摘要:在数字化浪潮的推动下,数据已经成为企业最宝贵的战略资源。众多企业已经建立了数据仓库,通常采用高效的MPP(大规模并行处理)数据库,如Doris、Druid、ClickHouse等,来满足其商业智能(BI)和报表生成的需求。然而,随着业务需求的不断演进,企业不仅需要传统的数据分析能力,还期望数据平台能够支持算法开发、机器学习以及人工智能等更广泛的应用场景。
为了适应这些不断扩展的应用需求,传统的数据仓库需要向更为灵活和强大的湖仓一体数据平台转型。湖仓一体平台结合了数据湖的灵活性和数据仓库的治理能力,能够提供统一的数据存储和分析解决方案,支持从批量处理到实时分析的多种数据处理模式。
本文旨在探讨如何将现有的数据仓库,如Doris、Druid、ClickHouse等,升级改造为湖仓一体的数据平台。我们将基于当前的数据基础设施,不希望有过多的数据迁移,则能够完成湖仓一体的升级和改造。基于这个目标提供以下方法和升级策略以及实施步骤。
01
—
常规数据仓库升级成湖仓一体的策略
Druid 数据仓库如何改造成为湖仓一体
目前来说druid 作为数据仓库对数据湖的相关支持情况如下。

基于这样的情况,通过对druid完成湖仓一体的改造,需要完成的步骤:
1、Druid 与数据湖的元数据采集统一管理,目前Druid主要是通过摄取数据湖中存储的数据。例如,Druid 可以配置为从 Amazon S3 或 HDFS 这样的数据湖存储中读取数据。但是,Druid 本身并不直接管理数据湖中的元数据,而是依赖于数据湖自身的元数据管理机制。如果需要完成统一的元数据管理,需要额外开发相关功能。
如果需要从数据湖中读取元数据并形成统一的元数据管理,可能需要以下步骤:
1、元数据集成:开发或使用现有的工具和接口来从数据湖中提取元数据。
2、元数据转换:将数据湖的元数据转换为 Druid 可以理解和使用的格式。
3、元数据存储:将转换后的元数据存储在 Druid 的元数据存储中,如 MySQL 或 PostgreSQL。
4、查询和索引:利用 Druid 的查询引擎和索引机制,对元数据进行管理和查询优化。
5、统一元数据服务:如果需要跨多个系统和工具进行元数据管理,可能需要构建或集成一个统一的元数据服务,该服务能够抽象和管理来自不同数据源的元数据。
2、Druid 对数据湖数据查询加速和数据缓存功能。由于druid 对数据湖的数据不是直接访问的,是通过Druid 并不是直接设计用来从数据湖中读取数据的。如果 Druid 需要查询存储在数据湖中的数据,可能需要通过数据集成工具或服务将数据从数据湖导入 Druid,然后再利用 Druid 的查询优化和缓存功能进行查询。例如说通过DeltaLakeInputSourceAPI可让您将存储在 Delta Lake 表中的数据导入 Apache Druid。因此在这种方式下,druid对于构建湖仓一体的数据互访还是有一定难度,需要额外开发。才能达到druid 的查询引擎对数据湖数据查询。
3、定制化开发将druid的数据写入到数据湖中。
Apache Druid 本身不直接支持将数据写入数据湖,如Hadoop分布式文件系统(HDFS)或云存储服务(如Amazon S3)。Druid 通常使用它自己的存储系统来存储数据,称为“深度存储”(Deep Storage),这可以是本地文件系统、网络文件系统(NFS)、HDFS 或云存储服务。然而,Druid 可以配置为从数据湖中读取数据,并且可以与其他系统结合使用来实现数据写入数据湖。
以下是将 Druid 查询结果写入数据湖的一般步骤:
1、查询 Druid:首先,在 Druid 中执行所需的查询以获取数据结果。
2、结果导出:将查询结果导出为 Druid 支持的格式,如 JSON 或 CSV。
3、使用外部工具:使用外部数据集成工具或脚本将导出的数据文件从 Druid 传输到数据湖。例如,如果 Druid 配置了 S3 作为深度存储,可以使用 AWS CLI 或 SDK 将数据从 S3 传输到 Amazon S3 数据湖。
4、数据转换:如果需要,对数据进行必要的转换以匹配数据湖中的数据模型或格式。
5、数据湖存储:将转换后的数据写入数据湖。这可能涉及到使用数据湖的API或SDK,例如使用 Hadoop DistCp 将数据复制到 HDFS,或使用 AWS S3 API 将数据上传到 S3。
6、元数据更新:更新数据湖的元数据存储,以反映新写入的数据。这可能需要使用数据湖的元数据管理工具或服务。
7、调度和自动化:考虑使用工作流调度工具(如 Apache Airflow)来自动化这个过程,确保定期将数据从 Druid 同步到数据湖。
请注意,这个过程需要在 Druid 和数据湖之间建立集成,可能需要开发自定义脚本或使用现有的数据集成工具。此外,根据数据湖的具体类型和配置,具体的实现细节可能会有所不同。
Doris 数据仓库如何改造成为湖仓一体
Doris 通过多源数据目录(Multi-Catalog)功能,支持了包括 Apache Hive、Apache Iceberg、Apache Hudi、Apache Paimon(Incubating)、Elasticsearch、MySQL、Oracle、SQLSserver 等主流数据湖、数据库的连接访问。以及可以通过 Apache Ranger 等进行统一的权限管理,具体架构如下:
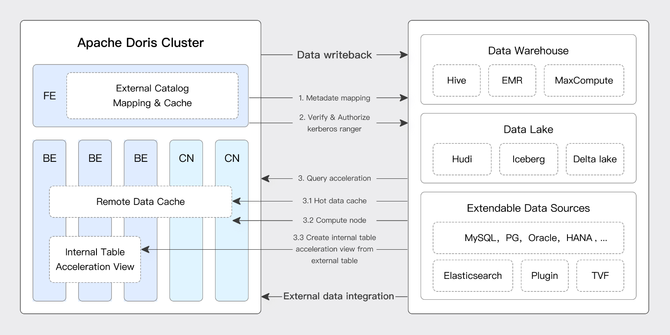
其数据湖的主要对接流程为:
1、创建元数据映射:Doris 通过 Catalog 获取数据湖元数据并缓存在 Doris 中,用于数据湖元数据的管理。在元数据映射过程中 Doris 除了支持传统 JDBC 的用户名密码认证外,还支持基于 Kerberos 和 Ranger 的权限认证,基于 KMS 的数据加密。
2、打通数据仓库和数据湖的数据查询:当用户从 FE 发起数据湖查询时,Doris 使用自身存储的数据湖元数生成造查询计划,利用 Native 的 Reader 组件从外部存储(HDFS、S3)上获取数据进行数据计算和分析。在数据查询过程中 Doris 会将数据湖热点数据缓存在本地,当下次相同查询到来时数据缓存能很好起到查询加速的效果。
3、数据结果返回到查询引擎:当查询完成后将查询结果通过 FE 返回给用户。
4、支持数据计算结果写入数据湖中:当用户并不想将计算结果返回,而是需要将计算结果进一步写入数据湖时可以通过 export 的方式以标准数据格式(CSV、Parquet、ORC)将数据写回数据湖。
基于以上doris 天然支持湖仓一体的数据架构,需要少量的自研可以完成。
Clickhouse 数据仓库如何改造成为湖仓一体
目前来说Clickhouse 作为数据仓库对数据湖的相关支持情况如下。
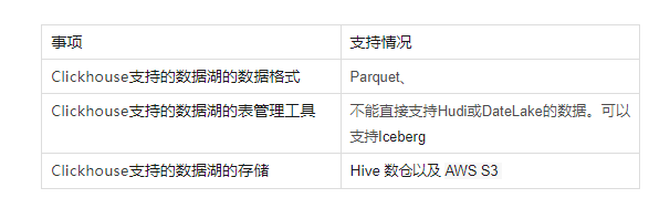
1、clickhouse 与数据湖的元数据采集统一管理,目前clickhouse 主要是通过摄取数据湖中存储的数据。例如,ClickHouse 可以配置为从 Amazon S3 或 HDFS 这样的数据湖存储中读取Parquet数据。但是,ClickHouse 本身并不直接管理数据湖中的元数据,而是依赖于数据湖自身的元数据管理机制。如果需要完成统一的元数据管理,需要额外开发相关功能。
如果需要从Iceberg数据湖中读取元数据并形成统一的元数据管理,可能需要以下步骤:
1)元数据模型抽象:构建一个抽象的元数据模型,能够表达 ClickHouse 和 Iceberg 的元数据结构,包括表结构、分区信息、数据位置等。
2)元数据服务开发:开发一个元数据服务,该服务能够与 ClickHouse 和 Iceberg 的存储后端进行交互,获取和更新元数据。
3)适配器实现:为 ClickHouse 和 Iceberg 分别实现适配器,这些适配器能够将它们各自的元数据转换为统一的元数据模型,并与元数据服务进行通信。
4)数据目录服务:实现一个数据目录服务,为用户提供一个统一的视图来浏览和搜索数据湖中的数据资产。
2、Clickhouse 从数据湖读取数据并写回到数据湖中,ClickHouse 原生并不支持直接查询或写入 Parquet 文件,因为 ClickHouse 有自己特定的数据存储格式和列式存储机制。不过,可以通过一些间接的方法来实现使用 ClickHouse 查询存储在文件系统(如 HDFS 或 S3)中的 Parquet 文件,并将结果写回到 Parquet 文件。
1)使用外部表:ClickHouse 支持外部数据源的查询,可以通过创建外部表的方式,将存储在文件系统中的 Parquet 文件作为数据源。这通常需要使用 ClickHouse 的表函数和外部数据源的 URL。
2)数据导入:在 ClickHouse 中创建一个临时表,并将 Parquet 文件中的数据导入到该表中进行查询。这可以通过 INSERT INTO ... SELECT * FROM ... 语句实现。
3)使用 ClickHouse 的表引擎:ClickHouse 提供了一些表引擎,如 File 表引擎,可以用于读取存储在本地文件系统或远端 URL 中的数据。然而,这些表引擎通常不适用于高性能查询。
4)数据转换工具:使用外部的数据转换工具(如 Apache Spark、Apache Hive 或 Trino)来读取 Parquet 文件,执行必要的转换,然后将结果写入到 ClickHouse 支持的格式。
5)使用 ClickHouse 的数据导出功能:在 ClickHouse 中执行查询并将结果导出为 CSV 或其他中间格式,然后使用外部工具将这些数据转换为 Parquet 格式。
6)自定义开发:开发自定义的连接器或适配器,用于在 ClickHouse 和 Parquet 文件之间进行数据转换和传输。
通过以上分析,clickhouse 和数据湖的数据交互也是需要额外开发,才能完成打通。
02
—
实施相关难度分析
从原生支持情况分析
默认情况下,从原生Doris、ClickHouse、Druid 三个组件对数据湖开源组件的支持情况来看,doris支持最好,Druid次之,最差的是ClickHouse,因此开发难度来是doris最容易升级成为湖仓一体,最难的是ClickHouse,设计到需要源码的修改。
从组件对湖仓一体发展支持上看
Doris、ClickHouse 和 Druid 都是数据分析和处理领域的重要开源项目,它们对湖仓一体架构的发展关注度各有不同:
1、Apache Doris:Apache Doris 社区对湖仓一体架构的发展非常关注。Doris 本身提供了多源数据目录(Multi-Catalog)功能,支持包括 Apache Hive、Apache Iceberg、Apache Hudi 等数据湖和数据仓库的连接访问。Doris 通过元数据缓存、数据缓存、Native Reader、IO 优化等技术,加速了数据湖分析能力,致力于实现数据在数据湖和数据仓库之间的无缝集成和流分析。
2、ClickHouse:ClickHouse 在字节跳动内部得到了大规模的应用和发展,字节跳动基于开源的 ClickHouse 进行了大量二次开发和深度投入,以解决实际业务场景的需求。虽然 ClickHouse 本身是一个高性能的分析型数据库,但字节跳动通过深度定制和优化,使得 ClickHouse 更好地适应了云原生和大数据环境,间接地支持了湖仓一体的发展趋势。
3、Apache Druid:Apache Druid 社区同样对湖仓一体架构表现出了关注。Druid 作为一个高性能的实时分析型数据库,其社区通过 Slack、GitHub 和邮件列表等多种渠道进行交流和讨论,积极开发新功能以适应不断变化的数据处理需求。Druid 的设计理念和技术特性使其能够支持湖仓一体架构中的实时数据分析和处理。
总结一下,通过目前支持的情况以及发展趋势来看,Apache Doris升级成湖仓一体最容易,次之是Apache Druid。最难是ClickHouse。

