如何在Kubernetes上运行AI/ML?
在机器学习(ML)领域,训练出高性能模型只是第一步,真正的挑战在于如何将模型快速、可靠且经济、高效地部署到生产环境中进行推理。特别是在大规模场景下,GPU资源管理、延迟优化、批处理策略、模型版本控制、可观测性以及辅助服务(如预处理器、特征存储库和向量数据库)的编排,都是亟待解决的难题。Kubernetes作为容器编排领域的佼佼者,为AI/ML应用提供了一个可扩展、可移植的平台,不仅能够有效管理GPU等计算资源,还能自动调整工作负载规模,以应对批处理任务以及实时推理的不同需求。
Kubernetes,一个为AI/ML高效分配资源的理想平台
Kubernetes通过其强大的调度能力,能够高效分配GPU和其他计算资源,实现工作负载的紧密打包和自动伸缩。同时,还能协调包含模型服务器、预处理器、向量数据库和特征存储在内的复杂系统,确保低延迟端点的稳定运行。容器化技术为模型环境提供了可重复性和一致性,使得模型的持续集成与持续部署(CI/CD)成为可能。Kubernetes内置的滚动更新、流量分割以及指标追踪功能,进一步增强了生产环境的安全性和可靠性。
对于追求操作简便性的团队,托管端点服务或许是一个选择,但在需要高度控制、可移植性、高级编排以及实时服务能力的场景下,Kubernetes无疑是首选。
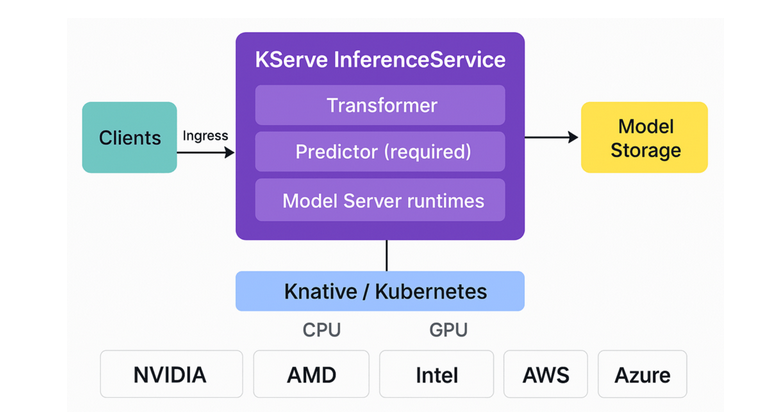
典型ML推理设置,KServe在Kubernetes上的应用
使用KServe在Kubernetes上进行机器学习推理,有一个典型架构,那就是客户端(如数据科学家、应用程序或批处理作业)通过Ingress向KServe的InferenceService发送请求。内部,通过可选的Transformer组件负责预处理输入数据,预测器用来加载模型并提供预测功能,而可选的解释器则提供模型洞察。模型工件从模型存储中提取,并通过TensorFlow、PyTorch、scikit-learn、ONNX或Triton等运行时进行处理。整个系统运行在Knative/Kubernetes之上,支持CPU和GPU计算层,并可与AWS、Azure、Google Cloud等云服务提供商集成。
至于,MLFlow与KServe的集成如何操作?MLFlow是一个开源的机器学习框架,旨在解决模型从实验到生产过程中遇到的常见问题,如实验数据丢失、结果重现困难以及模型版本管理混乱。它通过跟踪运行情况、保存环境代码和管理模型版本,为模型部署提供了有序的流程。MLFlow还支持将模型打包为Docker镜像,便于分发到Kubernetes等服务平台。
MLFlow与Kubernetes的集成,有一个关键点需要注意,虽然MLFlow提供了基于FastAPI的推理服务器,并通过mlflow models build-docker命令支持容器化部署,但这种方法在大规模生产环境中可能不够高效。FastAPI的轻量级特性使其难以应对极端并发或复杂的自动伸缩模式。相比之下,KServe(前身为KFServing)为TensorFlow、XGBoost、scikit-learn和PyTorch等主流机器学习库提供了高性能、可扩展且与框架无关的推理平台。
更好地托管AutoML,把Azure ML转为AKS
首先,Azure ML与AKS进行集成。Azure ML是一个全面的机器学习生命周期管理平台,支持实验跟踪、模型注册表、训练、部署和监控。对于需要高度控制运行时、扩展和网络的场景,Azure Kubernetes Service(AKS)是一个理想的选择。它允许自定义运行时、进行严格的性能调整,并与现有Kubernetes基础设施集成。
其次,进行分步操作,在AKS上部署Azure ML AutoML模型。
让Kubernetes上的LLM服务更好地运行,还需要vLLM与KServe的集成。接下来的问题是,如何把LLM与Kubernetes进行结合?在Kubernetes上运行大型语言模型(LLM)可以实现可靠、可扩展且可重复的推理。Kubernetes提供了GPU调度、自动伸缩和基本功能编排,而vLLM等优化运行时则提供了高通量、高内存效率的推理能力。通过结合请求批处理和可观测性(指标、日志记录和健康检查),可以提供低延迟的API服务。
使用vLLM和KServe部署LLM的步骤如下:
1.准备集群和KServe。配置Kubernetes集群(AKS/GKE/EKS或本地),并安装KServe。
2.获取vLLM。克隆vLLM仓库,安装vLLM,并在本地测试vllm serve命令。
3.创建vLLM服务运行时/容器。构建容器镜像,或使用KServe支持的vLLM服务时间配置。
4.部署InferenceService。应用KServe InferenceService YAML文件,引用vLLM服务的运行时和模型存储。
5.验证和调谐。通过Ingress/负载均衡器调用端点,测量延迟/吞吐量,并调整vLLM批处理/令牌缓存设置和KServe自动伸缩规则。
另外, vLLM、KServe,还要与BentoML进行集成。vLLM,作为高通量、GPU高效的推理引擎,负责实际执行LLM;BentoML,封装模型加载、自定义预处理/后处理以及稳定的REST/gRPC API,构建可重复的Docker镜像或工件;KServe,作为Kubernetes控制平面,部署Bento镜像或vLLM镜像,并处理自动伸缩、路由、健康检查和生命周期管理。最终,通过BentoML打包模型和请求逻辑,KServe将该容器以InferenceService的形式运行,提供自动伸缩、流量控制和可观测性。
值得一提的是,不同的技术路线选择,都有自己的优缺点。KServe作为Kubernetes-原生机器学习服务与编排框架,提供了丰富的路由、内置遥测和解释器集成以及多运行时支持,但学习曲线较陡,操作面较大。BentoML以Python为中心,提供了出色的开发者人体工学设计和可重复的图像,但集群原生控件较少。NVIDIA Triton推理服务器则以其出色的GPU吞吐量和混合帧支持著称,但同样需要额外的设置来实现自动伸缩和高级Kubernetes操作。
结论
在生产环境中运行可靠、低延迟的AI/ML应用,同时控制成本、性能和可重复性,是每个ML团队的目标。Kubernetes通过其强大的编排能力,为模型及其支持服务提供了所需的资源管理和自动伸缩功能。结合优化的运行时、服务层和推理引擎,我们可以在保持高输入性能的同时,获得生产级操作控制。从小处着手,使用单个模型进行验证,然后根据清晰的SLO选择符合性能和操作需求的服务栈,最终迭代出弹性且可扩展的服务。

