豆包大模型价格出炉!超高并发,“后付费”支持每分钟万次请求
近期,火山引擎官网更新了豆包大模型的定价详情,全面展示豆包通用模型不同版本、不同规格的价格信息。
在模型推理定价大幅低于行业价格的基础上,豆包通用模型的 TPM(每分钟Tokens)、RPM(每分钟请求数)均达到国内最高标准。以豆包主力模型pro-32k为例,价格比行业低99%,TPM限额则高达同规格模型的2.7倍到8倍。
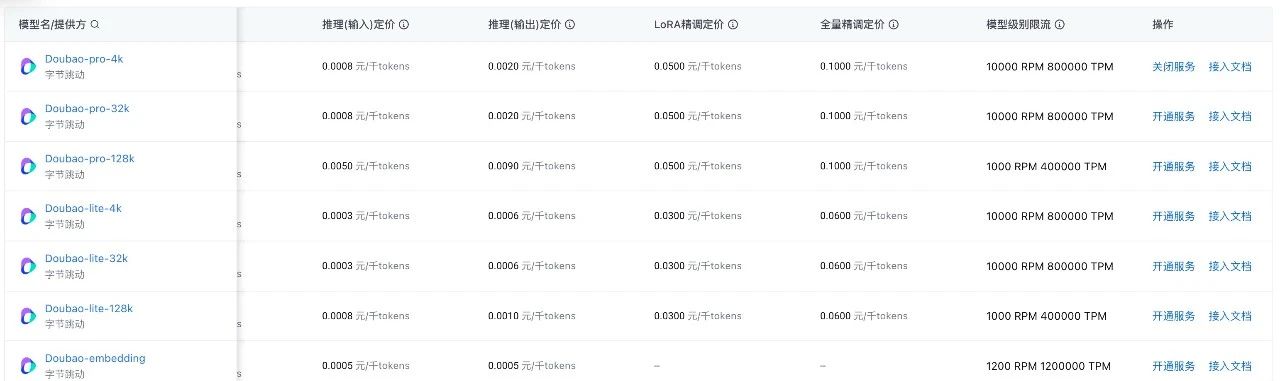
豆包系列模型“后付费”定价信息
官方信息显示:在按照 Tokens 实际使用量计算费用的“后付费”模式下,豆包通用模型-pro、豆包通用模型-lite的32k及以下窗口版本,模型限流为10K RPM和800K TPM(以RPM和TPM其中之一到达上限为准)。国内其他主流模型的TPM限额大多在100K到300K之间,RPM则是在60到120区间,轻量级模型的RPM限额相对较高,但仅仅在300到500之间。
按照10K RPM限额计算,企业客户平均每秒可以同时调用167次豆包通用模型,从而满足绝大多数业务场景在生产系统的大模型应用需求。这一标准,已经达到OpenAI为高级别客户(Tier4及Tier5等级客户)提供的RPM上限。
在算力挑战更大的长文本模型上,豆包通用模型pro和lite的128k版本,模型限流为1K RPM和400K TPM,同样大幅高于国内其他的128k长文本模型。
此外,豆包大模型公布了最新的“预付费”模型单元价格。“预付费”是以调用某个特定模型的TPM配额,企业购买后无需再为Tokens消耗付费,提前为可以预见的流量波动规划好算力。

豆包系列模型“预付费”模型单元价目表
以豆包通用模型pro-32k为例:
按照 “预付费”模型单元价格计算,10K TPM的包月价格为2000元。10K*60*24*30=43200K。即432000K Tokens的价格为2000元,平均价格为0.0046元/千Tokens。
按照“后付费”模式计算:在模型推理的计算成本中,推理输入通常占绝大部分比例,业界一般认为推理输入是输出的5倍。根据豆包通用模型 pro-32k 推理输入0.0008元/千Tokens、推理输出0.002元/千Tokens计算,模型推理的综合价格为0.001元/千Tokens。
火山引擎方面表示,豆包大模型为客户提供了灵活、经济的付费模式,“后付费”即可满足绝大多数企业客户的业务需求,助力企业以极低成本使用大模型、加速大模型的应用落地。
“豆包模型的超低定价,来源于我们有信心用技术手段优化成本,而不是补贴或是打价格战争夺市场份额。”火山引擎总裁谭待认为,“羊毛出在猪身上”在企业市场行不通,技术驱动的极致性价比才能真正创造价值。
火山引擎与字节跳动豆包大模型团队正在密切合作,将持续优化模型效果和推理成本,为企业和开发者提供更好模型、更低成本和更易落地的平台支持。
附:火山引擎官网的模型服务价格文档
https://www.volcengine.com/docs/82379/1099320

