数据中台:业务模型 VS 算法模型,到底该怎么用?
提到数据,就必须提到各种模型。小伙伴们经常有疑惑:从4P、SWOT、RFM到线性回归、决策数、Kmean聚类,都有人管它们叫模型,那这些模型到底有啥区别?今天一文讲清,大家看完再也不迷路哦。
一个例子,看懂二者区别
模型一词,本身指的是“对现实世界的抽象”,通过少数关键信息,描述复杂的问题。
提炼关键信息的方式有2种:如果从业务角度做提炼,就是:业务模型;如果用数学、统计学、运筹学、机器学习方法论提炼,就是:算法模型。
举个简单的例子,我们常说“营销4P模型”,这个4P其实是从业务逻辑出发的。站在业务视角,只要我做好了商品、渠道、价格、促销,就能把货卖出去。
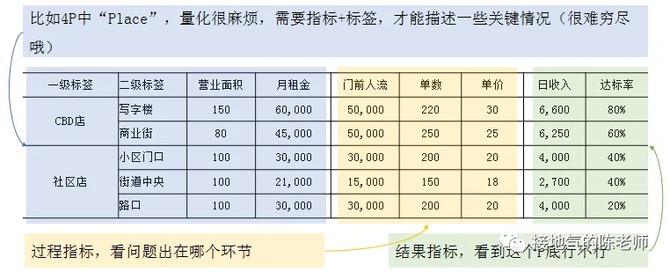
但是落到数据层面,就有很大区别。商品和渠道属性很难量化,我们只能通过打标签的方式,粗略对比不同标签下销售指标差异(如下图):
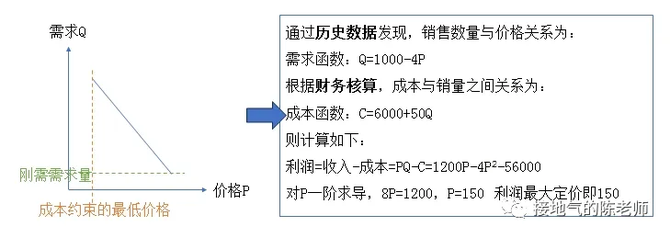
商品价格/促销与销量的关系,容易用数据量化,因此催生出一个经典的算法模型:价格弹性模型。首先采集不同价格下商品销量;第二步,拟合函数,总结出量价模型;第三步就可以拿模型推测涨价效果,或者求出利润最大化的价格了(如下图):
注意!方法都是为解决问题而设计的,两种方法各有优势。
业务模型的优势
业务模型最大的优势,在于能从业务角度给出问题的解释。
比如:
是不是我的策略不对?
是不是我的选品不行?
是不是我的执行力不行?
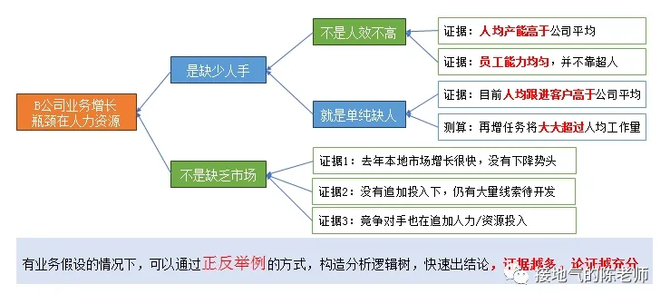
类似“策略”、“选品”、“执行力”这些业务上思考 ,很难直接用x、y的加减乘除关系来衡量。此时就得构造业务分析模型,先把“策略”、“选品”等名词量化,再用逻辑树的方法,对问题进行拆分,构造一个层层深入的分析逻辑,用排除法找到正确答案(如下图)。
业务模型的第二个优势,在于容易观察业务行动的效果。
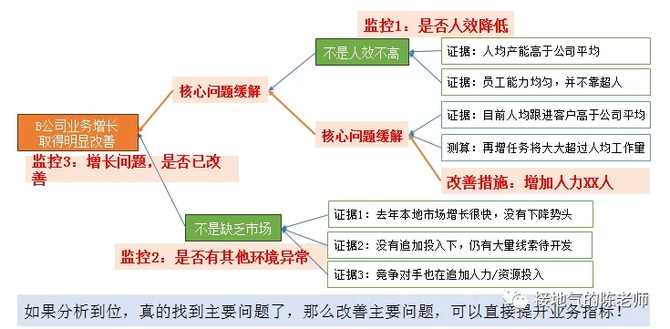
比如上图中,基于逻辑树,业务改进了执行动作,增加了人力投入。我们可以直接观察:逻辑树顶端问题,是否变好了,从而判断分析是否真的到位(如下图)。
业务模型的第三个优势,在于清晰业务主体责任。
比如都是做预测,如果直接用回归算法或者平滑算法给出一个结论,那么业务部门就没法看到自己行为的效果,还会迷惑地问:“那我下周加班不加班,结果一样吗?”“如果我搞不掂A客户,转而做B客户,是不是预测会不一样?”(如下图)
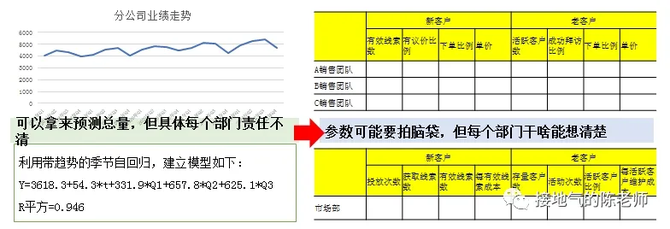
此时如果用业务模型来预测,可以直接把整体指标按部门拆开,让各部门填写自己预期情况。虽然具体参数可能需要拍脑袋得出来,但是每个部门能直接看到自己需做到什么水平,从而反向激励业务必须行动。即使没有完成任务,也能清楚看到“是谁没完成”。从而更快速地思考对策。
算法模型的优势
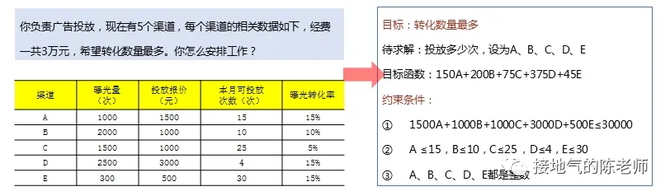
算法模型最大的优势,并不是比人聪明,而是运算速度快+省事。比如经典的互联网推广问题,各种限制条件一堆:“推广总预算,每个渠道转化率,每个渠道可以预约档期数量”等等。
此时,如果用人力去安排,可能要计算半天,但熟悉运筹学的同学们都知道,这是个典型的线性规划模型,只要能写清楚建模假设, 就很容易出结果(如下图)。
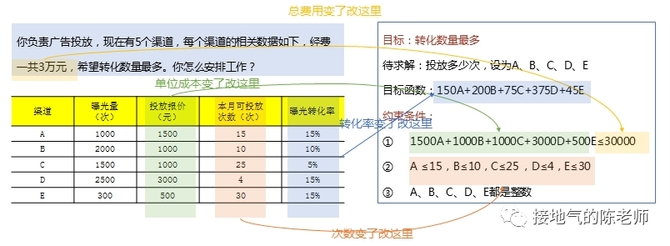
更方便的是,如果以后有调整,比如:
1、修改总投放费用
2、渠道档期数变化
3、渠道转化率变化
那么只要修改模型参数,就能快速出结果了,非常方便(如下图):
算法模型的第二个优势,是能发现业务没注意到的情况。
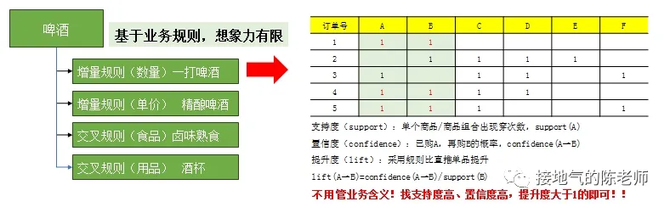
比如做商品分析的时候,业务上是可以手动输出一份《商品关联规则表》,但这个表格的规则是固定的。如果用关联规则算法,则可以突破业务思路的限制,发现更多潜在关联销售逻辑。虽然不见得是“啤酒与尿布”这么夸张的东西,但是也对启发业务思路很有帮助(如下图)。
算法模型的第三个优势,就是处理大规模数据了。
典型的业务模型RFM,做用户分层时,如果每个指标分3类,那么就有3*3*3=27类,在业务上已经复杂到很难匹配对应策略了。但是如果用协同过滤算法,完全可以做到千人千面,这也是算法模型的巨大优势。
之所以互联网公司倾向于用算法做推荐,主要是源自互联网平台上的商品量以十亿计,极难手动匹配规则。
业务与算法,如何完美配合
想要做好顺畅配合,建议大家在项目启动前,先花时间梳理好:到底要解决什么问题。而不是一上来先说:我要个模型。先捏个模型出来,再拿着锤子找钉子。
如果要解决的问题本身不清晰,比如:
1、诊断类问题:到底指标异动是因为内部还是外部原因?
2、标准类问题:到底该怎么定义“高价值用户”、“有效的策略”?
3、测试类问题:我有个新想法,还没实行,不知道有没有效果?
此时建议做业务模型,先把问题梳理清楚,把定义明确好,拿到测试数据,再看进一步怎么做?
如果要解决的问题定义清晰,且有数据积累,就很适合做算法模型。特别是即使业务很努力,也很难提升效果的时候,比如用户流失挽留,新用户电话销售等场景,天然响应率低,通过模型筛选目标群体能极大提升业务效率,此时效果好。

