摘要:湖仓一体架构的概念最早由Databricks提出,并迅速得到了业界的广泛关注和认可。它的核心思想是将数据湖的灵活性和成本效益与数据仓库的管理和分析能力相结合,以适应现代企业对数据多样化处理的需求。随着大数据技术的飞速发展,传统的数据架构模式已逐渐难以满足企业对数据存储、处理和分析的需求。在这种背景下,湖仓一体(Lakehouse)架构应运而生,它是一种新兴的大数据架构模式,旨在融合数据湖和数据仓库的优势,构建一个统一、开放且高效的数据平台。
湖仓一体的架构是怎样的?
湖仓一体架构特点和优势
湖仓一体架构应用场景
01
—
湖仓一体的架构是怎样的?
Lakehouse 是一种新的架构模式,简单理解它有存储层和计算层组成的。如下图所示:
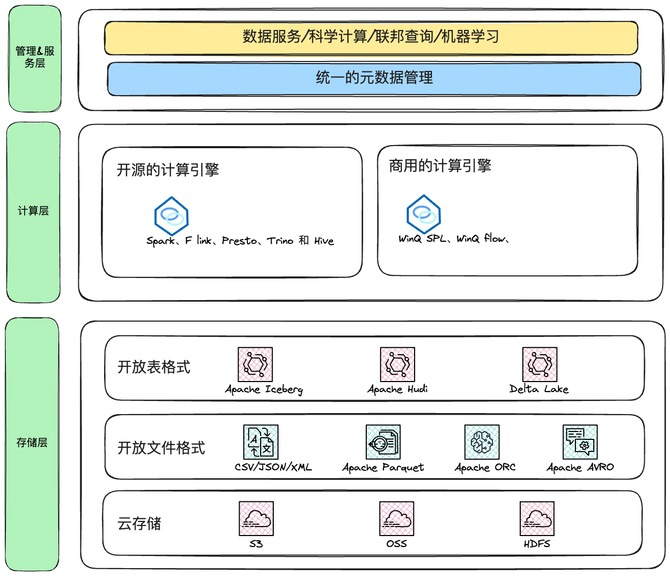
湖仓一体架构作为一种创新的数据管理解决方案,主要包含存储层、计算层,管理服务层三个层次。
存储层的构成
存储层由以下三个关键组件构成:
云存储:作为数据湖和Lakehouse平台的基础设施,云存储提供了必要的高可用性、持久性和可扩展性。无论是使用S3、OSS还是本地HDFS,云存储都是实现Lakehouse的理想选择,特别是考虑到成本效益、计算与存储分离以及易于扩展等因素。
开放的文件格式:Lakehouse支持多种数据文件格式,如CSV、JSON和XML。对于分析平台,Apache Parquet、Apache ORC和Apache AVRO这三种列式存储格式因其开源特性和广泛的兼容性而受到青睐。
开放的表格式:Lakehouse支持多种表存储格式,包括Apache Iceberg、Apache Hudi和Delta Lake。这些格式不仅支持时间回溯和schema推演,还提供了SQL查询、ACID事务保证等高级功能。
云存储的优势
云存储的推荐使用基于以下几点考虑:
成本效益:云服务通常按需计费,有助于降低存储成本。
计算与存储分离:这种分离架构允许独立扩展存储和计算资源,提高资源利用率。
易于扩展:云存储的弹性扩展能力保证了数据存储的灵活性和可扩展性。
开放文件格式
开放文件格式之所以重要,是因为:
兼容性:许多存储和处理引擎都支持这些格式,确保了数据处理的灵活性。
列式存储:优化了查询性能和存储效率,尤其适用于分析型工作负载。
开放表格式的功能
开放表格式如Apache Iceberg、Apache Hudi和Delta Lake为Lakehouse架构带来了:
时间回溯:能够查询数据的历史版本。
schema推演:支持数据模式的动态变更。
高级功能:如ACID事务、审计跟踪等,提高了数据的可靠性和安全性。
除了这些开源的表格式管理引擎以外,也有一些自研的表格式管理引擎,可以实现如上的功能。
计算层的特点
Lakehouse架构的计算层以其开放性和灵活性而著称。它允许使用任何兼容的处理引擎直接访问或查询数据,无需依赖特定的专有引擎。
计算引擎的多样性
计算层可以使用以下开源计算引擎:
Spark:支持批处理和微批处理,适用于复杂的数据分析。
Flink:专为流批一体低延迟数据处理设计,实现低延时、复杂的数据分析。
Trino(原PrestoSQL):一个高性能、分布式的SQL查询引擎。
Hive:提供了一种通过SQL进行数据查询和分析的能力。
计算层可以使用以下商用计算引擎:
W inQ SPL:支持高性能的批量处理,和高并发的复杂数据分析查询引擎。
W inQ flow: 支持批处理和微批处理,适用于复杂的数据分析,并支持高性能的数据查询引擎。
这些计算引擎可以高效地与存储层中的数据进行交互,支持从简单的数据查询到复杂的数据分析和机器学习工作负载。
管理和服务层的构成
管理服务层构成:
1、统一元数据管理:湖仓一体架构的统一元数据管理能力是指在一个集中的元数据管理层中,对数据湖和数据仓库中的元数据进行统一管理和维护的能力。这种管理能力允许用户在不同数据源之间实现元数据的一致性和可发现性,从而简化数据的访问和使用。
2、数据虚拟化管理:数据虚拟化是一种数据管理技术,它允许用户通过统一的接口访问多个分散的数据源,而无需物理地将数据集中或复制。通过统一的数据接口管理支持数据服务、科学计算、机器学习、联邦查询等多种应用场景。
02
—
湖仓一体架构特点和优势
湖仓一体的架构具有以下的架构特点:
事务支持:湖仓一体架构提供了对ACID事务的支持,确保了数据的一致性和可靠性。
Schema管理:支持对数据结构的严格管理,允许数据模式的演进,同时保持数据治理。
BI工具支持:可以直接在原始数据上使用BI工具,减少了数据转换和复制的需要。
存算分离:存储和计算能力可以独立扩展,适应不同的业务需求。
开放性:使用开放和标准化的数据格式如Parquet,支持多种工具和引擎直接访问数据。
多样化数据支持:能够存储和处理从非结构化到结构化的各类数据。
多工作负载支持:支持数据科学、机器学习、AIGC以及SQL和分析等多种工作负载。
这种架构特点和其它传统的大数据平台有以下几个方面的优势:
简化数据架构:通过统一数据存储,避免了数据在不同系统间的迁移和转换,降低了数据管理的复杂性。
提高数据利用率:由于数据的集中存储和统一管理,提高了数据的可访问性和分析效率。
降低成本:利用云存储的低成本特性,减少了数据存储和处理的成本。
加速创新:开放的架构支持快速集成新技术,加速了企业数据应用的创新和迭代。
03
—
湖仓一体架构应用场景
湖仓一体架构适用于多种数据应用场景,包括但不限于:
大数据分析:处理和分析大规模数据集,提供深入的业务洞察。
实时数据处理:支持实时数据流的处理和分析,满足即时决策需求。
机器学习和人工智能:提供数据科学家和AI工程师所需的数据基础,支持模型训练和部署。
数据集成和联邦查询:简化来自不同数据源的数据集成,实现联邦查询和统一视图。
湖仓一体数据架构在AIGC(人工智能生成内容)的应用中,特别是在多模态数据推理和微调的场景中,展现出了显著的优势。这一架构通过整合数据湖的灵活性和数据仓库的高效性,为大模型提供了强大的数据支持和处理能力。
1、数据集成与统一管理:湖仓一体架构允许企业将来自不同源的数据快速整合到一个统一的平台中进行管理和分析,这为多模态数据的集成提供了便利。
2、高性能计算支持:通过计算层的优化,湖仓一体能够支持大模型在数据预处理、特征工程等环节的并行化处理,从而提升整个数据处理链路的效率。
3、实时数据处理:湖仓一体架构支持实时数据的入湖和处理,这对于需要快速响应的AIGC应用至关重要,如实时内容生成和交互式应用。
4、多模态数据融合:湖仓一体架构可以处理和分析来自不同模态的数据,如文本、图像、声音等,支持构建更为复杂的多模态AI模型。
5、微调与优化:在多模态大模型的微调过程中,湖仓一体提供了必要的数据支持和计算资源,使得模型能够针对特定任务进行优化和调整。
综上所述,湖仓一体数据架构为AIGC提供了一个高效、灵活且安全的数据管理和处理平台,特别是在多模态数据推理和微调的应用场景中,其优势尤为明显。通过这一架构,企业能够更好地利用大数据和AI技术,推动业务创新和智能决策。

