终于有人把ETL处理全流程讲清楚了!
在当今数据驱动的世界中,企业不断收集和分析大量信息,以获得见解并做出明智的决定。然而,收集和准备这些数据进行分析的过程可能既复杂又耗时。这就是ETL开发发挥作用的地方。
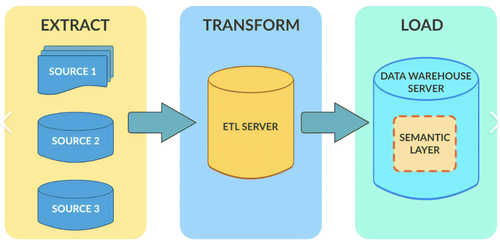
ETL代表提取Extraction、转换Transform、加载Load——这个过程涉及从各种来源提取数据,将其转换为一致的格式,并将其加载到目标数据库或数据仓库中。这是数据集成和分析的一个重要步骤,因为它确保数据准确、可靠,并准备好进一步处理。
今天我们就来详细说下ETL整个操作流程:
Extraction-数据抽取
一、从数据库中提取数据
1. 使用 SQL 查询
对于像 MySQL、Oracle 和 SQL Server 这类数据库,ETL 工具通常会利用 SQL(结构化查询语言)来提取数据。
例如,通过编写简单的 SELECT 语句,可以从一个或多个表中获取所需的数据。
2. 数据库连接驱动
ETL 工具通过特定的数据库连接驱动来与数据库进行通信。这些驱动是软件组件,能够理解数据库的协议并将 ETL 工具的请求转换为数据库能够理解的操作。例如,Java - based 的 ETL 工具可能会使用 JDBC(Java Database Connectivity)驱动来连接数据库。当配置 ETL 工具时,需要指定数据库的连接信息,如主机名、端口号、数据库名称、用户名和密码等。驱动会根据这些信息建立与数据库的连接,然后执行提取数据的操作。
二、从 API 中提取数据
1. HTTP 请求
当把 API 作为数据源时,ETL 工具会通过发送 HTTP(超文本传输协议)请求来获取数据。对于 RESTful API,ETL 工具发送 GET 请求来检索数据。
例如,要从一个提供天气数据的 API 获取某个城市的天气信息,ETL 工具可能会发送如下的 GET 请求,这个请求的 URL 指向了 API 的端点,其中包含了查询参数(如城市名称和数据类型)。ETL 工具会根据 API 的文档构建正确的请求 URL,然后发送请求。API 会返回数据,通常是 JSON 或 XML 格式,ETL 工具再对返回的数据进行解析。
2.认证和授权
许多 API 需要进行认证和授权才能访问数据。ETL 工具需要处理这些认证机制。
常见的认证方式包括 API 密钥、OAuth(开放授权)等。如果是 API 密钥认证,ETL 工具需要在请求头或请求参数中包含正确的密钥。
例如,对于一个使用 API 密钥的地图数据 API,ETL 工具可能会在请求头中添加类似 “Authorization: Bearer YOUR_API_KEY” 的信息,以证明自己有权访问数据。
3.处理 API 响应
API 返回的数据格式可能是多样化的,如 JSON 或 XML。ETL 工具需要有相应的解析功能来处理这些格式。对于 JSON 数据,ETL 工具会将返回的字符串解析为一个数据结构(如字典或列表),然后可以提取其中的具体数据。例如,如果 API 返回的 JSON 数据如下:{ "city": "Syndey", "weather": "Sunny", "temperature": "70" }
ETL 工具通过解析这个 JSON 数据,提取 “city”、“weather” 和 “temperature” 等字段的值,用于后续的转换和加载操作。
三、从文件中提取数据
1.文本文件(CSV、JSON、XML 等)
· CSV 文件,ETL 工具通常会逐行读取文件内容。以 Python 语言为例,使用内置的 csv 模块可以很方便地读取 CSV 文件。
· JSON 文件,ETL 工具会使用 JSON 解析库来读取文件内容。在 Python 中,可以使用 json 模块进行解析。
· XML 文件,ETL 工具会利用 XML 解析器。在 Java 中,可以使用 JAXP(Java API for XML Processing)等相关库来解析 XML 文件,通过遍历 XML 节点来提取数据。
Transform-数据转换
在ETL过程中转换和清理数据的详细说明:
数据转换和清理是ETL(提取、转换、加载)过程中的关键步骤。
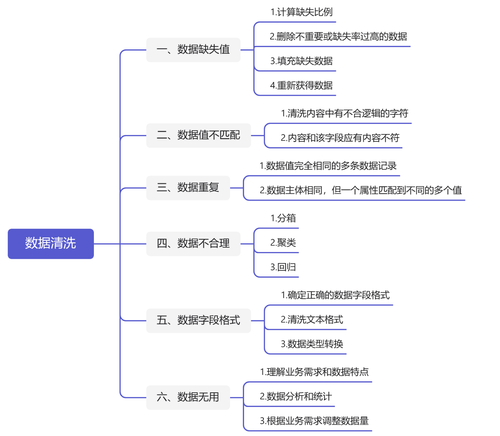
1. 数据映射-Mapping
1)数据映射是定义源数据和目标数据之间关系的过程。它涉及识别源数据中与目标数据中的字段对应的字段。此步骤对于确保转换后的数据与所需的输出格式一致至关重要。
2)在数据映射过程中,考虑字段名称、数据类型以及任何所需的转换或计算等因素很重要。通过仔细映射源字段和目标字段,可以确保转换后的数据准确代表原始信息。
2. 过滤-Filtering
1)过滤是一种用于从数据集中删除不需要的或无关的数据的技术。在ETL过程中,可以在各个阶段应用过滤,以消除不必要的信息。这有助于提高性能并减少存储需求。
2)应用过滤时,根据具体要求定义明确的标准很重要。例如,可能想要过滤掉不符合特定条件的记录或排除重复条目。通过应用适当的过滤,可以简化数据集,并专注于相关信息以进行进一步分析。
3. 数据类型转换-Data type conversion
1)数据类型转换涉及将字段的格式从一种数据类型更改为另一种数据类型。在以不同格式集成不同的数据集或为特定应用程序或系统准备数据时,此步骤是必要的。
2)在数据类型转换过程中,需要确保源系统和目标系统之间的兼容性。例如,如果源系统将日期存储为字符串,目标系统要求它们以日期格式,需要相应地转换格式。同样,将数值从一种格式(例如字符串)转换为另一种格式(例如整数)可以确保后续过程中的一致性和准确性。
3)要执行数据类型转换,可以使用ETL工具提供的内置函数或库。这些工具通常提供广泛的转换选项,允许无缝处理各种数据类型。
4. 数据清理-Data cleansing
数据清理涉及识别和纠正或删除数据集中的错误、不一致和不准确之处。这一步对于确保数据质量和可靠性至关重要。
常见的数据清理技术包括:
1)删除重复记录:重复的条目可能会扭曲分析结果,并导致错误的结论。通过识别和消除重复项,您可以确保准确的见解。
2)处理缺失值:由于各种原因,如数据输入不完整或系统错误,可能会出现缺失值。重要的是,通过将缺失值归因于估计值或将它们排除在分析之外,来适当地解决缺失值。
3)标准化数据格式:数据集中不一致的格式可能会在分析过程中造成问题。对日期、地址或名称等字段的格式进行标准化,确保一致性并提高数据质量。
4)更正不一致的值:在某些情况下,数据可能包含需要更正的不一致值。例如,如果字段以不同的货币(例如美元和欧元)存储货币值,则有必要将它们转换为单一货币以进行准确分析。
通过应用这些清洁技术,可以提高数据的准确性和可靠性,从而获得更有意义的见解和明智的决策。
Load-加载数据
在完成抽取、转换后,进入到数据加载过程:
1. 目标系统准备
1) 确定目标存储系统:
在加载数据之前,首先要明确数据的接收方。这可能是一个关系型数据库(如MySQL、Oracle、SQLServer等)、非关系型数据库(如MongoDB、Cassandra等)、数据仓库(如Snowflake、Redshift等),或者是简单的文件系统(如CSV、JSON文件存储)。不同的目标存储系统有不同的结构和要求。
2) 创建目标表或文件结构:
如果数据是加载到数据库或数据仓库中,需要根据数据的内容和格式创建相应的表结构。这包括定义表名、列名、数据类型、主键、外键等约束条件。
3) 配置目标系统连接:
ETL工具需要建立与目标存储系统的连接。对于数据库,这涉及提供目标数据库的主机名、端口号、数据库名称、用户名和密码等信息。ETL工具会使用相应的数据库驱动(如JDBC驱动)来建立连接。如果是文件系统,需要确保ETL工具对存储文件的目录有写入权限。
2. 数据加载策略选择
1) 全量加载:
这种策略适用于初次将数据从源系统加载到目标系统,或者当源数据发生重大变更(如系统升级、数据结构调整)需要重新加载全部数据的情况。例如,在构建一个新的数据仓库时,需要将业务系统中的所有历史订单数据全量加载到数据仓库的订单事实表中。
· 全量加载的优点是数据的完整性和一致性容易保证,因为所有数据都被重新加载,不存在数据遗漏或不一致的问题。但缺点是当数据量很大时,加载过程可能会比较耗时,并且会对源系统和目标系统的资源(如存储、网络、CPU等)造成较大的压力。
2) 增量加载:
增量加载是指只将源系统中自上次加载后新增或修改的数据加载到目标系统中。这需要在源系统或ETL工具中设置某种标识来确定哪些数据是新的数据。常见的方法包括使用时间戳(如数据库表中的“last_updated”字段记录数据的最后更新时间)、版本号(每次数据更新时版本号加1)或日志文件(记录数据的更改操作)。
3) 批量加载与逐行加载:
· 批量加载是指将一批数据(如数千行或更多)一次性地加载到目标系统中。这种方式可以减少与目标系统的交互次数,提高加载效率。许多数据库都提供了专门的批量加载工具或命令,如SQL Loader(用于Oracle)、BCP(用于SQL Server)等。在ETL工具中,可以利用这些功能将抽取和转换后的一批数据批量加载到目标数据库。
· 逐行加载则是每次将一条数据行加载到目标系统中。这种方式相对简单,但效率较低,通常适用于数据量较小或者需要实时加载单个数据记录的情况。
3. 数据加载执行
1) 数据库加载方式:
INSERT语句:如果是逐行加载到数据库,最常见的方式是使用SQL的INSERT语句。例如,对于已经抽取和转换好的一条客户订单数据,ETL工具可以执行INSERT语句将其加载到目标表中。
2) 存储过程调用:
有些复杂的数据库加载逻辑可以封装在存储过程中。ETL工具可以调用存储过程来实现数据加载。存储过程可以包含事务控制(如开始事务、提交事务、回滚事务),以确保数据加载的完整性。
3) 批量插入:
当采用批量加载策略时,可以使用数据库支持的批量插入方法。以MySQL为例,可以使用“INSERT INTO... VALUES (...), (...),...”的形式一次性插入多条数据。ETL工具会将抽取和转换后的一批数据按照这种格式组织起来,然后执行批量插入操作
4) 文件系统加载方式:
· 写入新文件:如果目标是创建一个新的文件,ETL工具会根据文件格式(如CSV、JSON等)将数据逐行或批量写入文件。对于CSV文件,需要按照CSV的格式规则(如使用逗号分隔列,引号包裹含有特殊字符的列等)来写入数据。
· 追加到现有文件:如果是将数据追加到已有的文件中,ETL工具会打开文件并将数据添加到文件末尾。同样以CSV文件为例,在Python中可以使用“a”模式(追加模式)打开文件并写入数据。
4. 数据加载后的验证和处理
1) 数据完整性验证:
加载完成后,需要验证数据是否完整地加载到了目标系统中。这可以通过检查加载的行数与预期的行数是否一致来实现。例如,在将一个包含1000条记录的数据集加载到数据库表后,可以通过查询目标表的行数来验证是否全部加载成功。
2) 数据质量检查:
除了完整性验证,还需要检查加载后的数据质量。这包括检查数据的准确性(如数据的值是否符合预期的范围和规则)、一致性(如关联数据之间是否匹配)等。
3) 错误处理和日志记录:
在数据加载过程中,可能会出现各种错误,如目标系统存储空间不足、数据类型不匹配、违反主键约束等。ETL工具需要能够捕获这些错误,并进行适当的处理。通常会将错误信息记录到日志文件中,以便后续查看和分析。对于一些可以自动修复的错误(如数据类型转换问题),ETL工具可以尝试自动修复;对于无法自动修复的错误,可能需要人工干预,或者根据错误的严重程度决定是否继续加载其他数据。
FineDataLink 是一款低代码/高时效的ETL数据集成平台,面向用户大数据场景下,满足实时和离线数据采集、集成、管理的诉求,提供快速连接、高时效融合各种数据、灵活进行ETL数据开发的能力,帮助企业打破数据孤岛,大幅激活企业业务潜能,使数据成为生产力。

