大数据时代,企业对数据带来的业务价值有哪些期待?如果你参加了Amazon Redshift实战沙龙,一定会有更深刻的感悟!
12月30日,2022re:Invent Recap 开发者专场系列线下沙龙活动如期召开,本次会议由亚马逊云科技和ITPUB社区联合举办。继上一场Amazon Aurora Serverless 数据库开发者专场活动之后,以“化繁为简,Amazon Redshift让数据架构走向Zero-ETL时代”为主题的云数仓沙龙活动,精彩纷呈,现场座无虚席!
众所周知,2022 re:Invent有很多重磅发布,为了让更多嘉宾了解会议精华,2022开发者专场-北京站会议成功召开,本次云数仓专场重点分享了Amazon Redshift十年跃迁,以及多项重磅发布。同时,为把更多体验带给中国云技术爱好者,现场还设置了动手实践环节,多名开发者实地感受到云原生数据仓库带来的方便与快捷。
企业无需构建和维护复杂的 ETL 管道
针对企业用户重点关注的实际业务问题,比如:如何去构建一个云原生的数据战略?面向未来的云数据基础设施有哪些选择?亚马逊云科技 资深解决方案架构师 史天 ,以“Amazon Redshift业务价值及亮点功能更新”为话题点,进行了诸多分享!
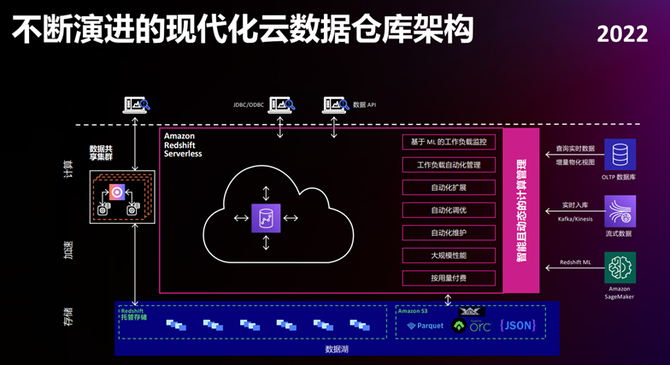
“企业面临多种多样的数据源,包括OLTP数据库、数据湖、流数据、文件存储等,而手动操作数据流水线,既昂贵又繁琐,云原生数据仓库可以极大地简化数据摄入工作。”在史天看来,要想有效解决复杂的数据重构以及数据不完整、不一致的问题,需要建立一个面向未来的数据底层基础设施。
谈到大数据,很多企业的基本用法都是从数据库中抓取很多业务数据,然后出BI报表,辅助老板或者团队做商务决策,这也是传统且典型的一些业务场景。再之后,数据不再是传统的关系型数据,还有数据湖、SaaS应用等其他数据来源,如何把这些数据导入数据仓库做相应分析呢?其中会涉及不同的数据源,也就是ETL的一些工作,包括抽取(extract)、转换(transform)、加载(load)这样一个Pipeline!
问题是,传统OLTP数据库,加上跨多个源的ETL,包括数据湖,会使得整个数据管道变得更加复杂,之前只是关系型到分析型数据库的转换,现在需要多线条的数据维护和管理。如何从更多数据挖掘数据见解?企业开始从大数据向机器学习演进,探索近实时的分析和预测模式!
其实,企业保存在数据仓库的数据,已经为ETL操作做好了准备,本身结构良好,非常适合在机器学习中做训练。所以,把数据仓库和机器学习结合,也是数据仓库产品的一个重要发展方向。
与此同时,企业业务正在发生新变化,之前做分析报表,或者做BI分析的时候,大部分数据都是离线模式,比如:出一个上个月、上周的产品销售分析,稍微快一些的,可以是前一天的数据分析。现在,各种应用数据都是实时打到应用系统中,到了实时数据分析平台之后,会变成批或者离线形式,对实时数据分析有很大影响。如何提升实时性?让数据在新鲜度很高的情况下,就能做实时分析,也是现在云数据仓库或者数据平台重点关注的方向!
有了很多数据之后,能做机器学习分析,也能实时捕捉数据的一些变化,那下一步的考虑是,如何实现数据变现?除了对数据进行分析,为业务提供一定的见解之外,如何把数据转化成对我们业务更有价值的产品,类似于数据即服务的模式,能对应用带来更大帮助,这是数据现代化的一种表现,是有别于传统数据仓库或者数据平台的一种新架构。
以上这些变化,是Amazon Redshift经过十年演进,走过的心历路程。换言之,提供面向未来的现代化数据架构,正是Amazon Redshift的长项。借助最新发布的Zero ETL功能,亚马逊云科技可以帮助客户完成从0到1的构建,再实现从1到0的蜕变。Redshift与Amazon Aurora数据库深度集成,在事务型数据写入Aurora后,数据在底层被持续地复制到Redshift,完成行式数据存储到列式数据存储的转换,彻底消除了自己构建和维护复杂数据管道的工作。同时,借助Amazon Redshift Integration for Apache Spark,用户可以通过类似EMR、Amazon Glue这样的Spark引擎来消费Amazon Redshift里面的数据。和之前相比,优化之后的技术可以使Spark引擎对Amazon Redshift数据抽取性能提升10倍多。
全链路云原生让数据实现实时分析
企业要想获取简单、低代码数据分析能力,需打破数据孤岛,建立端到端的数据旅程。
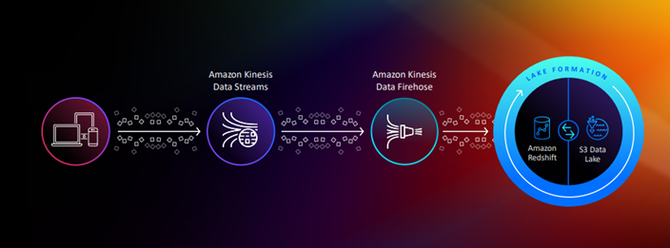
“在简单、可扩展的Amazon Glue 4.0时代,企业可以让数据集成更快,并且能实现大规模自动化。”亚马逊云科技 资深解决方案架构师 肖红亮,在“全链路云原生数据服务能力解析(大数据+云数仓+机器学习)”主题分享过程中,全面介绍了无服务器数据集成带来的业务价值。
以Amazon Glue为例, Amazon Glue 是一项完全托管,无服务器架构的ETL服务,客户无需预置基础设置,仅需由 Glue 负责预置、扩展 Spark 运行环境,并且使用 Amazon Glue 时,只需为 ETL 作业运行时间付费。其中借助Amazon Glue Data Quality,系统可以自动提供数据质量规则建议,通过持续的数据分析使数据保持高质量,同时控制数据湖和数据流水线中数据集的数据质量,确保用户成本收益最大化。在Amazon Glue中,企业还能扩展现有的Python框架代码,无需管理或者调优基础设施,建立全面数据分析流程。
再比如:在Amazon Redshift提供的Streaming Ingestion功能中,用户可以非常方便地可以将消息中心的数据接入到Redshift,中间无需依赖任何组件,执行Redshift标准SQL即可,整个过程自动摄取,极大地降低了数据入仓摄入延迟和维护成本。与其他同类产品不同,Amazon Redshift依靠自己内部的强大的机器学习算法,会自动去做一系列的动作,用户不再需要特别关注数仓性能的调优,只关注业务逻辑即可。
可以说,企业要想快速构建数据流水线,实现ETL自由,Amazon Redshift是底层基础设置的重要支撑。而凭借Amazon Redshift与其他数据分析应用的无缝集成,用户可以获得更完美的数据分析体验。比如:可以实现高性能格式存储数据,以更经济有效的方式将存储扩展到千兆字节,可实现存储和计算的分离,并且能支持ACID事务,实现分析和机器学习引擎的选择等等。

