探索Serverless架构下企业资源降本增效的新路径
几年前,如果有人提Serverless这一概念,很多人会认为这是公有云厂商为了卖云服务而包装出来的一个“兜售概念”。但是现在,Serverless已演进为一种新型架构,是云原生发展的终极方向,该架构已被广泛应用于大数据、数据库场景。
那么,Serverless架构为什么会成为主流云厂商一定要部署的新赛道?对于广大用户来说,是在怎样一种业务场景下走上了Serverless之旅?
在IT风向标“Serverless时代下,企业资源降本增效思考与相关实践”专场沙龙活动中,成章数据CTO张桓、枫清科技(Fabarta)图计算负责人王传阳 两位重磅专家,从应用需求、技术变化以及方案创新角度分享了Serverless架构实践心得。
01
从数据基层看Serverless数据库降本增效实践
想象一下,传统IT架构如同一条繁忙的街道,服务器如同路上的车辆,无论是否需要,它们都在不断运行,消耗着宝贵的能源与资源。而Serverless架构,则像是一位精明的城市规划师,重新设计了这条街道,让“车辆”(即计算资源)只在真正需要时才会出现,完成任务后即刻消失,不留痕迹,极大地提高了资源利用效率,降低了运营成本。

所以,Serverless架构能被用户认可,主要原因只有一个,那就是企业不再需要为闲置的服务器资源买单,也无需担心因业务波动导致的资源不足或过剩问题。Serverless以其按需付费、自动伸缩的特性,为企业资源管理带来了前所未有的灵活性和效率,让企业可以根据业务需求实时分配资源,确保每一分投入都能最大化实现价值。
尤其在当前企业业务不断进化的环境下,数据管理变得越来越复杂。对于承载数据的重要应用——数据库系统来说,如何应对不断增长的数据量,满足更高效的实时性要求?成章数据从数据基层以及模块化数据库方式助力传统数据库开启企业降本增效新篇章。
“Serverless数据库应用非常广泛,最典型场景,比如:广告行业用户的存储,其实非常适合使用Serverless数据库。” 成章数据CTO张桓 在主题演讲中表示,用户需求和Serverless技术本身的特性,是Serverless数据库高速发展的“助推器”。
他以美国的一家SaaS媒体公司Canva为例,具体介绍了传统MySQL数据库面临的挑战。当可扩展性和性能走到一个瓶颈,企业需要把数据库迁移到Serverless的TP型的数据库,也就是通过DynamoDB去解决他们的痛点问题。
众所周知,DynamoDB是亚马逊在2007年开始在内部使用的一个数据库,后来成为一个可以在云上提供服务的数据库产品,并且是Serverless模式,用户不需要创建多少个VM去承载数据库,只需要指定多少流量,就能开箱即用。比如:TPS写入流量是多少,存储流量是多少。即便是PB级以上数据,也可以确保性能稳定,拥有个位数毫秒的写入和查询的延时。
亚马逊为什么会推出Serverless数据库?其实内行人士应该不难理解,这是“去O”推动的结果!此前,亚马逊使用了7500个Oracle数据库,后来这些数据库都被Aurora、DynamoDB数据库替换掉。传统的思维方式是,Oracle数据库是SQL数据库,一般用SQL、MySQL或者Aurora去替换,但是亚马逊在自己的实践中,采用了不同的策略,那就是将大量的数据库迁移到了DynamoDB上面,这样做的好处是,性能提升了40%,成本有60%的下降。
DynamoDB有很多优点,但用户在真正使用DynamoDB的时候,或者说在部署类似于Serverless数据库的时候,会遇到很多痛点问题。
1.在大负载的情况下,价格昂贵。当用户流量很低,使用DynamoDB会很便宜。但是,当我的数据量变大、流量增加,要比部署纯内存的Redis服务还要贵。并且,Redis能提供亚毫秒级的访问延时,而DynamoDB的延时是毫秒级,相对来说慢很多。
2.访问延时跟不上业务需求。从TP产品角度来看,DynamoDB的访问延时算不上非常优秀,读取一条数据达到3毫秒,写入数据甚至达到5毫秒以上。对于敏感业务来说,这样的速度显然无法满足需求。因为,不管是MySQL,还是Redis,性能都可以做到微秒级。
3.一致性的缺失。在“多key”事务场景下,对事务的数是有限制的,只能有100个key,一般主表没有问题,但对于二级索引来说,如果你写入的数据的二级索引还没有建好,会发生很多状况,如果对DynamoDB不太了解,就会出现最终的一致性问题。
4.对云厂商过度依赖。用户一旦上了DynamoDB的车,再想下来,是一件困难的事情。在迁移到云上的时候,亚马逊会帮你把业务从MySQL或者PG上迁移到DynamoDB上,但如果你想下云,换一家云服务商,过程会很曲折。
为了解决Serverless数据库的诸多问题,很多企业都在做相关的努力,推出各种解决方案。
第一种方案:提供DAX缓存服务。以亚马逊自己为例,DynamoDB提供了一个全托管的缓存服务叫做DAX,主要目的是为了提升性能、减少延时。假如用户想要微秒级延时,就可以通过VPC里面的DAX Cluster来实现。实际上,所有用户应用的写入都是和DAX在做交互,这是一个一写多读的系统,写入DAX之后就可以返回给用户,实现微秒级响应。
第二种方案,使用其他厂商的缓存服务。这种方案把缓存作为服务和DynamoDB的价值实现了互补。当用户写入一个数据的时候,可以通过Serverless的一个Lambda对数据进行处理,Lambda会负责写入到DynamoDB里。
第三种方案,实现NoSQL向SQL的一个转换。其实,亚马逊自己也推出了SQL级的数据库,Aurora的Serverless版本已经从V1发展到V2,这种使用标准SQL数据库的方式,极大地避免了额外的开发成本,降低学习成本,但同样的问题是,当数据量很小的时候,能够有比较好的效果,能实现亚毫秒级的延迟,但数据量变大的时候,性能无法满足需求。
分析来看,不管是哪种解决方案,都只解决了一个点的问题,无法从根本上解决Serverless数据库的所有痛点。比如:DAX虽然解决了更低的延时,但是DAX把一个传统的多写的Serverless数据库变成了一个单写的Serverless数据库,单写成为整个DAX的瓶颈点,并且在读的时候一致性很差。其他缓存服务也一样,在一致性问题上甚至比DAX还要严重,同时还有额外的开发成本。Aurora Serverless回归到一个单写的SQL数据库,当流量变高的时候,传统数据库写入流量不够的时候,通过Serverless数据库会解决规模化应用问题。但Aurora Serverless在实际应用中,需要采用分库分表等方案去做,依然存在痛点问题。
综上而言,要想真正解决Serverless数据库的挑战,需要一个完全解耦的架构,这和传统意义上的存储分离并不相同。用户在流量很低的时候,可以将资源消耗降低到0。但当流量进来,可以在一个热的池子里,用CPU和内存去管理用户过来的流量请求。当流量变大,热数据增多,可以先做扩展,用更大的内存节点、更好的CPU机型,根据实际应用做动态调整。
成章数据提出的Data Substrate架构,将数据库抽象成三层。对于用户来说,能在不牺牲性能的前提下,将数据库的基础功能统一,通过解耦的方式把具备不同功能的模块进行组装,快速构建一个能适应不同场景和应用的数据库,更好满足用户日益复杂的数据管理需求。
02
离线图计算服务在Serverless的探索
随着Serverless时代的到来,从数据库到数据分析都在推进 Serverless 进程。但是,对于离线图计算服务这样的个性化场景,该如何支持Serverless?相信很多人并不了解!
“离线图计算场景需要并天然适合Serverless架构。”枫清科技(Fabarta)图计算负责人王传阳,对离线图计算场景做了具体描述。
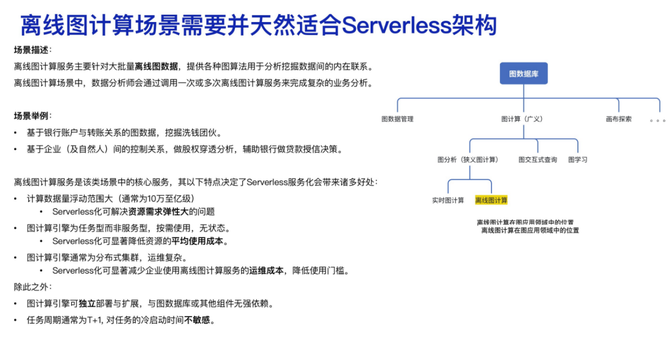
最近几年,我们经常听到关于图数据库的一些进展,包括国内外的开源社区、各种圈子,讨论比较热烈。图数据库一般分为图数据管理和图计算,而图计算又细分为图分析,包括交互式分析以及图学习。针对图分析场景,用简单、粗暴的方法来理解,就是实时的图分析和离线的图分析。
所谓“离线图分析”,通常指的是针对大批量离线图数据,提供各种图算法用于分析挖掘数据间的内在联系。比较典型的离线图计算场景当中,数据分析师会通过调用一次或者多次离线图计算服务来完成复杂的业务分析。
举两个例子:一、基于银行账户与转账关系的图数据。金融场景里,银行账户和转账关系,相当于是图里面点和边的关系,可以从中挖掘出洗钱团伙,适用于一些反欺诈、反洗钱业务;二、基于企业(或自然人)之间的控制关系,比如:股权穿透分析,对上层以及最上层控股权比例控制关系进行分析,辅助银行做贷款授信决策。
仔细梳理发现,离线图计算服务的诸多特点决定了Serverless部署会有更好的表现:
1.数据量大,并且计算数据量浮动范围大。在离线图计算场景中,数据量一般是10万至亿级,不同的数据分析导致计算浮动很大,相对应的资源需求就会非常大,如果实现Serverless化,很明显可以解决资源的弹性伸缩问题。
2. 图计算引擎为任务型,而非服务型,按需使用,无状态,Serverless可显著降低自愿的平均使用成本。
3.图计算引擎通常为分布式集群,运维复杂。Serverless可减少企业使用离线图计算服务的运维成本,降低使用门槛。
除此外,图计算引擎可独立部署与扩展,与图数据库或其他组件无强依赖。任务周期通常为T+1,对任务的冷启动时间不敏感。
那么,在离线图计算服务场景下, Serverless化服务模式到底是怎样的?
首先,终端用户必须要提供数据,把数据传到云存储上。其次,用户可以提交一个自定义的算法包,也可以直接调用图计算引擎所提供的内置算法,然后通过图计算的任务去触发图计算引擎,处理刚刚上传的数据,使用模式非常简单。作为用户,他只需要关注他的数据和计算任务。
总结来看,Serverless化服务模式对图计算引擎的能力要求较高,包括具备灵活的扩缩容能力、内置丰富的算法、兼容多种数据源与数据格式、支持图计算任务并行。图计算引擎需要具备较准确的资源需求模型,以提供给云资源管理模块用于分配相应资源给图计算引擎。图计算引擎的资源需求模型通常包括内存和CPU两个部分,CPU资源关系到计算任务的快慢。内存资源关系到计算任务能否成功运行。内存资源需求通常来自载图和算法运行两方面。图计算引擎需要具备清晰且稳定的图数据内存结构,并合理设计数据访问接口,支撑算法运行。
03
写在最后
在云计算、大数据、人工智能融合发展背景下,Serverless不仅带来了成本上的节省,更促进了开发运维一体化(DevOps)文化的形成,加速了产品迭代速度,增强了市场竞争力。当然,Serverless并不是“万 能钥匙”,适用于所有场景,到底能不能实现降本增效目标,还要取决于用户的业务。如果你的冷热数据或者你的流量波谷期很长,Serverless服务模式肯定是首选;但如果你的业务都是热数据,你可以选择私有云环境去部署;如果你的业务一部分是热数据,一部分是冷数据,这时候组合方案会带来更低的成本。相信,在Serverless架构变革中,每一个勇于尝试、敢于创新的企业,都将有机会找到属于自己的降本增效新路径,从而在激烈的市场竞争中脱颖而出,赢得更加辉煌的未来。

