一文了解数据湖变更数据捕获
在数据管理中有两个概念引起了极大的关注:数据湖和变更数据捕获 (CDC)。
数据湖
数据湖充当庞大的存储库,以原生格式存储原始数据,直到需要进行分析。
变更数据捕获
更改数据捕获 (CDC) 是一种用于识别和捕获数据更改的技术,可确保数据在各种系统中保持新鲜和一致。将 CDC 与数据湖相结合,可以解决 ETL 管道将数据从事务数据库传送到分析数据库时通常面临的几个挑战,从而显著简化数据管理。其中包括保持数据新鲜度、确保一致性以及提高数据处理效率。本文将探讨数据湖和 CDC 之间的集成、它们的优势、实施方法、涉及的关键技术和工具、实践以及如何选择适合需求的工具。
CDC 体系结构模式
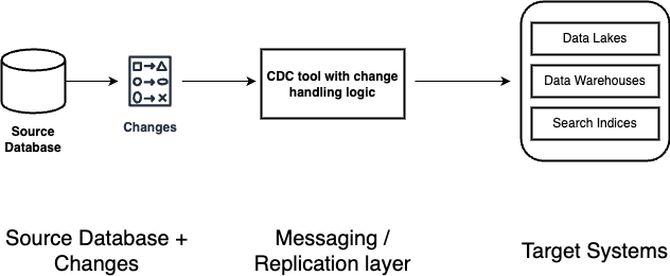
常见 CDC 组件
变更检测
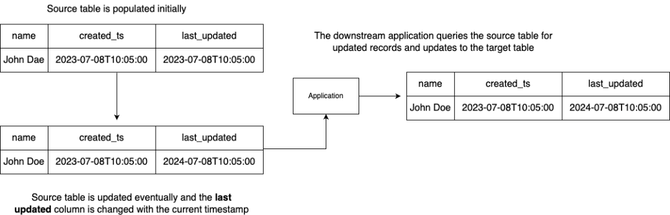
基于时间戳/基于查询
此方法依赖于表架构来包含一列,以指示它以前被修改的时间,即LAST_UPDATED等。每当更新源系统时,LAST_UPDATED列都应设计为使用当前时间戳进行更新。然后应用程序可以查询此列以获取记录,并处理以前更新的记录。
优点:
• 它易于实施和使用
缺点:
• 如果源应用程序没有时间戳列,则需要更改数据库设计以包含它
• 仅支持源表中的软删除操作,不支持 DELETE 操作。这是因为,一旦对源数据库执行 DELETE 操作,记录就会被删除,如果没有自定义日志表或审计跟踪的帮助,应用程序就无法自动跟踪它。
• 由于没有要跟踪的元数据,架构演变方案需要自定义实现来跟踪源数据库架构更改并适当更新目标数据库架构。这很复杂也很难实现。
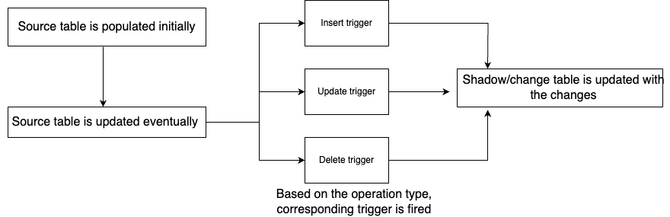
基于触发器
在基于触发器的 CDC 设计中,数据库触发器用于检测数据中的更改,并用于相应地更新目标表。此方法涉及自动执行触发器函数,以捕获源表中的任何更改并将其存储在目标表中;这些目标表通常称为影子表或更改表。例如在此方法中,当源数据库中存在特定事件(如 INSERT、UPDATE、DELETE)时,将触发存储过程。
优点:
• 易于实施
• 大多数数据库引擎都原生支持触发器
缺点:
• 维护开销 - 需要为每个表中的每个操作维护单独的触发器
• 性能开销 - 在高度并发的数据库中,添加这些触发器可能会显著影响性能
• 基于触发器的 CDC 本身并不提供将架构更改通知下游应用程序的机制,从而使消费者端的适应复杂化。
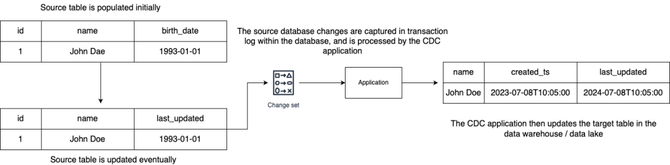
基于日志
数据库维护事务日志,这是一个记录所有事务和每个事务所做的数据库修改的文件。通过读取此日志,CDC工具可以确定哪些数据已更改、更改时间以及更改类型。因为此方法直接从数据库事务日志中读取更改,从而确保了低延迟和对数据库性能的最小影响。
优点:
• 支持所有类型的数据库事务,即 INSERT、UPDATE、DELETE
• 对源/操作数据库的性能影响最小
• 无需在源数据库中更改架构
• 通过表格式支持,即 Apache Hudi,可以支持模式演变
缺点:
• 在数据库之间发布事务日志时没有标准化 - 这会导致为不同的数据库供应商实现支持的复杂设计和开发成本
数据提取
一旦检测到变化,CDC系统就会提取相关数据。这包括操作类型(插入、更新、删除)、受影响的行以及数据的前后状态(如果适用)。
数据转换
提取的数据通常需要先进行转换,然后才能使用。这可能包括转换数据格式、应用业务规则或使用其他上下文丰富数据。
数据加载
然后,将转换后的数据加载到目标系统中。这可以是另一个数据库、数据仓库、数据湖或实时分析平台。加载过程可确保目标系统反映源数据库的最新状态。
为什么将 CDC 与数据湖相结合?
灵活性
一般来说,数据湖以更低的成本提供了更大的灵活性,因为它倾向于支持存储任何类型的数据,即非结构化、半结构化和结构化数据,而数据仓库通常只支持结构化和在某些情况下半结构化。这种灵活性使用户能够维护单一事实来源,并从不同的查询引擎访问相同的数据集。例如,可以使用 Redshift Spectrum 和 Amazon Athena 查询存储在 S3 中的数据集。
高性价比
与数据仓库相比,随着数据量的增长,数据湖在存储成本方面通常更便宜。这使用户能够实现奖章架构,该架构涉及在三个不同的级别(即青铜层、白银层和金层表)中存储大量数据。随着时间的推移,数据湖用户通常会实施分层存储,通过将不常访问的数据移动到较冷的存储系统来进一步降低存储成本。在传统的数据仓库实现中,维护不同级别的数据所需的存储成本会更高,并且随着源数据库的增长,存储成本会继续增长。
简化的 ETL 流程
CDC 通过持续捕获数据湖并将其应用更改,简化了提取、转换、加载 (ETL) 过程。这种简化降低了传统 ETL 操作的复杂性和资源强度,通常涉及批量数据传输和大量的处理开销。通过仅处理数据更改,CDC 使该过程更加高效,并减少了源系统的负载。对于使用多个摄取管道的组织,例如 CDC 管道、ERP 数据摄取、IOT 传感器数据的组合,拥有一个通用存储层可以简化数据处理,同时让您有机会构建统一的表,将来自不同来源的数据组合在一起。
CDC 架构设计
对于具有特定需求或独特数据环境的组织,开发自定义 CDC 解决方案是一种常见的做法,尤其是使用开源工具/框架。这些解决方案提供了灵活性,并且可以进行定制以满足业务的确切要求。但是开发定制的 CDC 解决方案需要大量的专业知识和资源,因此对于具有复杂数据需求的组织来说,这是一个可行的选择。示例包括 Debezium/Airbyte 组合的 Apache Kafka。
解决方案
Apache Hudi 是一个开源框架,旨在简化增量数据处理和数据管道开发。它有效地处理数据生命周期管理等业务需求,并提高数据质量。从 Hudi 0.13.0 开始,CDC 功能是原生引入的,允许记录更改记录前后的图像,以及相关的写入操作类型,这使用户能够
• 执行记录级插入、更新和删除,以实现隐私法规和简化的管道 – 对于 GDPR 和 CCPA 等隐私法规,公司需要执行记录级更新和删除,以遵守个人权利,例如“被遗忘权”或同意更改。由于不支持记录级更新/删除,因此需要自定义解决方案来跟踪单个更改并重写大型数据集以进行次要更新。借助 Apache Hudi,可以使用熟悉的操作(插入、更新、更新插入、删除),Hudi 将跟踪事务并在数据湖中进行细粒度更改,从而简化数据管道。
• 简化高效的文件管理和近乎实时的数据访问 – 流式处理 IoT 和摄取管道需要处理数据插入和更新事件,而不会因大量小文件而产生性能问题。Hudi 会自动跟踪更改并合并文件以保持最 佳大小,无需使用自定义解决方案来管理和重写小文件。
• 简化 CDC 数据管道开发 – 这意味着用户可以使用开放式存储格式将数据存储在数据湖中,而与 Presto、Apache Hive、Apache Spark 和各种数据目录的集成使您能够使用熟悉的工具近乎实时地访问更新的数据。
改进后的架构
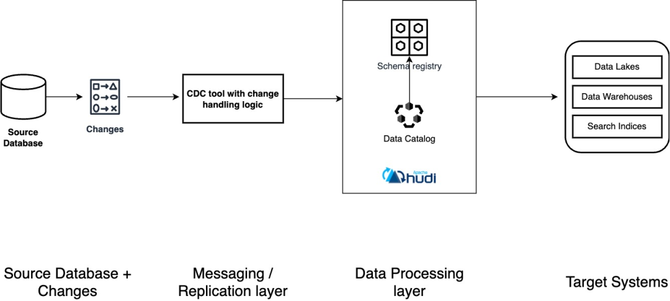
在这个架构中,随着数据处理层的加入,我们增加了两个重要的组件
• 数据目录 – 充当各种数据源中所有数据资产的元数据存储库。此组件由编写器(即 Spark/Flink)更新,并由读取器(即 Presto/Trino)使用。常见示例包括 AWS Glue Catalog、Hive Metastore 和 Unity Catalog。
• 模式注册表 – 用于管理和验证模式的集中式存储库。它将架构与生产者和使用者分离,从而允许应用程序序列化和反序列化消息。架构注册表对于确保数据质量也很重要。常见示例包括 Confluent 架构注册表、Apicurio 架构注册表和 Glue 架构注册表。
• Apache Hudi – 作为一个与 Spark/Flink 结合使用的平台,它引用模式注册表并写入数据湖,同时将数据编目到数据目录。
使用 Spark/Flink + Hudi 编写的表现在可以从 Presto、Trino、Amazon Redshift 和 Spark SQL 等流行的查询引擎中查询。
总结
将数据湖与变更数据捕获 (CDC) 技术相结合,可以提供强大的解决方案,以解决与在 ETL 管道中保持数据新鲜度、一致性和效率相关的挑战。有几种方法可用于实现 CDC,包括基于时间戳的方法、基于触发器的方法和基于日志的方法,每种方法都有其自身的优点和缺点。特别是基于日志的 CDC,尽管它需要处理不同数据库供应商的事务日志格式,但它对源数据库的性能影响最小,并且支持各种事务。使用 Apache Hudi 等工具可以简化增量数据处理和数据管道开发,从而显著增强 CDC 流程。Hudi 提供高效的存储管理,支持隐私法规的记录级操作,并提供近乎实时的数据访问。它还通过自动跟踪更改和优化文件大小来简化流数据和引入管道的管理,从而减少对自定义解决方案的需求。

