数据工程师如何应对巨量的取数需求?
导读:做为一个数据工程师,这是必然要经历的过程,但只是经历不能一直深陷其中,如果你所在的部门一直处于接巨量的取数需求的状态,说明部门的数据建设的方向可能是不对的,那就让我们来看看有哪些破解之法吧,当然这次分享的破解之法,也肯定不是让这些需求排期,或者通过需求价值过滤需求等“行政”管理的方法,而是从技术与架构设计的角度给你一个全新的解决此类问题的视角。
01
问题产生的原因
1. 思维方式
在平常的业务运营中,产品运营经理需要大量的数据辅助运营,正所谓“无数据不运营”,业务的运营者永远离不开数据,但初级的运营者在需要数据的时候,第一个想到的就是找工程师导数据,他们的思维方式就是:要数据找工程师,而不会自己想办法去解决,他们巴不得有一个数据秘书,当他们需要什么数据时,工程师可以随时取出来送到面前。当然工程师肯定也不想只做一个“取数机”,因为对他们来说,“取数机”没有任何成长。
2. 需求方式
当工程师无法作为数据秘书,让运营者提需求时,运营者就会开始提需求,但是需求永远是从问题出发的,也就是说,现在我只需要这些字段的数据或者报表,就只会提这些字段和指标的需求,等拿到数据看了之后,发现不能解决问题,还想要看更多字段才能解决,然后又只能继续提需求,进入死循环。
数据需求与功能需求是有非常大的区别,数据需求呈现量多且变化快的特点,如“急诊”,但功能需求则更像“挂号”,所以数据需求不能像功能需求一样去提去完成,这么多变化快的需求,非常需要一个产品经理来全局设计成数据产品再提,如果放任这样的想到什么字段就提什么字段的需求泛滥下去,那工程师会陷入永无止境的需求陷阱之中。
3. 工具缺失
当运营者大量取数需求不能满足时,就会想到自己解决,但平台能取数的地方可能只有报表,没有什么其它工具可以提供。现有报表零零星星也有一些,但每个报表都只是几个字段的组合,完全不能满足需求,不是少字段就是字段的组合没有,或者数据不全,一个报表只能解决当时的一个问题,新问题还要做新报表,而工程师排期总是很满,要很长时间才能满足需求,所以运营也只能先这样了。
如果报表不是做成多维的方式,只是按不同需求做不同维度和指标的报表,那么因为维度与指标的组合是无穷无尽的,所以报表也是无穷无尽的,很难一直满足千变万化的运营需求。
02
数据建设的错误方向
1. 完全面向需求开发
需求没有经过数据产品经理设计成通用的数据产品,工程师的开发方式为:需求要什么字段就做什么报表,一个需求一张 RPT 表;工程师到处打听到表就直接取用,逻辑都堆在 RPT 层;偶尔也做些 dws 中间表,但好像也只能用在这个需求,和直接一张 RPT 表没有什么区别。这种就是完全面向需求的开发,是一种错误的数据建设方向,此种方式会让数据工程师陷入无穷无尽的需求迭代的陷阱中。
2. 没有模型表概念
数据建设的精髓在于数据模型的创建(一般是维度建模),有部分新手或者部分数据分析师、后端工程师转行做数据建设较为容易走向这个错误的方向。有些人不了解建模知识,SQL 能实现就行,用 SQL 实现了很多没有模型概念的 DWD/DWS/DIM 表;有些人对建模有些了解,但理解不透彻,开发了一些中间表但通用性较差,没有系统性的全局建模。当这些所谓中间表(DWD/DWS/DIM 层)不好用的时候,迭代的效率就会降低,需要花费大量的人力用 SQL 打补丁以支撑需求的开发,把自己搞成了“SQLBOY”。
3. 没有 OLAP 建设概念
如果主题域、数据域抽象不好,业务过程理解不到位,表会拆得又多又散,很容易进入无穷迭代陷阱,比如在基于事件埋点的数据建设中,将一个事件做一张事实表,或者把几个事件做一张事实表都会有问题,因为事件太多了,所以表就会很多,表太多,使用起来就会很困难,浪费大量人力堆叠复杂 SQL,口径也难以统一和维护,如图一所示的普通方法:
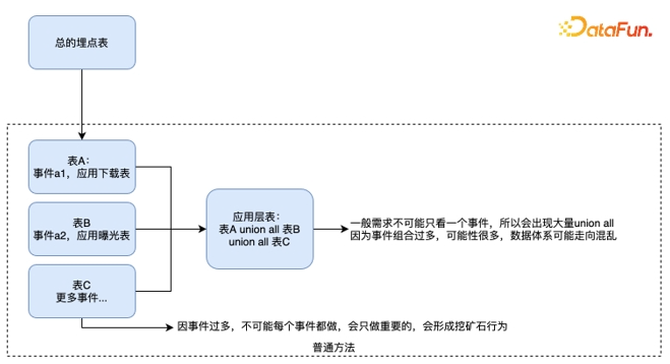
图一 数据建设普通方法
4. “挖矿石”行为
对于业务系统中的表,只抽取这个需求的部分字段,等下一个需求来了之后再抽取其他需求的字段,对源系统的表形成“挖矿”行为。对于埋点事件的数据建设,只做现在要的埋点事件,需求没用到的事件不管,对埋点事件的数据形成“挖矿”行为,这种行为危害非常大,因为表面上看工程师会一直有事做,一直很忙,有人对此乐此不疲,用这种方式“混”了公司好几年的工资,但其实这些比较忙的工作本应该可以没有。
5. 垄断 SQL 行为
一般取数的工程师,或者分析师手上都会有一些固定的 SQL脚本,如果他一直靠这些 SQL “活”下去,不发给别人,需要用时就拿出来改改以完成业务的需求,一直这样“混”公司的工资,就是所谓的垄断 SQL 行为,这些行为会导致大量公共逻辑维护在个人电脑中,口径是人为控制的,当然工程师通过对业务的理解也可以自行写出这些 SQL 来打破垄断,但如果团队形成这种氛围,对团队非常不好,公共逻辑应该要沉淀在数据模型中以供大家使用,共同维护才是合理的方式。
03
问题解决办法
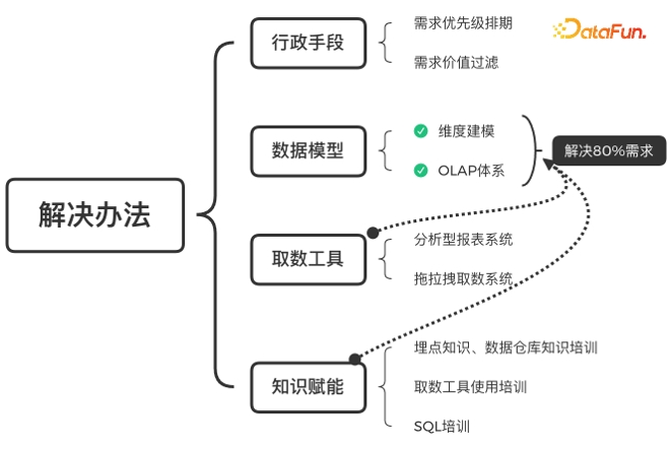
图二 解决巨量取数需求的方法
行政手段中的两个方法在一定程度上可以缓解问题,需求优先级排期是非常常见且合理的需求消耗方法,但如果诉求过多时,会有需求不能及时满足或者一直不能满足,对于运营策略的开展影响很大,供需矛盾会加剧却无法解决。而需求价值过滤更不好,如果要卷运营的需求价值,只会让运营挖空心思想法子应对此事,更进一步加剧矛盾。
取数工具是建立在数据模型之上的,如果数据模型的表没有设计好,需要开发大量的取数模板,取数人理解成本也巨大,即使有好的取数工具也是枉然,投入大量人力也只会收效甚微。
知识赋能也是建立在数据模型之上的,如果没有在数据模型的基础上设计好 OLAP 体系,那么表就又多又散又不好用,取数人学习成本高,取数难度大,赋能只会暴露自己的数据建设缺陷。
所以,要解决这个问题需要创建一套基于维度建模的数据体系,然后在此基础上开发 OLAP 多维分析报表,当这个基础建设做好做扎实了,问题几乎就解决了。当然如果要做得更好,可以把取数工具,报表工具做得更加完善健全,最后通过知识赋能培训指导大家如何使用,这样一套做下来,一定能取得非常好的效果。
04
OLAP 多维报表体系
如图三所示的多维分析报表能解决 80%+ 的数据获取问题,另外 20% 的需求则通过其他功能事实表解决,如留存事实表,归因事实表等。其中报表平台上的其他报表有 70% 可以直接从这个 OLAP 报表中配置衍生出来,不需要开发代码,不需要发版本,而且运营也可以实现配置,拥有自己的个人报表看板,不需要工程师参与。
对于工程师来说大量报表的底层表都是 OALP 表,只需要维护一张OLAP 表即可,可维护性更好。对于更多的使用者来说,比如会写 SQL 的分析师、运营经理、开发工程师可以开发基于 Clickhouse 的交互查询,直接自助查询 CK 里的表,可以秒级出数据,查数效率提升几百倍。
1. 报表使用方法
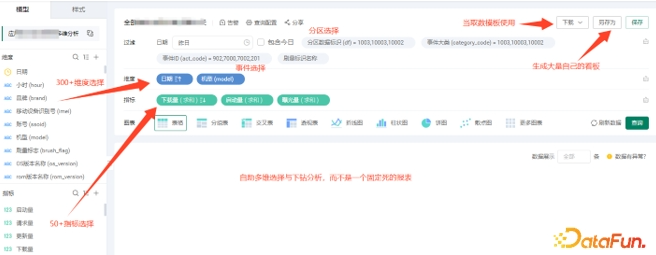
图三 OLAP 报表界面
如图三所示是在报表平台上提供的 OLAP 报表的获取数据的界面,功能介绍如下:
维度:包含这个主题的所有常用维度,包含退化后的维度,非常齐全,一般几百个字段,使用时将需要的字段拖到右边维度栏即可
指标:包含常用的基础指标,尽量不要把过多的维度打平在指标中,以免指标膨胀,一般 50 个以上的字段,使用时将需要的字段拖到右边指标栏即可
过滤:过滤栏有两个必选字段,也是分区字段、日期和数据标志,其中的数据标志在这里实际上是事件的分类,,将维度和指标拖到过滤栏即可。
2. 报表建设方法
OLAP 多维报表体系基于数据仓库而创建,如果数据仓库不作为,那 OLAP 多维报表体系也无从谈起,而在数据仓库建设过程中,最核心的工作除了架构设计之外就是维度建模,维度建模需要经验丰富的模型设计师或者数据架构师才能胜任,并不是简简单单的随便搞一些表结构就可以解决的。
小结
Kimball 大师曾经在他的著作《数据仓库工具箱--维度建模权威指南》中说,Geoogle Analytics(GA)是一个有名的做得非常出色的互联网应用,50% 的互联网上最受欢迎的 Web 网站都采用 GA,但这个其实就是一个数据仓库的应用,Google 中的一些人也在阅读他出版的书籍,借鉴他的方法论。
中国有一句耳熟能详的话:“农业学大寨”,大寨村的农业做得非常好,但是生产队的带头人去美国参观之后,看到美国两兄弟就可以经营千亩的农田,惊讶得说不出话来。美国全机械化操作的生产效率是大寨村每户经营几亩的几百倍。没有见识到真正的生产工具,总是困在自己的认知范围内,是无论怎么努力也无法把生产效率提高到一定高度的。

