前正在 Google Cloud 上构建云数据,使用 HiveSync 将数据从 HDFS 复制到 Google Cloud 对象存储。这里有两个关键的改进很突出:
• 定制用于查询分析的 Presto 路由器:查询时,系统使用 Hive Metastore 来确定查询表的位置(本地还是云端),以优化查询执行并通知跨存储位置的数据智能放置。
• Google Cloud 对象存储之上的 Presto:通过使用自定义 HDFS 客户端,Presto 与 Google Cloud 对象存储进行交互,就好像它在查询 HDFS 一样,从而提高了性能。
总的来说,这些创新凸显了 Uber 致力于利用开源技术提供强大的数据平台,该平台在其全球数据基础设施中可扩展且可靠。

