大数据平台的两种建设路径对比
一个完善的大数据平台要如何构建?我们立刻会想到各种组件Hive、Spark、Flink……大数据平台涉及的组件众多,上下游关系复杂,需要支持的业务可以说是多种多样,如果团队强大,有实力、有时间,选择自己构建一定不会错!
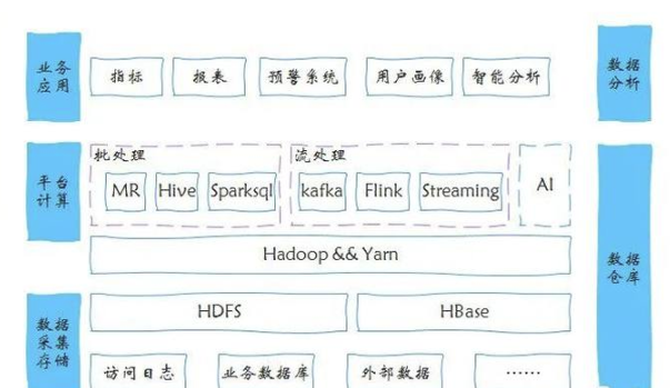
但现实情况是,开发团队的时间通常有限,能力和经验也有欠缺和不足。如果从零开始,那就涉及以什么样的方式去逐步构建的问题。大体看来,大数据平台服务的构建可以分为两种方式。
1、以垂直业务场景为核心来构建
在构建系统时,我们主张以垂直业务场景作为出发点,这样做旨在精确匹配业务需求,实现一站式服务支持。
优势分析:
1)业务贴合度高。直接对应具体业务,产品逻辑能够高度定制,确保与业务需求完美契合。
2)流程与架构可控。交互流程与架构复杂度在可控范围内,减少与业务无关的内容,提升用户体验。
3)演进迅速。由于不必过多考虑通用性和业务间兼容性,产品架构能够快速成型,演进负担较小。
劣势思考:
1)系统专用性强。这种构建方式可能导致系统拓展性受限,难以适应未来业务变化。
2)重复建设风险。在多部门间,若缺乏统筹考虑,可能出现大量重复建设的工作,浪费资源。
案例分析:
以广告部门的数据分析业务为例,它们的核心目标是快速产出准确的计费数据以支持投放策略决策。在这种情况下,一体化、高度定制化的业务流程往往是最优选择,因为它确保了数据的准确性和策略调整的及时性。
应对方案:
考虑到部门间可能存在的竞争关系或基础架构团队服务的不满意,一些部门可能选择自行构建系统。但为避免重复建设,需要提出以下建议:
1)建立跨部门协作机制。通过定期沟通、共享资源等方式,减少重复工作,提升整体效率。
2)标准化与模块化。在保障业务定制性的同时,尽量将通用功能标准化、模块化,便于未来拓展和复用。
3)引入第三方服务。对于非核心业务,可考虑引入第三方服务,减轻自身开发压力,同时确保服务质量。
以垂直业务场景为核心构建系统能够精准满足业务需求,但在实施过程中需注意系统拓展性和重复建设问题。通过跨部门协作、标准化与模块化以及引入第三方服务等方式,可以有效应对这些挑战,实现高效、可持续的系统构建。
还有一种情况是,各个集团部门间存在竞争关系,或者不满意基础架构团队提供的服务,所有的东西宁愿自己搞一套。但是人手又不足,怎么办呢?当然就是抛弃通用性,怎么简单怎么做。
2、通用组件建设,灵活支持业务的方式
在现代软件架构设计中,一种常见且高效的方式是通过构建独立的通用组件或服务,并灵活组合这些组件来支持各类业务场景。这种方式的核心在于抽象出业务中的通用功能需求,形成可复用的模块。
优势分析:
1)高度可拓展性。由于这些组件是基于通用功能构建的,因此它们可以轻松地应用于不同的业务场景,提供了良好的可拓展性。
2)减少重复建设。通过重用这些通用组件,不同业务系统之间可以避免重复开发,从而节省大量开发资源和时间。
3)深入、完善和稳定的系统设计。由于通用组件被设计为独立的服务,其设计、开发和测试都可以更加深入和细致,有助于构建更加完善和稳定的系统。
挑战与应对:
尽管通用组件建设具有诸多优势,但在实际应用中也面临一些挑战。
1)设计难度较大。由于需要考虑到不同业务场景的通用性,组件的设计需要更加细致和全面。为了解决这一问题,可以通过建立跨部门的沟通协作机制,确保设计能够满足各类业务需求。
2)系统间依赖较多。当多个系统依赖于同一组通用组件时,组件的迭代和演进可能会变得复杂。为了降低这种复杂性,可以采用微服务架构,确保每个组件都具有独立的功能和演进路径。
3)易用性和使用成本。由于通用组件可能需要一定的技术背景才能使用,可能会影响到易用性和使用成本。为了提升用户体验,可以加强文档编写和用户培训,确保用户能够轻松地使用这些组件。
通用组件建设是一种高效且灵活的软件架构方式,它可以通过构建可复用的组件来支持各类业务场景。虽然在实际应用中面临一些挑战,但通过合理的设计和实施策略,可以充分发挥其优势,提升系统的可拓展性和稳定性。
这两种平台的构建方式,没有绝对的好与坏。从蘑菇街平台的实践经验对比两种建设路径没有对错之分,适合与否取决于各公司、团队和业务的具体发展和需求背景。但无论使用哪种方式,都需要考虑如何尽可能地扬长避短,采取必要的手段去弥补缺点。
蘑菇街平台的实践经验对比两种建设路径
2016年蘑菇街和美丽说进行了战略合并,不可回避的问题就是技术平台也需要进行方案融合,这也让其有机会从技术、服务、产品的角度去比较两者的大数据平台的建设思路和具体实践方案。
技术方案融合前,美丽说的大数据平台的建设思路,基本就是按照前文第一种方式,也就是围绕业务进行定制的原则来开发的。在某些具体定制化业务的产品服务实现方面,客观地说,当时其易用性要比蘑菇街对应的产品好很多,用户口碑也不错。
但带来的问题就是,不同的业务和产品线往往针对不同的产品和功能需求,各由一套体系来支撑。比如,当时在美丽说的大数据平台体系中,作业工作流调度系统就有独立的三套实现方案内嵌在各个产品之中。这些方案和各自产品的流程及业务逻辑的耦合度都很高,很难进行剥离和替换,其他组件也有类似的情况。所以,在各个业务之间,相关的产品基本没有打通流程的可能性,平台的维护成本也很高,技术迭代比较困难。
而蘑菇街的数据平台服务,则是采用第二种方式来演进的。
在2014年左右,蘑菇街只有最基本的功能组件,包括定时轮询的调度系统、 Hive集成开发平台、定制的报表系统、简单的权限系统,以及使用Storm开发基本的实时计算业务等。
在2015年左右,蘑菇街开始添加更多的功能组件,引入Spark计算框架,开发元数据管理系统和自定义查询系统, Storm代码开始模块化构建,全站用户页面行为跟踪埋点体系也开始构建,并进行了一些底层系统整理改造工作,包括公司内部底层多个集群的整合、改造、升级。在数据平台各业务后台权限管理的统一、报警服务系统的拆分构建等方面,既有经验收获,也有教训。
收获是,整个2015年,大数据平台做了大量的稳定性改进、模块拆分、组件完善、集群融合、升级等工作,在一定程度上完善了数据平台的体系架构,降低了维护代价,提升了稳定性,给平台发展打下了基础。
但是,对应的教训是,从最终业务价值产出的角度来说,整个大数据平台这一年的产出并不明显,终端业务方没有从大数据平台的改进工作中得到显著的收益,所以平台开发团队的外部压力较大。
这也可以理解,从领导和业务方的角度来说,他们并不关心做了什么,重要的是对公司的价值体现在哪里。所以,回过头来看,2015年其实也应该在业务导向方面多做一些思考和工作,避免冰山下的工作不能给团队带来实际的价值回报。所以,在核心系统改造的基础上,2016年开始加入更多围绕终端服务价值产出的工作。
从2016年开始,蘑菇街开始重构部分核心组件的功能和产品形态,以配合推进整体平台的服务化进程,包括权限系统的服务化,构建对象存储系统,完成核心调度系统的重构和功能拓展,以更好地串联业务流程,完成数据可视化平台核心功能的构建,着手进行实时计算平台SQL化和平台管控能力的建设。
这些工作,一方面是内部系统的服务化,比如RBAC的权限系统,用来服务所有的业务和数据后台;比如通用对象存储服务,用来支持其他各类有通用存储需求的系统,如简历招聘系统、小图片存储系统等。
另一方面是针对数据开发用户或终端数据使用用户的服务,整体的目标是降低各项业务开发的难度,让用户能够更加独立自主地进行自我服务,减少需要平台定向支持的需求。
在2017年以后,总体的建设工作更加注重整体傻瓜式服务平台的构建,各种自助服务功能也进一步完善,端到端整体链路服务的打通和专家系统的构建,进一步降低了服务支持的代价。
两种路径对比:
关于平台建设的两种主要方式——垂直业务场景定制化和通用组件组合支持,我们需要再次明确:这两者并没有绝对的对错之分。在蘑菇街的实际场景中,我们也意识到,不能一概而论地说通用组件建设就是最完美的解决方案。
对于某些具体用户或特定场景,垂直业务场景定制化的方案可能更为合适。这是因为它能够迅速响应业务需求,实现高度的定制化,满足用户迫切的需求,从而在短期内带来明显的收益。这种快速响应和直接满足用户需求的方式,是定制化开发方案的一大优势。
在蘑菇街大数据平台的建设过程中,我们曾经面临过组件式建设方式的质疑和挑战,团队成员也承受了一定的压力。然而,通过深入分析和实践,我们认识到,在特定情况下,将两种建设路径进行巧妙的结合,可能是一种更为合理和必要的选择。
正如人生中的许多抉择一样,平台建设也需要我们在各种方案之间进行权衡和取舍。有时候,为了长远的发展和持续的创新,我们可能需要在短期内做出一些妥协和牺牲。但只要我们始终保持清晰的目标和坚定的信念,相信我们一定能够找到最适合蘑菇街平台建设的发展道路。

