终于有人把数据治理讲明白了
数据治理(Data Governance)是企业对数据资产管理行使权力和控制的活动集合(包括计划、监督和执行),它是管理企业数据资源的一种方式、方法,旨在确保数据的质量、安全、合规和有效性。数据治理是企业实现数据战略的基础,是一个管理体系,包括组织、制度、流程和工具。
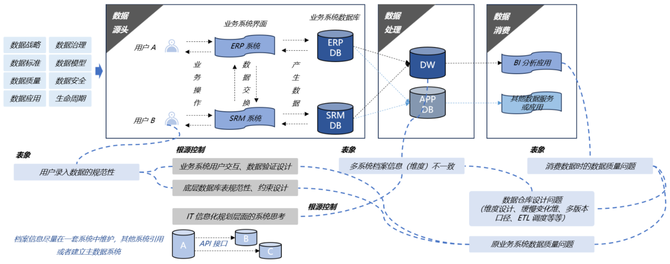
数据治理是一套复杂的管理体系,它无法通过单一的工具或产品来实现。数据的生命周期包含了源头、处理和消费这三个阶段,数据的问题也可能会出现在这三个环节中。例如在数据源头环节,用户录入数据的规范性存在问题,导致了最终数据消费环节的数据质量低。这些表象问题的根源,可能来自于业务系统用户交互设计,乃至是底层数据库表结构设计上的缺陷。想要解决这些表象的问题,就需要解决深层次的信息化业务系统开发以及数据库表约束设计等问题。例如为了保证用户录入数据的准确性,有三种方式去设计业务系统:其一是设计前端的检验验证,避免用户做出相同的选择;其二是通过程序编写过滤判断的逻辑,筛除掉前端误入的数据,作为第二层验证;其三是通过建立约束条件,例如唯一性约束、检测约束等等来控制数据录入准确性。因此,企业的数据治理远非使用一款单一的工具或产品就可以实现的,它是需要回到源头,对企业的组织、流程制度、业务系统、底层架构等多个方面进行排查和重构的,它是一套复杂的管理体系。
数据治理的两种策略
考虑到数据治理工程的复杂性,我们提出了两种目的性不同的数据治理策略:拉式策略(Pull Strategy)和推式策略(Push Strategy)。
拉式策略,面向数据应用,是以提升数据应用过程中的数据准确性为目标的数据治理建设策略。它强调在数据应用的过程中定位和解决问题,以数据应用项目为建设周期。具体而言,拉式策略有三个特点:
1.自上而下:拉式策略通常以指标体系为起点,进行金字塔式自上而下的规划与建设,通过“数据流、业务流、信息流”的过程反向推动数据质量提升;
2.数据整合:它包括多系统的数据整合、拉通、清洗、处理,以及数据仓库建设和ETL 开发过程;
3.数据应用:拉式策略面向数据应用。根据实际业务情况,主要解决数据指标定义标准不清晰、指标计算口径不统一、指标计算口径版本变更、数据不准确、数据上报与数据审核等数据应用场景出现的问题。
推式策略,面向数据全生命周期的管理与控制,是一种体系化的数据治理建设策略。它强调体系化的计划、监督、预防与执行,包括多年计划的数据策略周期。具体而言,推式策略有三个特点:
1.体系化、系统化:推式策略不针对某个单一的、具体的数据应用场景,而是一个全面体系化的治理过程;
2.全生命周期:它贯穿数据全生命周期的管理,例如数据采集、数据质量、数据应用、数据安全、数据分享等多个环节;
3.立体策略:推式策略从数据治理策略(目标、范围、方法和组织 )开始,通过专业的数据治理团队进行数据治理的规划、实施和监督,通过制定数据管理流程规范从源头业务系统的构建到数据的分发、流转,包括数据安全策略与控制,最终贯穿数据资产管理、分析和挖掘的全生命周期过程。
策略比较
拉式策略以数据应用需求为起点,推式策略以标准规划为起点,两种策略在多个方面有差异:
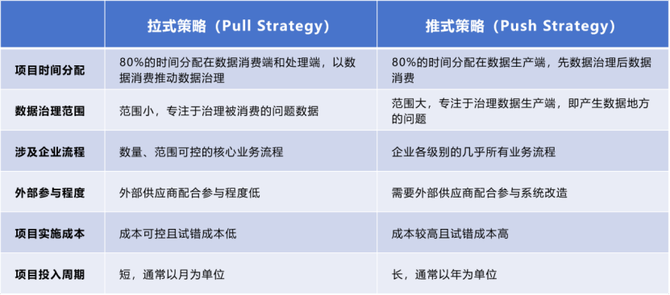
根据多数企业的实践经验,以数据应用需求为起点的拉式策略有着更短的实施周期和更低的投入成本,是一种更加灵活、更加敏捷的数据治理策略,我们将在下文中着重介绍这种数据治理策略。
以提升数据应用过程中数据准确性为目标的拉式数据治理建设策略主要包括3个流程:
(1)基于指标体系的数据问题洞察:基于数据指标体系,以“数据流、信息流、业务流”的基本逻辑框架,在限定的范围内及时洞察数据质量问题的根源,并逆向推动业务信息化和业务管理的改善和提升;
(2)稳健的数据架构设计:通过数据仓库建模、合理的分层设计、ETL 过程开发等,保障数据模型及架构的稳健性和可扩展性,提高数据使用的准确性;
(3)数据应用审核管控机制:建立面向高层管理的数据指标管控及审核机制,确保数据应用过程中(上报、可视化分析)关键数据必须经过有效审核,提升数据使用质量及数据准确性。
数据问题洞察
数据问题的洞察过程可以分为5个步骤:第一步是企业内部的资料收集和需求调研;第二步是指标体系梳理;第三步是确认可视化原型设计方案;第四步是“数据流-信息流-业务流”的问题识别过程;第五步是暴露问题,形成数据质量提高待办。这些步骤中最为重要的是第二步指标体系的梳理和第四步“数据流-信息流-业务流”的问题识别过程。数据问题洞察,本质上就是基于数据指标体系,以“数据流、信息流、业务流”的基本逻辑框架,在限定的范围内及时洞察数据质量问题的根源,并逆向推动业务信息化和业务管理的改善和提升。
数据流层面:企业数据问题的洞察始于数据流层面的对指标体系的梳理。指标体系里包含指标和维度,指标即是目标,维度是数据的视角。在确定指标体系后,就需要标准化指标的定义与计算口径、计算逻辑,包括对不同计算口径的版本管理。在计算口径确认后,就需要顺着计算逻辑逐层向下追踪,查看数据能否被获取到。
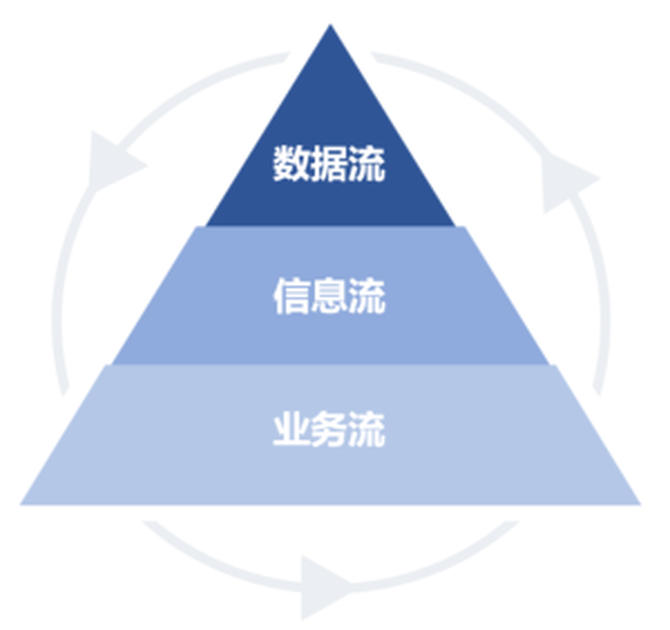
信息流层面:如果在数据流层面出现了问题,比方说数据不能被获取到,那么问题很有可能出在信息流层面,例如信息系统建设存在问题导致数据没有被收集。在这种情况下,可以通过手动填报的方式补录数据,也可以在后续的阶段中完善信息系统的建设。这一过程体现了从数据流到信息流的分析,企业能够更深层次地洞察数据问题的本质,通过数据流暴露的问题来逆向推动未来信息流建设的完善,进而支撑更全面的指标体系。
业务流层面:数据流层面出现问题,排除信息流层面存在的信息系统建设问题,还有可能是业务流层面的管理问题导致的。例如同一个指标有不同的计算口径,这就不是信息系统的问题,而是管理自身的问题,是由于部门间的冲突而导致的。从数据流到业务流的分析,企业可以通过表层的数据问题洞察到自身业务流程上存在的弊端,从而逆向完善业务管理流程和管理边界。
在这样金字塔式的数据问题洞察方法下,通过阶段性、有限的指标体系框定了取数的来源范围,因此不会盲目地扩大数据治理的范围和目标。通过在限定的系统范围内洞察存在问题的数据,可以形成有针对性的数据治理策略,让问题聚焦。最后通过阶段性的识别问题、解决问题,可以由点到面、由浅及深,暴露的问题逐步解决,保障阶段性的建设成果。
企业表层数据问题的产生往往有深层次的业务系统设计、流程制度管理方面的原因,因此要想通过数据治理提升企业数据的质量,就不能仅仅依靠一个工具或产品解决表象的问题。我们提出了企业数据治理的拉式策略(Pull Strategy)和推式策略(Push Strategy)来满足不同的数据治理需求。考虑到当今企业面临的复杂环境,实施周期更短、治理成本更低的拉式治理策略更能及时满足企业数据消费的需求,是一种更灵活、更敏捷的数据治理方式。在该策略下,基于指标体系的“数据流-信息流-业务流”分析逻辑能够帮助企业发现、洞察、追踪数据问题产生的根源;稳健的数据架构设计能够帮助企业解决数据质量的问题;数据应用审核管控机制的建立能够帮助企业解决错误数据被使用的问题。经过系统化的数据治理,企业数据质量将更能满足消费的需求,基于数据的决策也将更加精准。

