不改参数就能优化专业模型?腾讯优图这波操作,开辟低成本强化学习新时代!
打造专业模型,你的操作步骤是啥?对基础模型进行参数微调?还是通过强化学习更新模型策略?这样做的结果,是不是依然有一大堆令人头痛的问题,比如:算力太贵,没有充足的高质量标注数据,部署了多个专业模型却只适合窄业务场景……如今,这些问题都可以被一个叫做Training-Free GRPO的创意缓解。

前不久,腾讯优图实验室推出了一个具有业界颠覆意义的创新成果,专业领域大模型优化可以绕过传统模型参数训练方法,提升模型的表现。Training-Free GRPO的核心方法论是,通过反复积累和迭代“经验知识”来指导模型行为。这样做的好处是,不用修改模型参数,就能对类似于DeepSeek-V3.2这样的模型进行调优,让强化学习在超大规模LLM及复杂Agent系统上的训练成为可能。这意味着,这种低成本(仅需8美元)、高效率的强化学习模式,不仅打破模型、算力瓶颈,让每个开发者都能用得起、用好专业模型,还极大地推动了专业模型的创新,让模型在特定领域达到更优效果。
Training-Free GRPO开辟低成本强化学习新时代
说白了,Training-Free GRPO的工作原理是,不用对基础模型进行“大手术”,而是将优化从模型参数转移到其上下文空间,让模型从经验中学习。
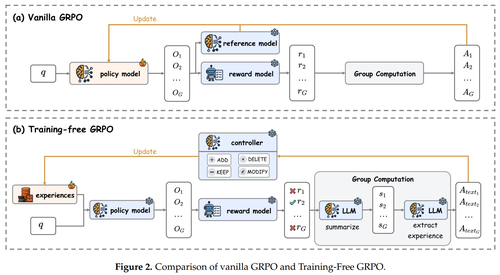
具体操作步骤是:1、多路径探索(Rollout),模型会把每个问题生成多个不同的解答路径;2、强化学习奖励(Reward),生成的解答会获得客观评分;3、语义优势提炼(Group Advantage),模型会自我反思,比较不同解答的成功或者失败路径;4、经验库优化(Optimization),基于提炼出来的语义优势,模型自动更新经验知识库。
假如我是一个中小企业开发者,没有大规模模型训练和部署能力,但有强烈的业务需求。我可以在原有模型上直接输入需求,AI智能体会直接生成输出,并多次尝试解决一个问题,然后根据成功与否对每次尝试进行评分、提炼教训,AI会反思成败,撰写经验教训并更新到共享的经验库中。与传统模型调优方法相比,Training-Free GRPO方法利用的是模型多次尝试的对比优势,创造出一个经验知识库,并让这个知识库来实时指导AI。
对于开发者而言,使用基于Training-Free GRPO方法的大模型,只需为不同任务插入不同的经验库,而无需重新训练核心模型,这将对大模型走向专业业务场景带来了效率和成本优势。
长尾细分场景特别适用
根据公布资料来看,Training-Free GRPO特别适合长尾细分场景,尤其是那种需要频繁更新大模型应用的场景。
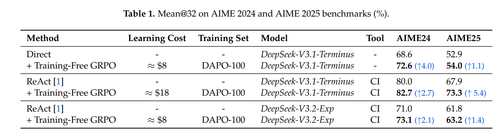
以数学推理场景为例,Training-Free GRPO可以带来令人惊艳的效果。在实验效果测试中,仅用100个训练样本,花费约8 - 18美元,就能在已经足够强大的671B模型上继续提升性能。如下图所示,无论是否采用代码工具(CI,code interpreter)帮助解题,在AIME榜单上的Mean@32指标都能实现提升。
值得一提的是,Training-Free GRPO不仅能够鼓励正确的推理和行动,还能教会智能体找捷径,更高效明智地使用工具,就像学生学会了更聪明的学习方法。

另外,在网页搜索场景中,Training-Free GRPO也能显著提升实力。开发者无需更新模型参数,即可在DeepSeek-V3.1-Terminus强悍水平之上,实现4.6%的显著提升。
结语
Training-Free GRPO实现了国内外专业模型领域的创新突破,首次将强化学习的优化空间从模型参数转移到其上下文。更重要的是,它用极致的效率,大幅降低数据和计算成本。对比市面上的专业领域大模型,其卓越的泛化能力,更好地保留了模型的核心能力以用于跨领域任务。相信,该方法论一旦被广泛推广,将快速被市场接受并普及。未来,AI智能体训练变得更实用且可负担。
附:
论文标题及链接:Training-Free Group Relative Policy Optimization
https://arxiv.org/pdf/2510.08191
项目主页:https://github.com/TencentCloudADP/youtu-agent/tree/training_free_GRPO

