大数据领域架构设计全面解析
一、什么是大数据
大数据是针对海量数据进行分布式采集、分布式存储、分布式计算、分布式管理、分布式统计分析使数据变现与战略决策、产生价值的一门技术。在信息科技领域,大数据通常与提取这些数据中有价值信息的技术和相关联工具。
二、大数据处理流程步骤
在整个大数据处理流程中,还需要考虑数据安全和隐私保护、数据治理、合规性等关键因素。此外,随着技术的发展,还可能出现新的步骤和技术,如自动化数据清洗和转换、实时数据分析等。
流程步骤:
1.数据收集(Data Collection):
数据可以来自各种来源,如社交媒体、传感器、日志文件、在线交易等。
数据可以是结构化的(如数据库表)、半结构化的(如XML、JSON文件)或非结构化的(如文本、图片、视频)。
2.数据存储(Data Storage):
选择合适的存储解决方案来容纳大数据,如HDFS(Hadoop Distributed File System)、云存储服务(如Amazon S3)、NoSQL数据库等。
考虑数据的持久性、可靠性和可扩展性。
3.数据清洗(Data Cleaning):
数据可能包含错误、重复或缺失值,需要通过数据清洗来提高数据质量。
清洗过程可能包括去除无效数据、纠正错误、填补缺失值等。
4.数据集成(Data Integration):
将来自不同来源和格式的数据合并在一起,创建一个统一的数据视图。
处理数据的不一致性,如不同的数据格式、命名约定等。
5.数据转换(Data Transformation):
对数据进行转换,使其适合分析用途。
可能包括数据规范化、聚合、维度降低等。
数据挖掘(Data Mining):
应用统计和机器学习技术来发现数据中的模式、关系和趋势。
可能涉及分类、聚类、关联规则学习、预测建模等。
6.数据分析(Data Analysis):
对数据进行深入分析,以获得洞察和知识。
可以使用各种工具和技术,如SQL查询、数据可视化、高级分析软件等。
7.数据展示(Data Visualization):
将分析结果以图形或图表的形式展示,以便于理解和交流。
使用工具如Tableau、Power BI、D3.js等。
8.决策制定(Decision Making):
基于数据分析的结果,制定商业策略或进行科学决策。
需要结合业务知识和领域专家的输入。
9.模型部署和维护(Model Deployment and Maintenance):
如果涉及到机器学习模型,需要将模型部署到生产环境中。
定期监控和维护模型,确保其准确性和性能。
三、什么数据仓库
数仓的主要作用就是提供数据支撑,形成数据集进行报表展示,可视化管理,为企业战略提供数据支撑。
包括如下概念:
ODS层(Operational Data Store):“操作数据存储”,它是数据仓库体系结构中的一个重要组成部分。ODS层位于源系统和数据仓库之间,它旨在提供一个介于实时操作系统和数据仓库之间的中间层,用于存储和维护最新的业务操作数据。
DWD(Data Warehouse Detail):存储详细数据,通常采用事实表和维度表的结构。
DWM(Data Warehouse Middle):存储经过轻度汇总的数据,用于支持部门级别的数据分析。
DWS(Data Warehouse Service):按照主题业务组织主题宽表,用于OLAP分析
DM(Data Market):存储高度汇总的数据,用于支持企业级别的数据报告和分析。 形成一个主题域的报表数据
四、主流架构模式
在大数据领域,主流技术架构通常指的是处理和分析大规模数据集所采用的系统和技术组合。
以下是一些常见的主流技术架构:
离线大数据架构(Hadoop):
Hadoop架构是一个开源框架,允许分布式处理大规模数据集。
它包括HDFS(Hadoop Distributed File System)用于存储数据,以及MapReduce用于数据处理。
适用于批处理和离线分析场景。
Lambda架构:
Lambda架构结合了批处理和流处理,以处理大量数据。
它包括批处理层(Batch Layer)、速度层(Speed Layer)和查询层(Serving Layer)。
适用于需要实时更新和历史数据一致性的场景。
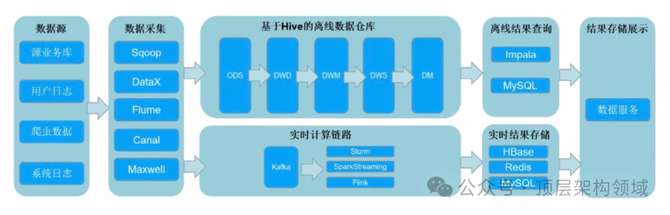
实时业务混合架构:
这种架构结合了多种技术,如Apache Kafka、Apache Flink、Apache Spark等,以支持实时数据处理和分析。
它通常用于互联网公司,特别是那些需要快速响应市场变化和用户行为的公司。
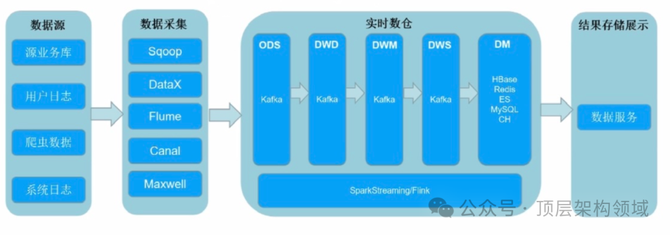
Kappa架构:
Kappa架构专注于流处理,通过重新播放数据流来实现历史数据的重新处理。
它简化了系统设计,因为只需要维护一个处理路径。
适用于实时数据处理和分析,特别是当实时数据处理和准确性至关重要时。
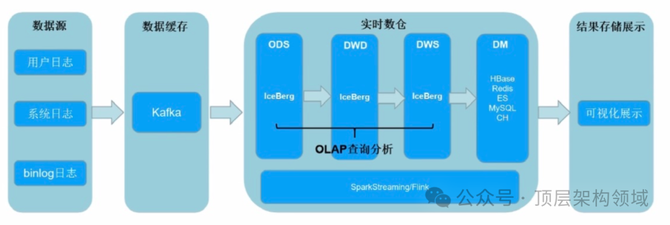
数据湖架构:
数据湖是一个存储大量原始、非结构化数据的大型存储库。
它支持多种数据处理工具,如Apache Spark、Apache Hive等,以及机器学习和数据科学工具。
适用于需要存储大量数据并支持多种分析用途的场景。
边缘计算架构:
边缘计算架构在数据生成的源头(如物联网设备)进行部分数据处理和分析。
它减轻了中心数据中心的负担,并提供了更快的响应时间。
适用于物联网、自动驾驶、智能制造等领域。
五、主流大厂架构模式
下面我们一起来看下各大厂的大数据架构模式应用
腾讯实时数仓实践
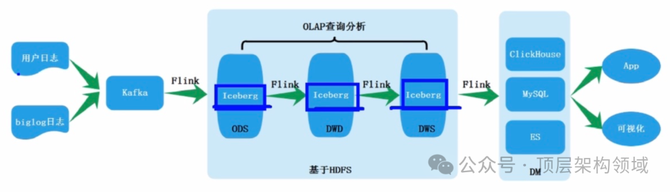
顺丰实时数仓实践
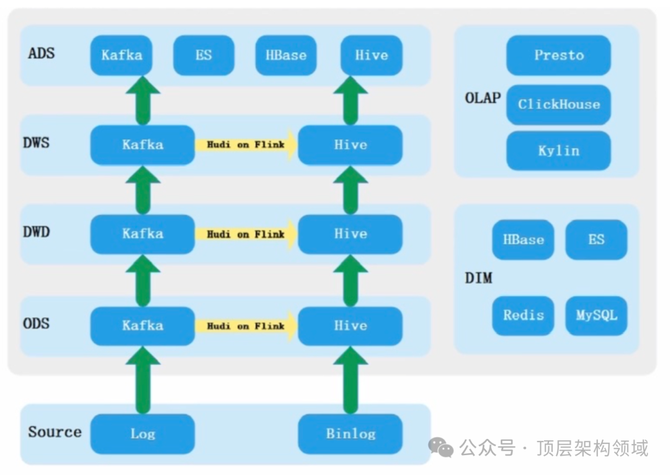
网易实时数仓实践
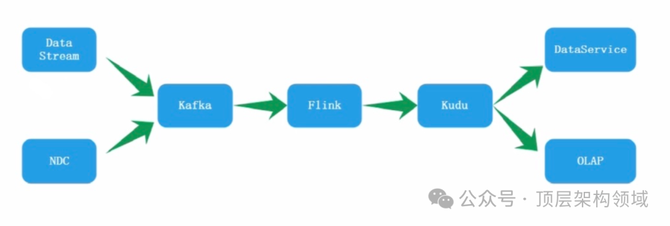
滴滴实时数仓实践
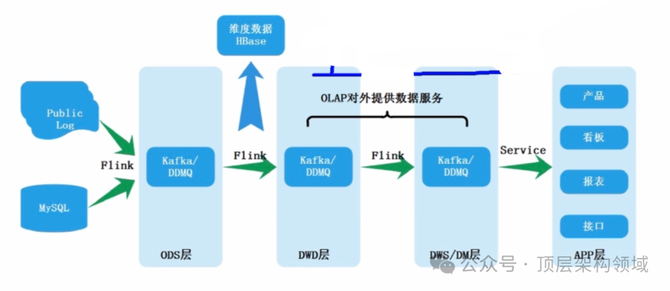
总结:
本文讲解了大数据的处理流程包括数据收集、存储、清洗、集成、转换、挖掘、分析和展示。数据仓库每层的作用,以及目前涉及到的主流大数据架构有哪些和特点是什么。最后给出了几个大厂生产大数据架构模式

