分享议题:
1. Amazon Redshift 10年技术创新与演进;
从2012年到2022年,Redshift已经发展了十年。走到今天,RedShift的底层架构发生了哪些变化,提供了哪些功能和满足云原生数仓未来发展的关键特性,本文将重点阐述。
2. Amazon Redshift Serverless架构设计与应用场景;
亚马逊云科技所有数据分析服务已实现全栈Serverless化,包括OpenSearch、EMR、Glue都已经支持Serverless。另外,Redshift也有自己的Serverless,引领数据分析服务走向未来。至于,Redshift Serverless具体是怎样一种架构,在什么场景下会用到,这部分内容会进行全面分析。
3. 基于Amazon Redshift的云原生实时数仓实践。
Redshift作为云原生数仓、实时数仓,都有哪些新功能?如何满足用户对实时性的要求?在实时数仓方面有哪些实践?最后一部分将结合实际业务场景进行分析!
十年迭代
现在,全球大概有数万用户使用Redshift进行数据分析,这些用户来自游戏、金融、医疗、消费、互联网等。在十多年发展历程中,Redshift一直在持续迭代,很多功能和特性都源于企业的真实业务需求。
具体而言,客户数仓场景主要包括四大块:
第一, 常规业务运营与BI分析;第二,实时数仓分析;第三,查询、报表与数据分析;第四,机器学习与分析预测。
值得一提的是,Redshift现在支持机器学习算法,用户可以用SQL方式直接创建机器学习模型,比如:XGBoost、多层感知机、KMEANS等这些机器学习方法,但用户自己并不用去做这件事情,Redshift在后台集成了亚马逊云科技另外一个机器学习的服务SageMaker。通过调用SageMaker Autopilot,去完成机器学习能力,这也是亚马逊云科技经常强调的一个概念,即“数据分析产品之间要相互融合,数据无缝流转”。这样做的好处是,用户不需要对算法本身有太多深入的了解,只要用SQL创建一个Model就可以做机器学习算法分析,模型的优化,超参数的选择都交给Redshift来做,我们使用就像写SQL一样,方便快捷。
架构创新
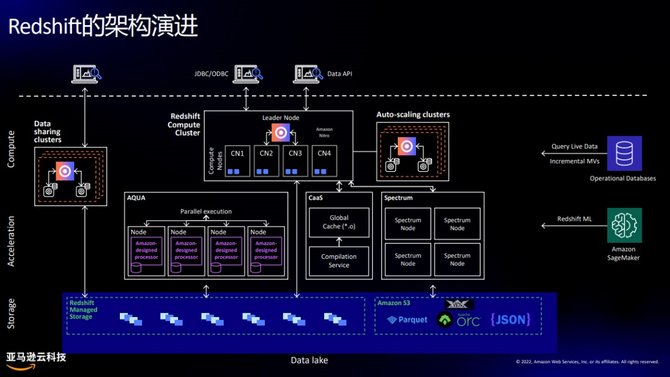
Redshift本身是一个MPP架构,红色是Leader Node,下面是Compute Node。Redshift表支持每列自动压缩,单列的压缩算法可以根据数据类型自己选择、自定义配置,向量化执行、列式存储,动态代码生成这些在OLAP引擎上的特性Redshift都做了深度的优化。对于客户来讲,Leader Node是免费的。比如:要创建一个Redshift Provisioned Cluster,购买4个节点,就是买了4个Compute Node,Leader Node也是一样大小,但是不收费。Redshift底层存储叫Reashift Managed Storage,当前Redshift是完全存算分离架构,底层数据是在S3上。做到存算分离之后,会有更多想象空间,存储和计算就能完全独立做扩展、做伸缩了。
对于存储,虽然数据在S3上,用户不能直接访问它,是Redshift自己管理优化后的存储格式,数据会以Redshift自己管理的的方式存到S3上,对用户来说“不可见”,存储价格在中国区比S3存储价格还低,S3标准存储中国北京区域是每¥0.195/GB,Redshift托管存储是¥ 0.154/GB,S3保证数据的持久性,无需冗余存储数据,相比用本地盘节省大幅节省成本。
做了存算分离,我们就可以实现Data Sharing的功能,将一个集群的数据共享给另外一个集群,底层数据共用一份,共享的是元数据,可以做到秒级别的数据共享。数据共享可以支持跨账号、跨区域以及数据的双向共享 ,这对用户非常方便。我们还可以做生产和消费的分离,比如:有一个生产者集群只ETL,做完后可以暂定,暂定之后集群就不收费用,数据查询通过将生产者集群的数据共享给另外一个消费者集群, 数据就只是一份,共享过去的只是表结构信息等元数据,我们可以看到做了存算分离之后架构会变得更灵活。
Redshift早在2017年已经实现湖和仓的融合,Redshift Spectrum可以直接查询在S3上开放格式的数据(parquet,json,csv等),当然也可以将数据写入到湖中。仓和湖的数据可以无缝流转。2019年Redshift实现了Federated Query,可以实现对关系型数据库,RDS/Aurora MySQL, PostgreSQL的查询。需要注意的是,Spectrum和Federated Query相比直接将数据存储到Redshift查询,性能是有损失的。Redshift支持内表和这些外表的关联查询。
Redshift可以通过SQL的方式直接创建ML的模型,并自动训练。客户不用关注模型的超参数的选择,算法的优化。Redshift底层会调用SageMaker Autopilot自动帮助客户选择最适合模型参数。训练完毕后返回推理函数,我们在数仓中直接将推理函数当做UDF使用即可,完成批量数据的推理工作。Redshift ML 目前支持机器学习算法XGBoost(AUTO ON 和OFF)和多层感知(AUTO ON)、K-Means(AUTO OFF)和线性学习器。
Concurrency Scaling是Redshift推出的专门应对高并发场景的功能。当业务查询的高峰期,Redshift可以在秒级别扩展出来新的集群应对高并发,当集群并发下降负载降低是会自动回收扩展出来的集群,并且该功能当主集群每运行24小时送一个小时的并发积分,因此在我们的大部分客户场景中使用该功能基本是免费的。
Redshift 内置机器学习算法,很多我们建仓是需要关注的表结构的优化设置,Redshift通过机器学习,会在后台自动完成相关优化。机器学习可以通过我们日常运行的SQL中学习到规律,比如两个表经常做Join,Redshift学习到该规律后,会自动创建物化视图,将SQL重定向到物化视图,用户完全无感的情况下提升查询性能。Redshift对于半结构化的多层级嵌套数据提供了专有Super数据类型,简单易用,相比常规使用JSON函数做字段解析要高效数倍。
Serverless探索
使用Redshift Serverless,用户只需关心数据的查询分析,探索数据价值就可以了,底层的自动扩展、计算资源分配、集群升级、数据备份、监控,这些都让亚马逊云科技Redshift Serverless帮你去做。所需要的成本,也是按需计费,不查询不计费。Serverless可以做到根据查询负载自动扩展计算资源。使用Provisioned Cluster时,我们还要考虑到集群节点个数的选择,手动的扩缩容,当有高峰期负载过来之后,可能当前集群不足以应对,要手动增加节点。而在Serverless环境下,完全没有集群概念,给的客户的就是一个 Endpoint,直接连接查询就可以了。
Redshift Provisioned Cluster默认的并发是50,但是在Serverless能够达到200。这跟SQL复杂度也有关系,当SQL比较简单时,并发可以达到500,如果业务并发要求更高的话,可以在Serverless前面放一个NLB,多个Serverless应对高并发。
有了Serverless之后,是不是Provisioned Cluster就不需要了?其实不是这样,当我们是负载是不可预测,或者某个时间段是高峰期,其它时间段只是零星的查询。这时使用Serverless是很好的选择。但如果我们在一天中负载都是比较恒定的,这时集群模式是更好的选择。比如实时Streaming数据一天24小时都在往Redshift里写,ETL操作每分钟都在集群上运行,集群CPU利用率可以达到70%以上, Provisioned Cluster相比Serverless会更节省成本。
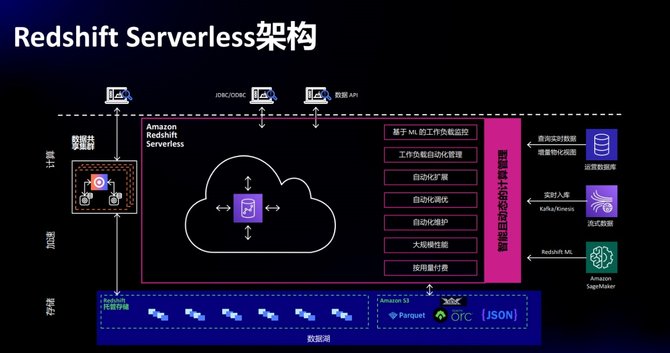
▲Redshift Serverless 架构
Serverless上支持功能是非常全面的,在Provisioned Cluster支持的功能在 Serverless都可以支持。Serverless不再有集群的概念,计算单元是RPU,工作负载自动优化、计算资源自动扩展,自动运维、按量付费,存算分离数据在S3上。Spectrum的功能、机器学习能力、关系型数据库查询,Data Sharing都支持。注意的是如果Provision集群数据需要共享给Serverless时,Provision集群必须加密,否则无法共享,这是为了保护数据的安全性。

▲Redshift Serverless 特点
Redshift Serverless有哪些特点:
1、简化用户体验,资源自动扩缩,无需管理资源,无需运维操作
2、智能动态计算,自动调配和扩展数据仓库容量,提供一致快速的用户体验。
3、支持所有Redshift的功能和性能特性。
4、按需付费,查时才收费,不查不收费。
5、统一计费
在集群模式中Spectrum的查询费用和并发扩展都要单独收费,Serverless都是统一按照RPU收费,不再有额外的费用,统一计价模型对用户比较方便。存储费用就是托管存储和用户快照的费用。
Redshift Serverless可以轻松应对那些无法预测和瞬态高峰的负载需求,有规律的高低负载窗口等负载场景,这是Serverless最擅长的事情。
BI场景下无需考虑基础设施即可轻松上手,给到一个Endpoint,BI接过来就可以查询。开发/测试环境以及即席业务分析,无需管理维护多个集群,不用预制一个小集群,只有测试的时候查询就收费,不查就不收费,所以开发测试环境下也是一个非常好的选择。
一个客户场景案例,通过DMS将数据实时CDC发送到Redshift Provisioned Cluster。DMS是亚马逊云科技上一个数据迁移服务,可以解析MySQL Binlog将数据实时发送到Redshift,支持数据的自动Merge,支持Schema变更的自动同步。在Provisioned Cluster上进行数据加工、转换,构建DWD/DWS层。通过Data Sharing功能,把数据Share到多个Serverless,每个Serverless就是一个Work Group,对应到不同的部门,单独部门单独去做成本结算,每个部门有自己的资源隔离。由于CDC是每时每刻都要写数据的,预置一个Provision Cluster是比较合适的。而业务端的查询负载是有高有底,且各个业务部门资源隔离,确保业务SLA,费用单独结算。在这个场景下,Provision Cluster和Serverless共存,尤其是实时场景下,是一个值得借鉴和使用的方式。
云原生实时数仓实践
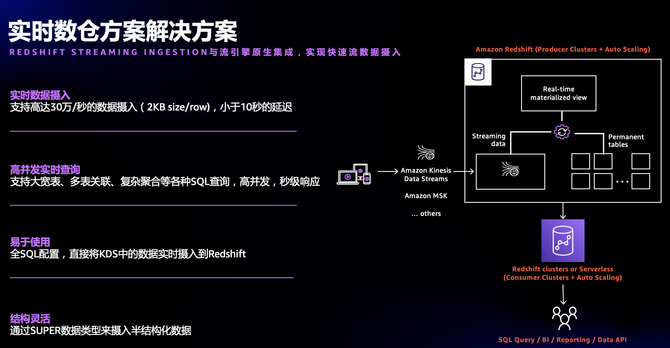
Redshift在实时数仓方面会有自己的功能特点,提供的功能特性会更贴近客户的需求。
关于实时数仓,客户的一般有三个需求:
1、数据摄入高吞吐、低延迟。
2、简单配置与使用。
用户用复杂的配置,就可以把消息中心的数据比如Kinesis Data Stream ,Kafka接入到数仓,中间不要构建其他数据传输的服务,或者进行代码开发,在几秒钟内实现实时分析。
3、提高生产力。能使用SQL对流数据进行丰富的查询分析,无需依赖其他语言。
实时数仓应用场景主要有:
改善游戏体验。通过分析玩家的实时数据,专注于游戏转化率、玩家留存和优化游戏体验。
实时应用洞察。通过访问和分析应用程序日志文件和网络日志中的流数据,开发人员和工程师可以对问题进行实时故障排除,提供更好的产品,并为预防措施提供警报系统。
广告分析。客户通常在一次会话中访问数十个网站,但营销人员一般只分析自己的网站。通过将数据实时摄入到仓库中,可以实时评估您的客户足迹和行为。
零售行业销售分析。近实时访问和可视化所有POS零售销售交易数据,以实现实时分析、报告和可视化。
物联网数据实时分析。互联网APP、物联网等实时应用程序监控、欺诈检测和实时排行榜等应用。
Redshift提供的实时数据摄入的功能叫 Streaming Ingestion。亚马逊云科技有两个在分析场景下常用的消息服务Kinesis Data Streams和 MSK(托管的Kafka服务)。Redshift Streaming Ingestion可以直接把这两个组件的数据直接摄入到Redshift中,在Redshift里只要创建一个视图,把数据接过来做SQL查询就可以了,无需引入其它数据传输组件,无需代码开发。吞吐可以支持高达30万/秒的数据摄入,小于30秒的延迟。
实时数仓场景下,Redshift Streaming Ingestion更易于使用。全SQL配置,直接将的数据实时摄入到Redshift,中间不需要程序代码的开发;同时,结构更灵活,如果在流里的数据是经常变化的结构,这时将数据解析为SUPER,当增加了字段或删除了某些字段时,SUPER完全能支持,不用更改Redshift第一个基表,下层做ETL时再做转换就可以了。

2022年,Redshift发布了另外一个在实时方面的重要能力——Zero-ETL。当需要将Aurora MySQL的数据实时同步到Redshift,之前需要是解析BinLog过来,进入消息队列,再从消息队列投递到数仓,整个过程比较复杂,维护成本也会比较高。但是zero-ETL是在存储层面,直接把数据复制到Redshift,中间不需要任何CDC工具,就是在云原生基础上两个服务之间的数据同步,可以做到零代码。Aurora也是存算分离架构, Redshift也是存算分离的架构,从存储层面把数据直接拿过来了,所以中间无须再构建任何的CDC工具做数据加载,相比CDC方式不仅能够降低摄入延迟,同时也不会对源端数据库造成压力。
除了Zero-ETL Redshift在2022还发布了其它新的功能:
1.Redshift与Spark的集成
当前Redshift和Spark可以无缝集成, Spark Streaming可以直接将数据写入到Redshift。2022年,我们发布了优化Redshift Spark Connector,支持了谓词下推,支持中间结果写Parquet。相比开源的Redshift Spark Connector,它的性能有10倍以上的性能提升。在实时层面,我们有Redshift Streaming Ingestion但如果客户依然使用的是Spark技术栈, Spark Streaming接到Redshift完全没有问题。
2.S3 AutoCopy自动加载数据
有些客户的实时数据并不是在消息队列里,而是在S3上,每分钟在S3上产生一个文件,或者几十秒在S3上产生一个文件。要把S3的数据写到Redshift只需要执行一个copy命令,但如果想实时监控某一个S3的目录,只要有新文件就copy数据到Redshift,需要手动构建Pipeline,需要要用调度工具去做封装,处理中间容错。现在,AutoCopy支持自动从S3加载数据到Redshift,只需要SQL方式创建一个Job就可以了,只要指定S3上某一个文件夹,该文件夹下所产生的数据就可以实时自动的copy到Redshift。如果某一个文件拷贝出错,会在系统表里记录哪个文件出错,回填、补数据文件,都可以实现。有了这个功能之后,从S3实时加载数据,不需要手动构建Pipeline,只需要在Redshift Create Job就可以了,简化了整个数据加载的过程。
小结
亚马逊云科技Redshift,有效降低了数据分析的门槛,为客户带来了更卓越的体验。尤其在发布了Streaming Ingestion 和 Redshift Serverless之后,可以做到更简单的实时应用分析、更加灵活的数仓架构设计。
分享嘉宾介绍

潘超
亚马逊云科技数据分析专家
亚马逊云科技数据分析产品技术专家,负责亚马逊数据分析产品的技术解决方案工作。在大数据存储、OLAP、离线、实时数据分析、用户画像及推荐系统等技术有深入的研究,对企业大数据平台构建有丰富的实战经验。

