在2024年流数据处理领域,Apache Kafka 仍然是业内的事实标准,原因是该技术已经被超过100,000个组织或者企业使用。Kafka 的广泛普及和成功应用吸引了大量供应商加入,很多企业纷纷基于提供基于 Kafka的平台或者云服务产品。同时,许多与Kafka 互补的开源流处理框架如 Apache Flink 以及相关的云服务也如雨后春笋般涌现。此外,一些竞品技术如 Pulsar、Redpanda 以及 WarpStream 也试图通过利用 Kafka 协议来抢占市场份额。

本文梳理了2024年流数据发展现状,目前市场上有哪些成熟的解决方案,未来发展趋势是什么,并对2025年潜在的市场发展前景进行预测。
由实时数据发展带来的变革
“实时数据的价值胜过慢数据”,这种观点可以适用于任何行业的任意场景。换句话来说,流数据处理技术并不是凭空而降,而是实时数据需求驱动下的产物。流数据可以更好地满足用户实时消费数据的需求,能够提升用户体验,最终达到降本增效的目的。
目前,流数据处理能力已经被引入各个数据场景。比如:数据库场景,可以用于存储和执行事务性工作负载;数据仓库场景,可以处理结构化历史数据,并用于创建定期报告,提供独特见解;数据湖场景,通过批处理来处理结构化、半结构化或非结构化的大数据集,同时也可以创建定期报告,提供相关见解;湖仓一体场景,让数据仓库和数据湖完美结合,可以在单一平台上处理所有数据;流数据处理,持续处理变化中的数据,并在不同的通信范式(如实时、批处理和请求-响应)之间提供数据一致性,而不仅仅是存储和分析静态数据。
值得一提的是,不同数据平台并不是非此即彼的关系,有时候会是各种平台的结合体。至于,如何构建出适合企业自身业务发展需求的数据平台?当数据仓库、数据湖与流数据处理等各种概念搅合在一起,我们如何正确区分与理解?如何有效利用流数据处理技术把数据高效地摄取到数据仓库或者数据湖中,并且要确保数据的实时性和准确性?如何实现数据仓库的现代化技术栈部署,把数据从本地迁移到云原生基础设施环境中……面对数据处理的诸多常见问题,我们可以基于前人的经验去总结、探索实践路径。
如前文所述,本文将重点分析流数据处理相关问题!那么,流数据处理发展现状到底如何呢?全球权威调研机构Forrester,在数据管理平台Wave报告中进行了数据分析,报告指出Microsoft、Google和Confluent处于领导者象限位置,而紧随其后的是Oracle、Amazon、Cloudera和其他几家公司。我们暂且不去评价各个供应商的名次问题,单就数据管理而言,流数据管理更能代表未来,与ETL/ESB/iPaaS等技术理念一样,成为企业数据管理的重要演进方向。
流数据市场格局与最新变化

目前,主流管理软件企业都在围绕流数据进行新的战略部署。数据显示,很多企业都在基于Kafka或者相关协议支持业务,Apache Kafka已经是流数据处理的事实标准。当然,Kafka并不是实现流数据处理的唯一方式,有些企业是通过Kafka协议来实现同样的能力,比如:Azure Event Hub,原生支持高级消息排队协议 (AMQP)、Apache Kafka 和 HTTPS 协议;Amazon Kinesis,则通过完全不同的API用于对大型分布式数据流进行实时数据处理。

从流数据发展的生态层面来看,大概分三类:
第一,原生Apache Kafka。利用开源框架进行实时消息传递以及事件存储,Kafka API 100%兼容,但不包括Kafka Streams和Kafka Connect。
第二,Kafka协议。利用协议实现自研,但支持Kafka API,一般这类产品通常不是100%兼容,Kafka Connect和Kafka Streams通常不是产品的一部分。
第三,流处理。类似的框架和云服务以无状态或有状态的方式关联数据,解决方案要么是Kafka原生的,支持Kafka协议,要么完全独立运行。
虽然,Apache Kafka是事实数据处理的事实标准,但不是流处理的唯一选择,市场上也存在许多可以互补甚至是竞争关系的技术。
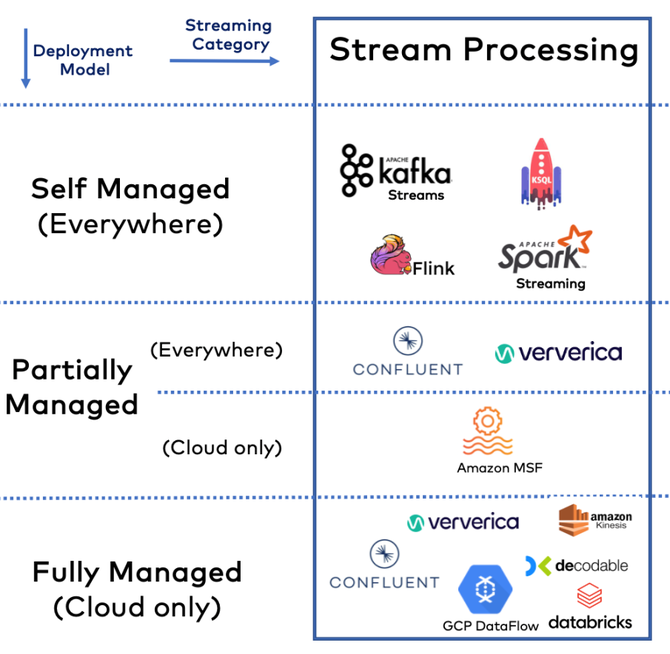
与Apache Kafka类似的诸多竞品技术:
1. Apache Pulsar
作为Apache Kafka的竞争产品,Apache Pulsar最初由Yahoo开发并在2016年开源,在Apache基金会下孵化。Apache Pulsar和Apache Kafka有相似的故事和用例,但有着不同的体系结构。Kafka是一个分布式消息队列——在2022年移除对ZooKeeper的依赖之后。Apache Pulsar借助Pulsar brokers 、ZooKeeper和BookKeeper主攻分布式集群,但因为起步太晚,失去市场先机。
2. StreamNative
StreamNative由 Apache 软件基金会优秀项目 Apache Pulsar 创始团队组建而成,围绕 Pulsar 打造下一代云原生批流融合数据平台。但StreamNative Cloud仍然处于非常早期阶段,不确定未来发展,是否具备进一步增强的能力。
3. Redpanda
Redpanda是一个相对较新的流数据市场进入者,能处理高吞吐、实时数据流。这家公司用c++重新写了Kafka,做到了API的兼容。个人认为,Redpanda并不是Kafka的替代品,只是处于早期发展阶段,还不够成熟,未来需要找到差异化发展路线。与Apache Kafka相比,Redpanda没有明显的差异化价值,但也没有什么风险。
4. Azure事件中心
Azure事件中心是一种基于云原生的流数据处理服务,该服务只做一件事,而且做得非常好,那就是通过Kafka协议摄取数据。因此,它不是一个完整的流媒体平台,更类似于Amazon Kinesis或Google Cloud PubSub。用户仅在公有云Azure云上可用。但Azure事件中心有两个阻碍其发展的缺点:一个是与Kafka协议的兼容性有限,并不是100%;另一个是服务成本太高,价格昂贵。
5. WarpStream
WarpStream是一家云原生流数据基础设施提供商,同样属于流数据市场的后起之秀。这家公司提供的服务直接构建在S3之上,对于某些Kafka用例来说非常适用,能更好地解决延迟问题。但是否能真正解决用户问题,只有用时间去证明。对于那些声称可以兼容Kafka协议的供应商,我们需要持谨慎的态度,其中不乏有夸大其词的企业。
Kafka与Apache Flink的竞争
除了上面的竞品,业界对于Apache Flink的创新与发展也广为关注。有意思的是,从2022年开始,Kafka把年度峰会的主题改为下一代技术峰会,会上会展示很多竞品技术,包括会有一些补充技术,希望能够通过全球社区和企业的多样化发展壮大流数据生态,这说明Kafka并没有认为自己是流处理的唯一选择。
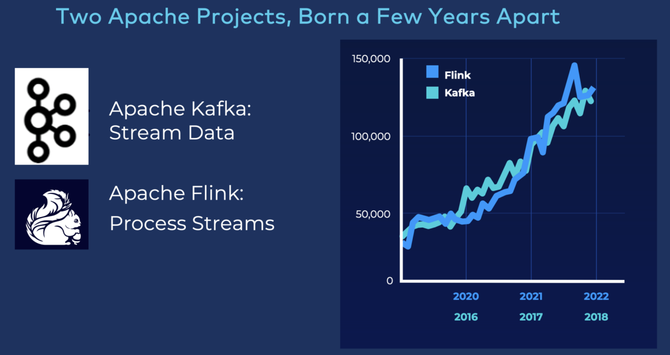
作为流数据处理的另一款代表产品,Apache Flink大有后来者居上之势,发展势头与几年前的Kafka非常相似。很多人认为,Apache Flink才是流处理的事实标准!但在笔者看来,Flink虽然发展迅猛,但不会完全取代Kafka,两者在一段时间里,会是一种并行存在关系。Kafka在原生流处理能力的强大之处,包括广泛用例,决定其依然占有重要市场地位。不管是哪种技术路线,都各有优缺点,没有一款流处理技术能一统天下。
以下是可以对Kafka进行技术补充的方案:
1、 开源流处理框架
1)Kafka Streams
如果你从Apache网站下载Kafka,它总是包含Kafka Streams这个库,这是Apache Kafka提供的一个轻量级流式处理框架,其输入输出均存储在Kafka集群中。部署Kafka Streams的好处是,这是一个开源、健壮、技术水平较高、可平行扩展的消息传递系统。
2) ksqlDB
ksqlDB是一款事件流数据库,是一种基于Kafka的实时数据流处理引擎的特殊数据库,它提供了强大且易用的SQL交互方式,以Kafka数据流进行处理,而无需编写代码。ksqlDB的技术原理是,在Kafka Streams之上构建流处理应用,提供流式SQL能力。因此,ksqlDB也是kafka原生应用,并且采用Confluent社区许可授权,可以免费使用,其亮点是流式ETL处理能力。
3)Apache Flink
领先的开源流处理框架。功能强大之处在于,具有可扩展的计算引擎(与Kafka分离),使得开发人员可以在ANSI SQL, Java和Python之间自由选择,包括拥有能对复杂事件进行处理(CEP)的API,以及可以支持流和批处理工作负载的统一API。
4)Spark Streaming
作为开源大数据处理框架Apache Spark的一部分能力,Spark Streaming与Apache Flink一样,是流处理的卓越选择。Spark Streaming 可以处理来自多种数据源的数据,如 Kafka、Flume、Kinesis 等,并将连续的数据流拆分成一系列离散的数据批次,每个批次的数据可以在 Spark 引擎上进行处理,类似于批处理作业。
2、 流处理解决方案提供商或者云服务商
1) Ververica
众所周知,Apache Flink是业界公认的性能优异的大数据实时计算引擎之一,除了Apache Flink社区的参与贡献外,还与其商业公司 Ververica(原名:dataArtisans)密切相关。2019年,Ververica被阿里巴巴收购,Apache Flink自此在亚太市场得到快速发展。
2) Decodable
这家企业提供的是以Flink技术为核心的流数据处理平台,主要利用SQL来对流数据进行加工、处理,我们可以把它看成是一个Flink SQL的云服务。如果把Decodable与企业中现有的Kafka基础设施相结合,发展潜力巨大。企业通过Decodable不仅解决了流数据处理问题,同时也为非kafka系统提供了一个预构建的连接器。
3)Amazon Managed Service for Apache Flink (MSF)
一项由AWS提供的(几乎)完全托管的服务,允许客户使用Apache Flink实时转换和分析流数据。但是,在自动扩展方面存在差距,需要付出高昂的成本,并且这不是一款无服务器产品,只是支持所有Flink接口,使得用户可以通过SQL、Java和Python等进行业务开发,这和很多非kafka连接器路径,在实现原理上大同小异,仅适用于AWS用户使用。
4)Confluent Cloud
一个真正的无服务器Flink产品,用户可以弹性扩缩容,如果不使用,资源可以自动降为零。最初,Confluent Cloud只支持SQL,到了2024年,已经演进到可以支持Java和Python。该服务部署在AWS、 GCP和Azure上,与完全托管的Kafka、Schema Registry、Connectors、Data Governance和Confluent的其他功能深度集成。目标是,为流数据处理提供一站式、端到端的开发体验。
5)Databricks
Databricks是Apache Spark背后的服务商。虽然,今天已经很少有人在提Spark,但Spark依然是Databricks云平台的关键技术。目前,Databricks的发展方向是,除了与人工智能、机器学习平台等新技术环境进行结合,也会基于一些集成环境进行方案部署,比如Databricks可以与任何Kafka环境集成,或者通过Amazon MSF直接连接到Confluent Kafka。
写在最后
整体来看,流数据处理还处于初级发展阶段。虽然一些成熟软件公司或者云服务商都在部署相关路线,但似乎很难出现一家独大的产品。不管是流式数据库,还是流式数仓,都在基于以往优势,引入流数据处理的能力,提升用户体验。比如:MongoDB或Snowflake,他们的关注点在于,引入流数据处理能力(例如:通过CDC技术),实现实时数据的同步,而不是与提供流数据处理解决方案服务商进行直接竞争。
总结而言,流数据处理不是一场群雄争霸大赛,而只是一段旅程。不管是Apache Kafka,还是Apache Flink,要想获得更长远发展,都要在用户价值上下功夫。放眼未来,真正满足用户需求的流数据处理平台,不仅在架构、开发、部署和监控等方面进行思维转变,还要考虑复杂环境的集成和应用问题,包括与云原生、微服务的结合,实现混合云与多云环境的数据共享等。

