开源大模型上演神仙打架,Meta Llama3.1与Mistral Large 2该怎么选?
这两天,开源大模型真是杀疯了。昨天,Meta宣布推出封神版大模型Meta Llama3.1;今天,后起之秀Mistral表示参战,推出旗舰版模型Large 2。两款大模型推出后,一大堆供应商都表示快速支持。对于用户来说,此刻可能是一片懵的状态,大模型真是变化太快了,感觉永远在被带节奏。
面对各种大模型,到底该如何选择?听听专家怎么说!
“开源软件和模型的共同开发现在成为常态。对我们来说,只花了几分钟修改了一点 Python 代码就能支持 405b。”Lepton AI 联合创始人兼 CEO贾扬清,通过自己的朋友圈分享了最新观点。他认为,支持开源大模型,现在变得很容易。但从快速推广和应用视角来看,个人更期待Mistral Large的未来发展。
以下为原文观点:
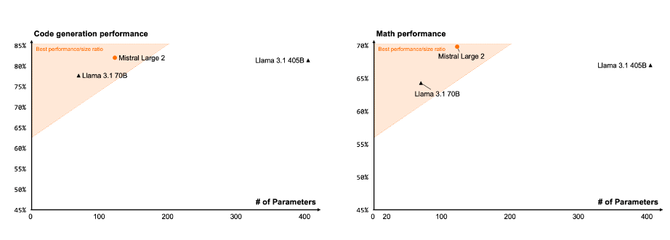
Llama3.1 405B 的性能测评,数据来自 LLM 聚合平台 OpenRouter:
看到几乎所有提供商都迅速支持这个模型,很惊喜。开源软件和模型的共同开发现在成为常态。对我们来说,只花了几分钟修改了一点 Python 代码就能支持 405b。
Llama 3.1 405B 确实是一个难盈利的模型。需要半台或一台机器来运行,成本很高,速度还一般。大多数提供商保持在每秒 30 个 token 左右(见图),以确保服务经济合理。相比之下,70B 模型可以超过每秒 150 个 token。
你还是能盈利的,不是纯亏钱。当然,这取决于良好的优化和工作负载饱和度。对我们的 VC 朋友们来说,对于这种价格的纯 API 服务,不要指望能像传统 SaaS 那样有 80% 的利润率。
除了性能优化,LeptonAI API 在速度、价格、并发、成本等多个参数之间做了平衡,以确保可持续性。
量化将成为标准。各位,忘掉 FP16 吧。Int8/FP8 才是未来。如果你还觉得不舒服,让我告诉你,早些时候 AI 框架还担心精度,甚至支持 FP64。你在神经网络中用过 FP64 吗?
量化需要小心。一个尺度适用于整个张量的时代已经过去了。你需要做 per channel / grouped 的量化以确保准确度不下降。
我大胆预测,405B 的采用仍会受到速度和价格的限制。但我并不担心,因为我预计未来一年左右会有至少 4 倍的效率提升。
我很期待测试 Mistral Large 123B。我们的 Tuna 引擎开箱即用支持 Mistral Large,不过为了尊重研究许可,我们不会提供公共 API。如果你感兴趣,请联系我们。
@karpathy 有一条关于小模型的超棒推文。我完全同意。在垂直应用中,你可能不需要那么大的模型。70B 通常就足够了,很多情况下 8B 通过微调也能很好地工作!
很棒的是,Llama 3.1 允许(并在某种程度上推荐)微调你自己的模型。
我还想给 vLLM 点个赞。我们有自己的引擎,但 vLLM 真的很棒。我们的平台也支持它。
最后,欢迎联系我们进行企业/专用部署。我们相信 AI 不仅仅是 API。Lepton AI构建了一个完整的 AI 云来满足你端到端的需求。

