导读 :本文介绍了 Apache Hudi 从零到一:并发控制。本文翻译自原英文博客 https://blog.datumagic.com/p/apache-hudi-from-zero-to-one-710。
主要内容包括以下几个部分:
1. 并发控制概述
2. Hudi 中的 MVCC
3. Hudi 中的 OCC
4. 总结
分享嘉宾|许世彦 Onehouse 开源项目负责人
编辑整理|郁婕
出品社区|DataFun
在前一篇文章中,我们通过对聚类过程和空间填充曲线的深入探讨,完成了对表服务的论述。基于在前几篇文章中所获取的知识,我们能够顺利地过渡到下一个主题:并发控制,具体来讲,是针对多个写入器及表服务的并发。
01
并发控制概述
对 Hudi 表的每一次提交都构成一个事务,无论是添加新数据还是执行表服务作业。并发控制旨在协调同时执行的事务,以确保其正确性和一致性,同时维持卓越的性能。网上存在众多有价值的相关资源,例如这门课程(https://15445.courses.csNaNu.edu/fall2023/)和这篇论文(https://dsf.berkeley.edu/papers/fntdb07-architecture.pdf)。本概述旨在为后续深入探讨 Hudi 并发控制的实现提供充足的背景信息。
在数据库中,ACID 是维护事务完整性和可靠性的四个关键属性。在下方提供的图表中,我对 ACID 进行了简要归纳,力求呈现清晰且易于牢记的概述。
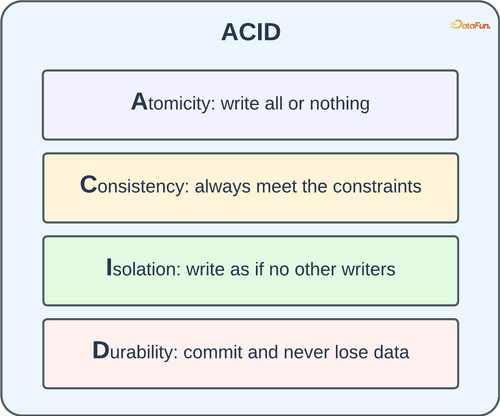
原子性(Atomicity)要求每个事务都被视为一个不可分割的工作单元;若事务中途失败,其所做的任何更改都应予以回滚。一致性(Consistency)关乎应用程序特定的约束;例如,主键字段不能有重复,或产品价格列必须为非负。隔离性(Isolation)确保并发事务相互隔离,使得更改如同顺序执行一般。持久性(Durability)规定已提交的数据必须在存储上得以保存,以抵御诸如硬件故障等事件的影响。
若不遵循隔离性属性,并发事务将引发读写异常,如脏数据、丢失更新等。尽管强制所有事务严格串行执行可消除这些异常,但这会严重影响性能,导致系统实际上无法使用。因此,我们应允许并发执行以提升性能,并将其协调为等同于串行调度的正确性。换言之,我们所需的是一个可串行化的(Serializable)调度。
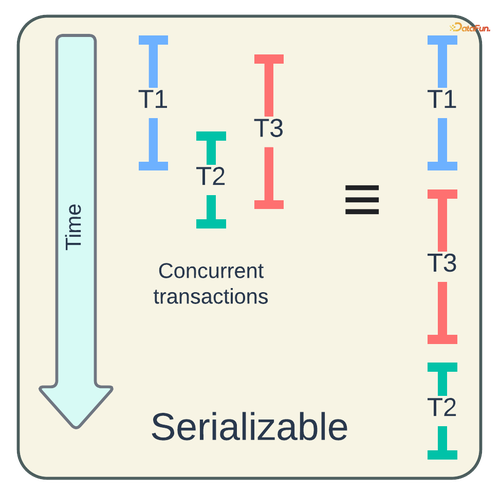
MVCC(多版本并发控制)和 OCC(乐观并发控制)是各类数据库系统中广泛采用的用于实现可串行化调度的两种策略。MVCC 在存储上保留多个记录版本,并将它们与单调递增的事务 ID(例如,时间戳)相关联。OCC “乐观地” 允许并发事务先自行进行,而后再解决任何冲突。Hudi 采用 MVCC 来处理单个写入器与并发表服务的情形,无需进行锁定。在后续版本中,添加了 OCC 实现以支持多写入器场景。在接下来的部分中,我们将探讨 Hudi 如何运用这些策略来应对并发写入器和表服务的情况。
02
Hudi 中的 MVCC
时间轴和文件切片是 Hudi MVCC 实现的基础。时间轴使用单调递增的提交开始时间来跟踪对表的事务。文件切片的设计实现了对记录的版本控制,并与事务时间戳相对应。在此之上,Hudi 构建了一个视图对象,即 TableFileSystemView,提供 API 以返回表的最新存储状态,例如分区路径下的最新文件切片,以及进行聚类的文件组。写入器和读取器始终参考表文件系统视图来决定在何处执行实际的 IO 操作。这种设计默认提供了读写隔离,因为新数据的写入不会干扰读取器访问过去的版本。
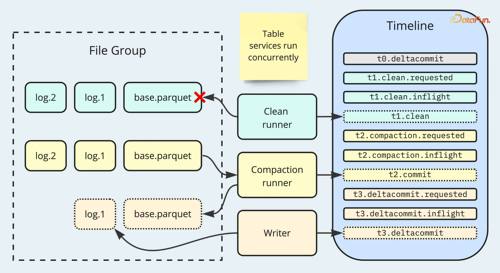
MVCC:Hudi 表服务与写入器并行运行
当写入操作进行时,指示此写入的提交操作将在时间轴上标记为“请求”或“进行中”。这使得表文件系统视图能够知晓正在进行的操作,确保表服务规划器不会将当前正在写入的文件切片纳入后续执行。这种逻辑在并发表服务作业的场景中同样适用。Hudi 的表服务是幂等操作,因为包含有关读取哪些文件切片信息的计划会被持久化。因此,在失败情况下的重试不会影响最终结果。
当压缩正在进行时,对 MoR 表的任何新写入将要么将新记录路由到新的文件组,要么将更新/删除附加到日志文件。压缩作业正在生成的基本文件将被视图排除,以防止误用。当聚类待处理时,用户可以配置写入器在更新进行聚类的文件组时的行为:中止写入、回滚聚类、推迟到以后解决冲突(OCC),或对源和目标聚类文件组进行双重写入。清理始终以保留最新文件切片的方式执行,使删除与新写入互不干扰。
03
Hudi 中的 OCC
OCC 协议通常包括三个阶段:读取、验证和写入。在读取阶段,并发写入器执行必要的 IO 操作以独立完成其工作。在验证阶段,收集每个写入器的更改列表,并确定是否存在任何冲突。最后,在写入阶段,如果没有发现冲突,则接受所有更改;如果出现冲突,则事务时间较晚的写入器的更改将被回滚。这与 GitHub 的工作流程类似:贡献者可以向上游存储库提交拉取请求。对于有冲突的拉取请求,合并将被阻止,这与 OCC 中的验证阶段类似。
由于并发更新可能导致写入异常,Hudi 在文件级别粒度上实现 OCC 以处理多写入器场景。要启用此功能,用户需要将“hoodie.write.concurrency.mode”设置为 OPTIMISTIC_CONCURRENCY_CONTROL,并相应地配置一个锁提供程序。下面的图表展示了 OCC 如何集成到 Hudi 的写入流程中。
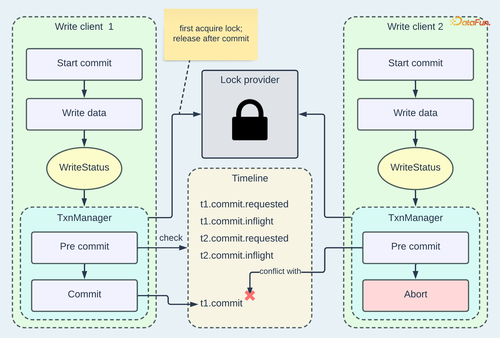
Hudi OCC 流程在多写入器场景中的示例
重点介绍一下图表中的一些关键步骤:
写入客户端 1 正在写入 t1.commit,并首先从锁提供程序获取锁,该锁提供程序通常使用外部运行的服务器(如 Zookeeper、Hive Metastore 或 DynamoDB)实现。
在持有锁的同时,写入客户端 1 可以专门检查时间轴,以查看在其自己尝试之前是否有任何并发提交已完成。在这个例子中,写入客户端 2 的 t2.commit 是唯一需要检查的候选时间轴瞬间,并且它仍在进行中,因此客户端 1 可以继续提交并释放锁。
写入客户端 2 正在写入 t2.commit,并在客户端 1 释放锁后获取锁。在预提交阶段,客户端 2 从 WriteStatus 获得的更改文件与客户端 1 从 t1.commit 派生的更改文件冲突。因此,客户端 2 将中止写入。
中止的写入将被回滚,这意味着所有写入的文件(包括数据和元数据)都将被删除,就好像写入从未发生过一样。虽然这满足了 ACID 属性中的原子性,但也可能造成浪费,特别是在冲突概率较高的情况下。Hudi 为 OCC 提供了早期冲突检测模式。在这种模式下,在实际写入文件之前,会在临时文件夹中创建轻量级标记文件。这些标记文件作为冲突检查的初步步骤。有关早期冲突检测的设计和实现的详细解释,请参考此社区演讲(https://www.youtube.com/watch?v=sgfMdeD-yk4)。
04
总结
在本篇博客文章中,我们在深入探讨 Hudi 中两种策略(MVCC 和 OCC)的实现细节之前,对并发控制主题进行了简要阐述。这些策略被巧妙地运用于处理涉及单个写入器与表服务以及多个写入器的场景。

