在过去的一年中,随着AIGC的快速发展以及各种应用场景的工程落地,大数据平台能力也面临着未来更多的迭代空间,一方面是思考如何更好的AI场景的结合,另一方面还要考虑对于业务层面如何更好的服务落地,这两个貌似是过去和未来几年一直要考虑的话题。
对于这块的内容可以写的也非常多,的确无法通过一篇文章来讲清楚这其中的所有东西,所以,在后面也许会当作一个系列来写,这里就先从数据从业者可以理解的角度来聊聊过去一两年数据平台所发生的变化,如果恰好你在调研这方面内容,也许可以帮助到你。
1. 数据分析到智能分析,平台运维到智能运维
自OpenAI于2022年发布以来,众多基于不同领域的大模型应运而生。其中,智能BI分析领域尤为引人注目。以往,我们进行BI报表分析时,通常依赖于已有的维度和指标进行拖拽聚合,并选择图表类型进行呈现。但是,其背后其实也依赖着一套数据分析引擎,至少前置的一些多维度的指标结果集是要先进行预处理完成,才能达到这样的效果。
然而,智能BI分析打破了这一传统模式。它能够逆向渗透到原始数据集,仅需在模型推理阶段加载相关元数据和数据集的完整信息,即可充当SQL Boy的角色,满足业务方提出的数据分析需求。对于有过这方面开发经验的人而言,不难理解这一变革所带来的时效性提升。简而言之,以往需要产品或业务方提出需求,再由研发人员编写程序或SQL的工作流程,现在已被大大简化。业务方只需登录智能分析助手,明确所需的数据分析内容,即可获得所需时间段的报表,并通过折线图等方式进行展示。这一过程,或许仅需业务方学习并掌握Prompt工程即可实现。
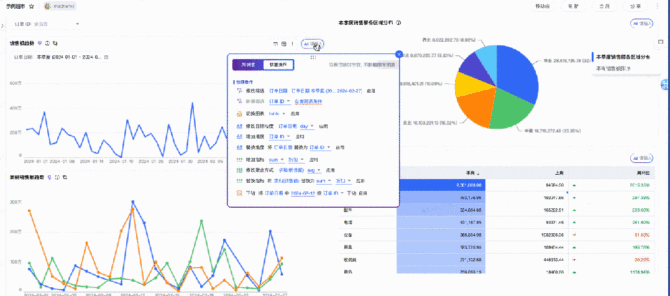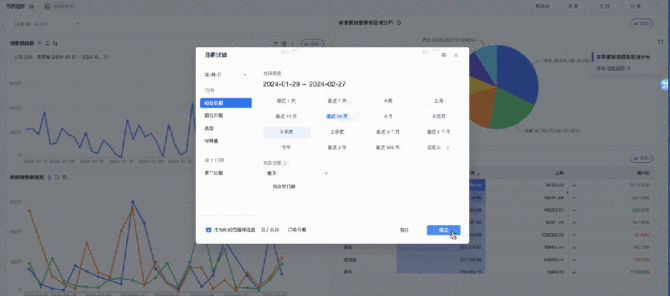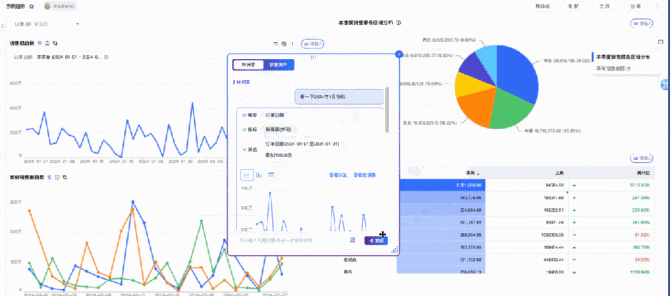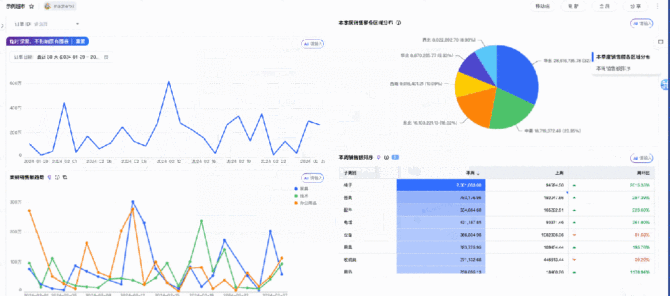
ChatBI的能力是目前最先也最快能够得出效益的产品,一方面是因为这个能力的受众范围实在是太广泛了,毕竟从信息化到数字化转型道路中关于数据的应用最核心的场景就是商业分析能力。另一方面,这一块能力其实在AI这波冲击之前已经有相关的企业案例了,数据分析领域Top级别的公司早先年已经推出了相关能力,例如tableau,只不过从成本上来说更加的高昂,现在面对其它类似于云厂商、开源能力的冲击才能够逐渐普及开来。
但是,对于业务来说学习成本是增加了,对于技术人员来说,也必然会面临着转型问题,这个话题后面可以在延伸讨论。
智能BI分析能力在之后,另外一个比较激进的应用场景就是智能运维,智能运维相比于智能分析而言,可以说是一个台后一个是台前,运维工作更多是出力不见好,好事看不见,这个有过这方面从业的人懂得都懂。
智能运维最开始可以说是先以辅助运维工作而开始,面对工作中各种脚本编写、问题处理、运维工具等等都可以通过AI来辅助执行,慢慢的,也考虑直接接入大模型的能力,一个比较简单的场景就是:
在服务客户/业务的过程中,可能经常性的出现线上使用的问题,例如配置不正确、程序OOM异常、日志报错、兼容性问题、异常告警修复等等,在过去运维和研发人员都需要上手来进行一一排查,然后记录下来处理过程和最终的排查结果,那么,如果有智能运维之后,过去所沉淀的排查记录都可以作为一个知识库的方式来接入大模型,从而构建出来一个智能运维系统,也就是最近两年很火热的AIOps,不妨看看对于AIOps更为官方一些的解释:
指利用人工智能(AI)等技术,精准地管控和分析IT系统中的海量运维数据,并通过自动化、智能化的方式来优化运维流程、提高运维效率和运维质量。
AIOps的特点是利用机器学习、深度学习等AI技术,对运维类数据进行分析和处理,从而对运维目标进行健康度评估、智能定位和异常分析,甚至发现潜在问题,提升目标系统的可用性和稳定性。
我记忆里好像最早看到互联网大厂有比较详细讲解关于AIOps的是美团的技术(不得不说,美团的技术博客内容干货还是挺多的)博客中,特意翻找了一下,发现是在2020年发布的,这篇文章感兴趣的读者可以阅读看看:https://tech.meituan.com/2020/10/15/mt-aiops-horae.html,
在文章里有一个架构图设计,如下图:
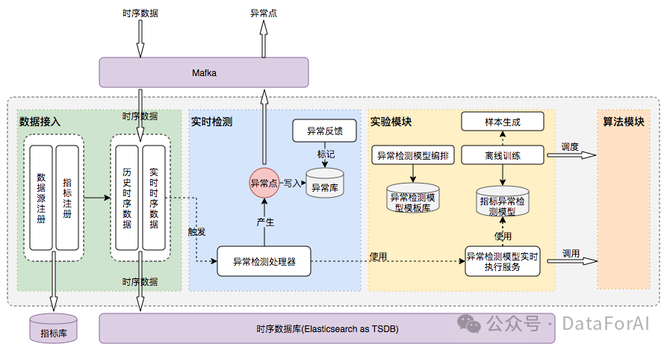
在这里,数据端其实各家都差不多的逻辑,区别在于实验模块和算法模块,这里有条件的公司可能会自己搞,没条件的话,可以基于开源模型来搞一个类似运维知识库。
还有很多系统性的内容没办法在这篇文章里讲全,就放在后面的系列更新里面了。总之,运维这块对于运维工程师来说是一个机会,而不应把它看作是一个困难,很多人觉得AI会替代现在的工作,其实换位思考,如果能主动把现在工作内容结合AI来进行迭代演进,也许职业生涯会迎来一个新的机遇。
2. 以数据为中心的模型开发
在过去,对于大数据而言可能更多用于数据挖掘、数据分析的场景,对于实际业务场景中GB、TB级别可能已经是属于比较大规模的数据了,但是在AI大模型场景中,这些远远不够达不到预期的训练目的,在AI大模型的开发过程中,基于海量数据的训练推理以及对于模型的训练效果非常依赖高质量的数据集。
在这个过程中,如何做好Data+AI领域中的数据资产管理、数据管理是一个比较有挑战的事情,面对非常庞大的数据集以及数据类目(AI大模型的数据类型往往是多种多样的),同时对于数据质量有强大的需求,于此,对于数据标注、数据清洗、推理算法等等都会延伸出很多需求,这些都是考虑在数据层面如何做功能的开发和产品力设计。
我们反过来再说AI对于数据领域开发是否也会有辅助?答案是:肯定会有的,从我个人过去做过非常大大数据相关的工作,基本上每一个都可以借助AI的能力来辅助支持,注意:这个辅助支持并不是像我们日常个人使用AI来加快代码编写或者AI来写一些脚本SQL之类的事情,而是说,它对于真实的业务场景可以直接通过集成的方式当作业务的一部分,除了上面写的数据分析、数据运维之外,还有考虑到对于数据仓库、数据建模、数据挖掘、数据治理等等这些可以具备逻辑计算能力的都可以来支持,你想想,AI最早线具备的能力就是数理分析,各种复杂的数学、统计学都可以信手拈来,轻轻松松,这些我会统一在DataForAI系列专栏里进行逐步讲解。
3. Data + AI的全新命题与挑战
在去年的几个数据大厂,包括databricks和SnowFlake都在其各自的Summit峰会中提到了要Data + AI的趋势进行发展,当我向Deepseek提问:作为一个数据平台的技术架构师,你觉得AI和大模型的到来,未来会给数据平台带来哪些挑战和机遇?
它回答了很多,也回答的很“AI化”,对于不了解的人看完肯定还是不了解甚至更加迷糊,如果只是简单询问一些关于技术规划类、架构类、设计类的问题,它其实无法从真实的角度来对答,所以,至少我认为AI是无法取代我的,它不具有人类对于现实场景的认知灵活性,它的形态里只有数字和逻辑,好似于一名“智人”在一个山洞中,阅读诸子百家、四库全书,但回答现实问题只能生搬硬套,无法参考现实中的准确场景。
回到全新命题与挑战,根据我的过去观察现象和调研结果,首先从底层资源层面肯定是需求量更大了,由此带来宏观上国产化高科技制造进程会进一步加快,当然这方面能力还需要加强和锤炼,微观来说,我们需要考虑如何将数据服务和AI服务(例如向量化、推理能力、训练能力)结合在一起,形成智算平台。
其次,回到数据技术本身来说,近几年数据湖和计算引擎都会有很大的版本升级迭代,这一点很鲜明,从去年databricks的技术发布会上就提出了Data+AI的口号“Your data,Your AI,Your future“ 以及SnowFlake也同样在去年提出了Data+AI平台,构建云上的智能数据湖,这两家分别引领着分布式计算和数据湖领域的发展趋势,由此可见技术组件的升级迭代也会加速进行。
最后,就是人才升级,无论过去是产品经理、分析师、研发工程师、架构师、测试工程师等等,都要贴合自身技能和行业领域的同时去学习应用AI,还是刚才那句话,不是简单的使用,使用的表面功夫其实都不能足以表明真实掌握,最核心要借助AI重新构建自己的护城河,这里要主动迭代技术栈,当真的有一天需要降本增效时,谁的效率高,出活快,谁才能笑到最后。

