在数字化时代,数据无疑扮演着重要角色。新时期的“石油”、“黄金”,甚至是电力……这些比喻形象地揭示了数据在现代社会中的巨大价值。然而,需要注意的是,即便是规模最为庞大的数据集,如果缺乏妥善的组织和管理,可能会变得一文不值,甚至成为企业的沉重负担。
数据的广泛收集与深入分析已经深刻改变了人们的生活方式和企业的运营模式。从公司内部交易的细微末节到个人日常生活的习惯偏好,一切都可以被精准测量、高效存储并深入分析。在当今的商业环境中,几乎找不到一家不依赖数据驱动型见解来推动决策和创新的现代企业。
这种收集、分析和利用数据的能力,不仅重塑了企业内部的运营流程,还彻底改变了企业与医疗保健、金融、零售等各个行业客户的互动方式。此外,随着移动设备、物联网以及现代机器学习和人工智能技术的飞速发展,更多行业开始与数据深度融合,形成了全新的数据生态体系。
在我们进一步探讨数据仓库、数据湖以及数据湖仓一体的优缺点之前,先来了解下数据存储的变化,以帮助企业更好地理解和选择适合自身业务发展需求的数据存储与分析方案。
数据存储简史:从泥板到数据湖仓一体的演变
自古以来,人类就认识到了数据的价值。最早的文字记录之一——泥板,可能就是用于记录交易信息的载体,这标志着数据存储历史的开端。而巨石阵等古代遗迹,则可能被视为人类早期尝试分析太阳位置以预测季节性条件的弹性数据存储方式,尽管这些解释仍存在一定的争议和猜测,但数据的重要性不言而喻。
随着社会的进步,数据在社会中的重要性日益凸显,处理数据的工具也经历了翻天覆地的变化。泥板作为数据存储的媒介,虽然令人印象深刻,具有3500年数据保留能力,但在数据访问速度和向前兼容性方面却存在明显的不足。这促使人类不断探索更加高效、便捷的数据存储和处理方式。
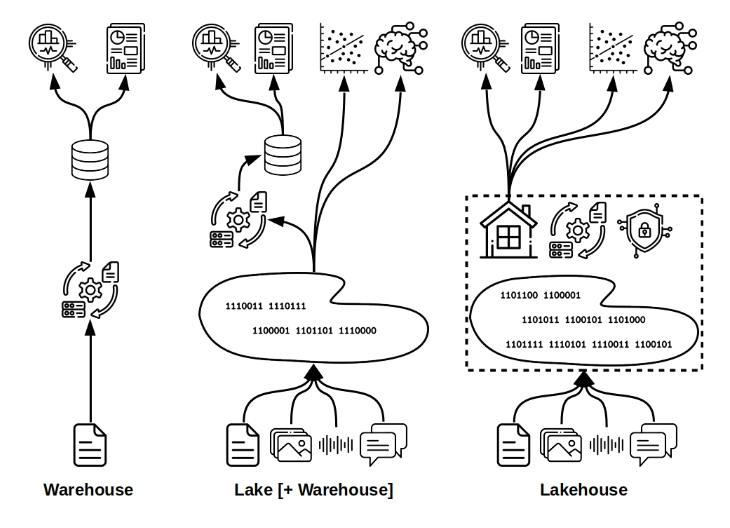
到了20世纪80年代后期,随着计算机技术的飞速发展,数据仓库应运而生。它基于更早开发的想法,旨在满足当时商业智能和数据分析的需求。尽管数据仓库在处理结构化数据方面表现出色,但随着数据量和处理速度的不断增长,以及治理、结构和监管要求的日益严格,数据仓库的使用案例逐渐受到限制。
为了应对这一挑战,数据湖的概念应运而生。与数据仓库相比,数据湖增加了对半结构化和非结构化数据的支持,这使得它能够处理更加多样化的数据类型。然而,数据湖在治理和安全性方面仍存在一些挑战,这限制了其在某些场景下的应用。
为了解决数据湖和数据仓库的局限性,数据湖仓一体的概念应运而生。它结合了数据湖和数据仓库的优点,从头开始构建了一个真正混合的解决方案。数据湖仓一体不仅支持多种数据类型,还通过更好的治理机制提高了数据的灵活性和安全性。这使得它成为当前数据存储和处理领域的一种理想选择。
数据仓库:结构化数据的决策支持与商业智能基石
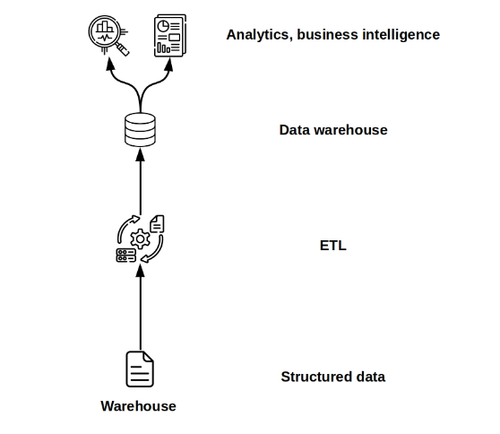
数据仓库,作为存储、查询及操作数据的核心存储库与平台,专为决策支持和商业智能领域的结构化数据设计。历经数十年的演进,尤其是在大规模并行处理和分布式计算技术的推动下,现代数据仓库已变得更加高效、灵活且可扩展。尽管它们仍保留着上世纪早期发展的痕迹,但已远非昔日可比。
追溯至1970年代的数据集市概念,数据仓库经历了漫长的孕育期,直至1980年代末至1990年代初,在IBM等企业的推动下,才开始实现商业化应用。数据仓库有效解决了数据集市低效、孤立的问题,即各部门各自为政、维护的数据存储缺乏统一性与整合性。
自此,数据仓库领域取得了显著进展,涌现出众多知名厂商与项目,如科技巨头Google BigQuery、Amazon Redshift、Microsoft Synapse,以及Yellowbrick、Teradata和Snowflake等。此外,DuckDB等现代项目也为数据仓库领域注入了新的活力。
相较于Snowflake、Databricks等现代数据平台,数据仓库总体上更为封闭,采用专有数据格式、严格的架构及治理机制。然而,这也使得数据仓库的学习曲线相对较短,更适合技术背景较弱的最终用户。尽管如此,这些系统在灵活性和运营透明度方面仍有待提升。
近年来,移动设备、云计算及物联网技术的迅猛发展,极大地推动了数据量和处理速度的增长。大数据及相关技术(如Hadoop和Spark)的崛起,进一步加速了数据仓库行业的转型,促使其从传统起源向云数据仓库迈进。
现代数据仓库在数十年的持续改进中受益匪浅,已成为结构化分析与决策支持领域的卓越选择。它们不仅比以前更加灵活、强大,还不断适应新平台(如数据湖)的功能及日益复杂的数据需求(如治理和安全性)。在数据驱动决策日益重要的今天,数据仓库将继续发挥关键作用,助力企业挖掘数据价值,实现智能化转型。
数据湖:数据科学与深度机器学习的灵活选择
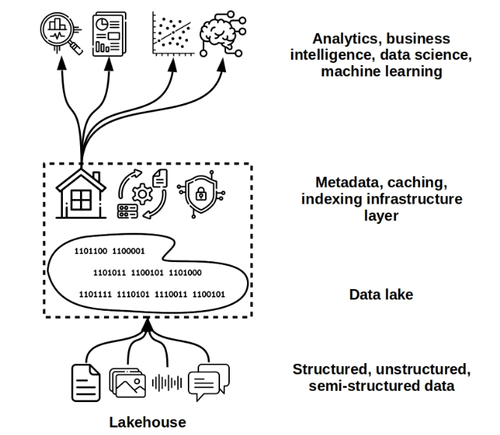
在数据科学和深度机器学习的领域里,数据湖正逐步成为传统数据仓库平台的有力替代者。数据仓库,以其严格的架构组织和专有数据格式,长期以来一直是结构化数据存储与分析的首选。然而,随着非结构化和半结构化数据量的急剧增长,数据湖以其高度的灵活性脱颖而出,为数据科学家和机器学习工程师提供了更为广阔的舞台。
商业数据湖产品已无缝集成至各大云平台,如Google的BigLake、Microsoft的Azure Data Lake以及Amazon的S3 Data Lake,这些产品不仅继承了云平台的强大功能,还进一步增强了数据处理的灵活性和可扩展性。与数据仓库不同,数据湖通常构建在Delta Lake、Apache Hudi等开源工具和框架之上,这些工具为数据湖提供了强大的数据管理和处理能力。
一些大型科技公司,如Uber和Netflix,更是凭借内部的专业知识,定制了专属于自己的数据湖解决方案。Uber开发的具有增量ETL(提取、转换、加载)功能的复杂混合方法,以及Netflix为满足数据湖和仓库需求构建的复杂混合基础设施,都充分展示了数据湖在定制化方面的巨大潜力。
然而,数据湖与数据仓库在数据处理方式上存在着显著的差异。在数据仓库中,ETL过程被视为数据存储前的必要步骤,以确保数据的结构和查询性能满足分析和商业智能的需求。而在数据湖中,原始数据可以直接存储和访问,ETL过程则作为一个可选的、按需应用的步骤。这种处理方式虽然降低了数据的即时性能,但为用户提供了更大的灵活性和自由度。
数据湖以牺牲部分查询性能和增加学习曲线为代价,换取了对半结构化和非结构化数据的广泛支持。在数据湖中,开放数据格式的使用意味着用户可以摆脱供应商锁定的束缚,享受更加自由的数据处理和分析环境。此外,数据湖还可以利用云提供商的Spot实例等成本优化手段,实现可观的成本节省。然而,这也需要用户具备足够的内部专业知识和资源来维护和优化数据湖环境。
尽管数据湖在灵活性、成本效益和数据处理能力方面表现出色,但在基础设施、治理和关系分析方面仍存在不足。相比之下,数据仓库在处理结构化数据、关系查询和业务分析方面仍然具有无可比拟的优势。因此,将两者结合起来,构建一种混合架构,成为了许多组织在追求数据现代化过程中的理想选择。
这种混合架构将数据湖与一个或多个数据仓库耦合起来,既保留了数据仓库在处理结构化数据和关系查询方面的优势,又充分利用了数据湖在处理非结构化和半结构化数据方面的灵活性。然而,这种混合架构也带来了自身的挑战,如数据同步、治理和性能优化等问题。
对于那些希望在不完全切换到现代数据平台的情况下逐步实现现代化的组织来说,混合架构无疑是一个可行的选择。然而,对于那些希望从头开始构建真正混合解决方案的组织来说,他们需要思考的是如何结合数据湖和数据仓库的优势,同时克服两者之间的局限性,以打造出一种既高效又灵活的数据处理和分析环境。
数据湖仓一体:现代数据治理与基础设施的优化之道
在数据治理和基础设施领域,数据湖虽然以其灵活性和可扩展性著称,但仍面临诸多挑战。若缺乏适当的基础设施和治理机制,数据湖很容易沦为数据“沼泽”,进而引发一系列问题,正如湖仓一体之父Bill Inmon在《构建湖仓一体》一书中所警示的那样,“沼泽在一段时间后开始散发气味”。
为了应对这些挑战,湖仓一体(Lakehouse)概念应运而生。这一概念旨在结合数据湖的灵活性与数据仓库的治理和性能优势,以满足现代数据处理的多样化需求。Lakehouse不仅保留了数据湖对半结构化和非结构化数据的广泛支持,还通过引入一个基础设施层,实现了元数据、索引的添加,以及治理和ETL(提取、转换、加载)的改进,从而增强了对传统查询和关系分析的支持。
在Lakehouse的推广和发展方面,Databricks无疑走在了前列。2020年,Databricks发布了一份白皮书,详细阐述了Lakehouse的概念及其优势。该白皮书指出,Lakehouse能够更自然地与Python和R等编程语言配合使用,支持连续ETL和架构,以保持结构化数据的最新状态。这使得商业智能仪表板和关系查询等应用能够轻松实现,同时降低了供应商锁定的风险,因为Lakehouse使用了开放数据格式。
与数据湖相比,Lakehouse在数据一致性和可靠性方面表现出色。它支持ACID(原子性、一致性、隔离性和持久性)事务,从而避免了多个用户同时访问和分析数据时可能出现的冲突和副作用。此外,Lakehouse还改进了数据版本控制功能,能够跟踪从数据摄取到转换和分析的全过程,确保数据沿袭的清晰可追溯,提高了数据的可靠性和可信度。
在法规遵守方面,Lakehouse也展现出了其独特的优势。随着《健康保险流通与责任法案》(HIPAA)、《加州消费者隐私法案》(CCPA)以及欧盟《通用数据保护条例》(GDPR)等法规的出台,数据治理和合规性要求日益严格。Lakehouse通过提供强大的基础设施和治理功能,帮助企业更容易地遵守这些法规,确保数据的安全性和合规性。
可以说,湖仓一体(Lakehouse)作为现代数据治理和基础设施的优化之道,不仅保留了数据湖的灵活性,还通过引入基础设施层和治理机制,增强了数据的可靠性、一致性和合规性。随着技术的不断进步和应用场景的不断拓展,Lakehouse将成为未来数据处理和分析领域的重要趋势。
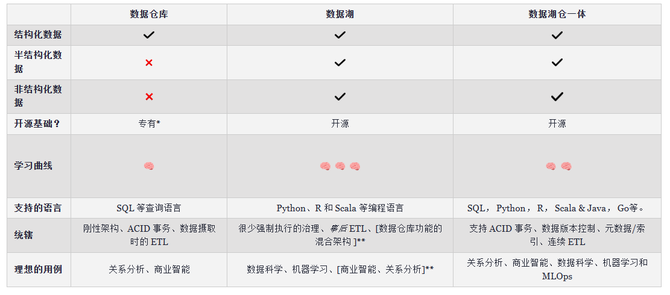
▲数据仓库、数据湖以及湖仓一体对比
结论
数据仓库,作为对上世纪企业数据需求激增的一种产物,以其高度结构化和专有数据源处理的特质,无疑统领了整个时代。尽管数据管理技术在不断变迁,数据仓库仍是经典之作,为传统商业智能和关系数据分析提供了卓越的性能表现,且其学习曲线相对平缓,托管仓库服务更是进一步减轻了最终用户在数据管理上的技术负担。然而,这一优势是以牺牲灵活性为代价的。
相比之下,数据湖以其对现代数据需求的灵活支持、开放数据格式的应用以及降低计算成本的潜力而崭露头角。尽管数据湖在支持数据科学和机器学习工作流方面表现出色,但在满足更传统的数据分析需求,如SQL查询和业务报告方面,却显得力不从心。此外,数据湖虽被视为一种监管较为宽松的数据管理策略,但其本质上仍是集中式的,这与分布式访问和应用的需求形成了一定的矛盾。数据网格作为数据湖的去中心化替代方案,虽在分布式架构中保留了数据湖的部分优势,但同时也继承了其劣势。
为了兼顾数据湖和仓库的优势,兼顾各种架构优势的混合架构应运而生。然而,这种架构的实现需要权衡每个数据平台的核心优势,并付出相应的代价。在此背景下,湖仓一体(Lakehouse)作为一种从头开始构建的真正混合解决方案,应运而生。它巧妙地融合了数据仓库和数据湖的特质,同时汲取了过往的经验教训,以更好地响应现代数据需求。Lakehouse不仅性能接近传统分析仓库,还支持数据科学工作流和直接访问数据以训练机器学习模型的需求。
总体而言,湖仓一体以其强大的功能和适应性,成为满足现代企业数据需求的理想选择。它是现代视角与数十年数据工程智慧相结合的产物。然而,值得注意的是,数据湖仓一体也可能带来一些挑战,如用户对新特性的不熟悉以及技术维护和优化的复杂性。因此,在实施数据湖仓一体时,企业需要充分考虑这些因素,并制定相应的策略以应对潜在的挑战。

