实时的数据接入、实时的在线分析,实时数仓实现秒级数据摄入背后,有很多卓越的技术及方法在支撑海量数据处理,比如:计算和存储能力如何分离,如何结合Flink去直接消费Kafka,如何有效处理复杂数据,如何应对数据实时更新的一些需求,如何具备流批计算框架的集成能力……
在IT风向标“大数据技术-实时数仓技术”专场沙龙活动中,镜舟科技解决方案架构师负责人谢寅、阿里云Hologres产品专家丁烨、星环资深架构师陈潜龙、偶数科技解决方案高级总监张立群 四位重磅专家,从场景需求、技术变化以及方案创新角度分享了实时数仓架构实践心得。
综合大家观点,几位专家一致认为:实时数仓技术架构并不是孤立存在,而是在业务推动以及技术创新过程中逐渐演进而来。所以,无论是早期的分析型数据库、离线MPP数据库模式,还是现在的实时数仓、HTAP、云原生湖仓,本质上都是数据处理和分析的需求在推动,企业想通过更新鲜的数据来驱动业务决策,同时希望通过更高效、更可靠、更具性价比的现代化技术栈来满足数据消费需求。
简单理解,从早期偏固定分析的报表,到今天实时、自助的数据分析,从传统数仓建设到现在的湖仓一体,从存算一体到存算分离,虽然技术路线不同,但最终目标一致,那就是让企业的数据分析变得更快、更易用。
那么,领先企业是如何基于整个架构进行优化,打通整个数据链路瓶颈的呢?以下内容由ITPUB直播内容精编整理!
01
“存算分离+湖仓融合”带来数据分析新思路

要想实现存算分离,底层架构升级是必经之路。那么,镜舟科技的核心产品StarRocks是如何从shared-nothing 走向 shared-data的呢?
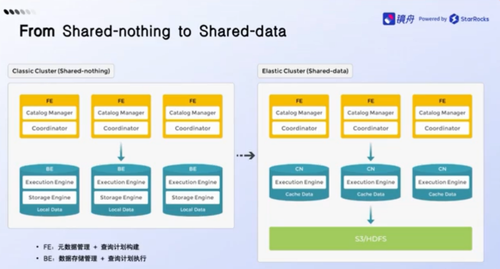
StarRocks2.0存算一体架构时代,整个架构非常简单,核心组件只有FE前端和BE后端节点,包括BE节点的向量化的执行引擎、列式的存储等等,主要承载原数据管理查询规划,实现高可用调度,保证横向扩展,同时充分利用多机多核的CPU资源,满足复杂的查询、分析等需求。
而在StarRocks 3.0时代的存算分离架构中,FE还是承担原来的角色,但把BE换成了CN节点,然后由原来本地文件存储系统把它推到这个共享存储上。客户可以使用Hadoop生态的HDFS,或者使用云上S3、OSS这些对象存储,作为StarRocks的共享存储来使用。
这种操作带来的直接好处是,使存储和计算解耦开来,客户可以按需去扩容计算节点或者是存储节点,让整体架构变得更经济、更灵活。比如:有些客户场景,虽然存了很多数据,但计算查询不多,不是很消耗资源;而有些场景,查询非常复杂,但数据量相对可控。这样的场景,特别适用于存储分离的架构。如果是存算一体的方式,进行集群扩缩容的时候,势必会造成资源浪费。
存算分离的价值是,它降低了计算和存储的成本。如果是存算一体,必须要满足数据的三副本,才能确保可用性。从存储角度来看,非常浪费资源。而存算分离架构下,一副本就能确保可用性,尤其在云上,可用性能够达到小数点后面11位。用户可以按照业务的峰值,包括高峰、低谷等特征灵活、弹性地进行扩缩容。
除了把BE变成CN节点,StarRocks存算分离架构还有诸多内核层面的增强,比如:可以在数据库的集群里抽象出不同的Warehouse集群,让Warehouse1的CN节点只专注于数据导入,Warehouse2去应对集群查询,Warehouse3去应对固定的报表看板,这样就可以把不同的workload有效隔离开。
通过对存算一体和存算分离两种架构的查询性能对比分析来看,发现开启本地文件系统缓存能显著提高查询响应速度,从而使得更多冷数据可以存储在对象存储中。此外,通过引入多仓库架构,可以根据工作负载需求动态分配计算资源,有效隔离不同类型的查询作业,减少资源相互影响,并实现数据资源的最优利用。
总之,通过存算分离技术,再结合湖仓架构,StarRocks实现了高效的数据处理和查询性能。为了提升数据处理效率,StarRocks引入了新的数据交互模式,包括入仓、入湖手段以及对外表的查询和建模,以适应不同场景下的数据需求。在这里,要特别强调统一Catalog管理的重要性,同时通过多Hadoop集群的支持,以及简化数据交互和联邦查询的过程,可提升查询性能,降低了从传统架构向湖仓架构的迁移成本。
02
实时数仓为大数据分析注入新活力

从传统的统计分析,到人群的运营,实时数仓正在承载更多的服务场景,比如:BI报表、实时大屏、个性化推荐、智能客服等。
以阿里CCO为例,实时数仓架构从1.0时代“End to End”应用场景发展到2.0时代,这时候的架构大量引入了OLAP的能力,有了数仓分层的概念,需要全员参与实时开发。进入3.0时代,其典型特征是流批一体。相比于传统的Streaming Warehouse架构,基于Hologres + Flink的实时数仓3.0架构能够更好地支持高性能的写入和更新,并且能够解决数据探查和修正的问题。此外,3.0架构还提供了多种原表的读取模式,支持围表关联和数据打宽等多种场景。
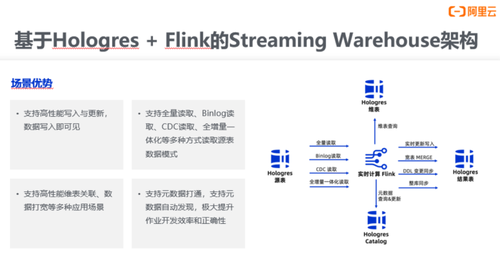
在DWD实时构建层面,传统多源头数据采集加工成实时大宽表,只能依赖Flink的多流JOIN能力,无法使用维表关联方式,成本高且复杂。而基于Flink+Hologres方案,可以使用部分列更新的能力,多条流同时写大宽表,且每条流仅更新部分列,实现实时大宽表,从而简化操作,同时节约计算成本。
Hologres也支持DWD的离线构建,在最新发布的HologresV2.2版本中,Serverless Computing这种独立的资源使用方式,可将ETL使用全部托管,这种方式不仅有效提升大任务的稳定性,同时可降低20%计算成本。
另外,Hologres和Flink在元数据上是互通的。以某电商客户为例,该客户将业务数据存储在MySQL中,包括订单、支付等数据,这些数据可以通过Flink CDC同步到ODS层、DWD层,并最终对外提供服务。在ODS层的实时同步中,只需一条SQL语句就能轻松实现整库同步。此外,Flink还与Hologres深度打通,实现了原数据的自动发现和自动管理,避免了传统方式中的任务停启和修改下游数仓Schema等问题。
在DWS实时聚合层,Binlog是Hologres很有特色的新能力,它让Hologres不再只是数据的终点,也是起点。
Hologres的Binlog,类似传统数据库的Binlog,支持对每次数据更新的详细记录,包含了INSERT、DELETE、BEFORE UPDATE、AFTER UPDATE四种时间类型。通过binlog,用户可以驱动事件的实时加工,该功能有多种使用场景,包括数仓层次间数据实时加工,通过Binlog实现数据在层次之间的连续加工(ODS->DWD->DWS->ADS),支持数据在实例间的实时同步,比如:从公共层实例到业务层实例的实时同步Shared Instance->Application Instance,也可以用于数据行列转换。最后,还有监控数据的变化,通过Flink和Hologres Binlog的组合关系,支持了有状态的全链路事件实时驱动开发场景。
在存储方面,过去针对主键点查场景,推荐使用行存,行存采用KV存储方式,支持高QPS场景。而在OLAP统计分析场景,推荐使用列存,列存天然具备高效率的过滤、压缩效果,也是Hologres的默认存储。但实际使用场景往往更加复杂,有时无法提前定义,因此Hologres支持了第三种存储模式,行列共存。一张表同时具备行存、列存之前各自优势的场景,由查询优化器根据查询特征,选择最适合的存储引擎,存储引擎自身保证两类存储之间的读写一致性。这种存储方式也让非主键高性能点查成为现实,列存此刻扮演了行存的类似二级索引的效果。
03
实时湖仓平台的探索与实践

随着数据量的不断增加和业务需求的变化,传统的数据仓库已经无法满足需求,因此出现了数据湖的概念。数据湖提供了更加灵活的数据存储方式,并且可以实现整个数据的统一存储和管理。同时,传统数据仓库的局限性也越来越明显,例如处理大规模数据时面临的时效差问题等。因此,出现了以湖仓为中心的新一代架构,可以提高数据处理效率并提供更多丰富的数据分析手段。
湖仓一体是一种新的数据存储和管理架构,它打破了传统数据仓库和数据湖之间的界限,实现数据的统一存储管理和分析。这种新型架构不仅整合了多种数据模型,还提供了丰富的数据分析工具来满足不同的业务场景需求。湖仓一体架构的核心优势在于,具备通用性和扩展性。同时,为了实现实时的能力,实时湖仓平台能够实时接收并处理来自多个渠道的不同类型的数据,包括传统的关系数据库、新兴的数据库和流数据等。
更重要的是,湖仓一体平台可以通过统一的计算引擎平台来支持多种数据模型,包括结构化和非结构化数据,并提供跨库查询分片的能力,从而实现不同模态数据的融合分析和流转。
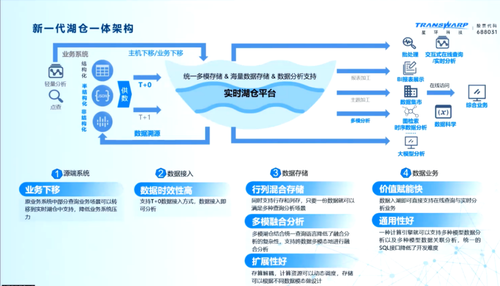
星环云原生实时技术架构涉及数据实验室、多租户AI融合等不同业务场景下的能力需求。在该架构中,数据处理底座采用了四个统一的设计理念,即统一的查询语言、统一的计算引擎、统一的存储管理和统一的资源管理,通过这四大能力为用户打造一体化数据底座。此外,在数据接入和共享方面,星环也有很多工具和具体方法,如使用开源工具将不同类型的数据接入平台,并可以将数据共享到外部存储或进行联邦分析。
具体而言,星环实时湖仓平台的优势和特点是:1)具有实时入户的查询与分析能力,可以快速地进行结构化数据的分析和查询;2)它支持多模态数据的管理,可以通过统一的数据入口、计算引擎和资源管理来支持多种类型的模型,并且可以通过 SQL 完成不同模块数据之间的关联分析;3)采用了行列混存的技术,可以在同一张表中同时支持行层和列层,从而对不同的业务进行兼容支持;4)支持标准 SQL 存储过程的兼容,可以使用统一的查询语言来支持不同异构数据库,如 Oracle 数据库等。这些特点使得星环实时湖仓平台成为一个高效、灵活、可靠的数据处理平台。
以某期货交易所监查场景为例,这是一个“对敲”监管业务,原有的业务是构建在内存库Timesten+历史库Oracle的数据库平台上。Timesten需要从Oracle历史库中读取前天和昨天两天的数据,用作告警分析的基础历史数据,Timesten在业务处理中需要承载当天增量数据的实时入库与加工,包括双开/双平数据的筛选、交易数据的聚合等,对于分析出的告警内容,存储到Oracle历史库中,方便监查系统事后查看。
对于用户的数据来说,它需要去从内存库里面把数据拿出来,去跟历史库做一个数据对比。整个过程链路复杂,在延时以及数据处理的效率层面,压力比较大,没有办法去满足客户对数据的处理需求。基于星环提供的实时湖仓方案,可以把所有的数据全部集成在一个库里,通过Slipstream这样的实时入库的方式,增量数据直接入到ArgoDB里。方案优化过后,整体架构变得更简单,并且实现了流批一体,增量与存量直接关联,高吞吐,低延时,性价比高。
04
全实时架构的实现原理和用户价值

企业在构建数据平台过程中,通常会遇到五大难题,包括:数据孤岛、查询性能无法满足业务需求、高并发复杂查询分析问题、无法按需实现实时查询、数据安全性和隐私保护以及敏捷资源弹性管理面临挑战。这些问题都是企业在选择和使用数据平台时需要考虑的重要因素。如果一个数据平台能够在这些方面都有很好的解决方案,会极大地提升数据分析能力和用户体验。因此,了解这些问题并找到合适的解决方案对企业的发展非常重要。
偶数实时数据处理解决方案,是基于基于云原生技术进行深度优化,采取计算、存储分离的技术架构,充分适应云上数字化应用对高度弹性、无限扩容能力的要求,保证数据服务能力高可用。整个方案由核心产品Oushu Database新一代云原生数据仓库,以及Oushu Lava数据管理平台、Oushu LittleBoy自动化机器学习平台构成。
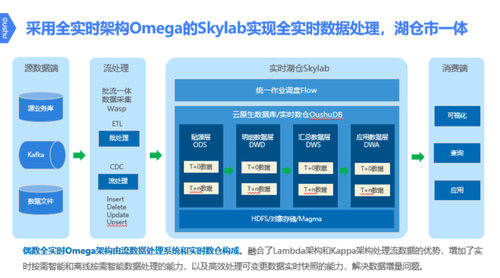
实时湖仓平台Skylab是存算分离、一份数据、支持多个计算引擎的创新架构,可满足用户实时湖仓一体需求。Skylab平台支持多类型数据、数据一致性、一份数据、云原生、超高并发以及实时T+0等六个特点。同时,该平台提供了多种解决方案,如数据开发平台、标签平台、BI分析共享平台、资产管理数据机制、机器学习平台、实时数仓、离线实时湖仓一体、大数据、跨库融合等等。另外,该平台还能够为基于大模型创新应用提供更强的支持。
值得一提的是,偶数独创架构Omega,是在新的按需智能需求(On-demand Intelligence)出现以后,由偶数科技2021年5月提出的新一代全实时数据处理架构。该架构由流数据处理系统和实时数仓构成,融合了Lambda架构和Kappa架构处理流数据的优势,增加了实时按需智能和离线按需智能数据处理的能力,以及高效处理可变更数据实时快照的能力。
综合而言,偶数全实时数据处理解决方案,对大数据处理架构创新带来了深远影响,能更好地满足实时湖仓平台的技术要求。
05
写在最后
实时数仓以其独特的优势,正逐渐成为企业数字化转型、实现数据驱动决策的关键基础设施,对于提升企业竞争力具有重要意义。在这一过程中,实时数仓架构的演进,既是一场技术革新,也是大数据平台思维的飞跃。把握好“道”与“术”的结合,即在正确的理念指导下,运用恰当的技术手段,方能打造出既高效又可靠的实时数据处理平台,为企业的智能化升级注入强大动力。

