DeepSeek的突然爆火,为AI领域注入了一针“强心剂”。熟悉的竞争场面再次上演,依旧是技术迭代的硝烟,同样是市场格局的重塑。只不过,这次的主角从之前的国际巨头换成了国内的新锐力量。不管身份如何变换,模型争霸的本质却未曾改变。从技术的突破,到生态的争夺,再到商业模式的博弈,DeepSeek的崛起不仅让我们看到了AI带来的新可能性,也再次印证了那句行业“老话”——铁打的应用,流水的模型。
铁打的应用,流水的模型
对于2C端市场,大模型宝座轮流坐,在这场没有终点的技术长跑过程中,不可能只有一款模型一家独大。在大模型苟日新、日日新的技术比拼过程中,用户的选择变得更加多样化,哪个大模型更强或者更适合自己就用哪个。使用方式也很简单,下载APP直接应用就可以了。
但是,大模型要想从2C走向企业级应用场景,并不是一件容易的事情,通常需要解决很多工程化问题。如何确保企业级AI应用能够满足所有用户的不同场景需求?以亚马逊云科技为代表的云厂商的做法是,不把所有鸡蛋放在同一个篮子里,打造模型平台,接入业内经典模型或者更有潜力的新兴模型,让用户按需选择。亚马逊CEO Andy Jassy在2024 re:Invent上分享道:“当我们让开发者自由选择他们想要使用的模型时,模型的多样性显而易见。这并不让我们感到意外,因为我们一次又一次地学到同样的教训:永远不会有单一的工具能够统治世界。”

所以,当DeepSeek快速出圈后,亚马逊云科技按照整体的模型策略选择在第一时间接入。DeepSeek于2024年12月推出DeepSeek-V3模型后,于2025年1月20日相继发布了参数规模达6710亿的DeepSeek-R1、DeepSeek-R1-Zero以及参数范围覆盖15亿至700亿的DeepSeek-R1-Distill系列模型。2025年1月27日,DeepSeek又新增了基于视觉的Janus-Pro-7B模型。这些模型均已开源,据称其成本效益比同类模型高出90%-95%。官方表示,该系列模型通过强化学习等创新训练方法,在推理能力方面具有显著优势。
目前,用户可以在Amazon Bedrock和Amazon SageMaker AI中轻松部署DeepSeek-R1系列模型,亚马逊云科技提供了4种部署方式。
1) 在Amazon Bedrock Marketplace部署DeepSeek-R1模型
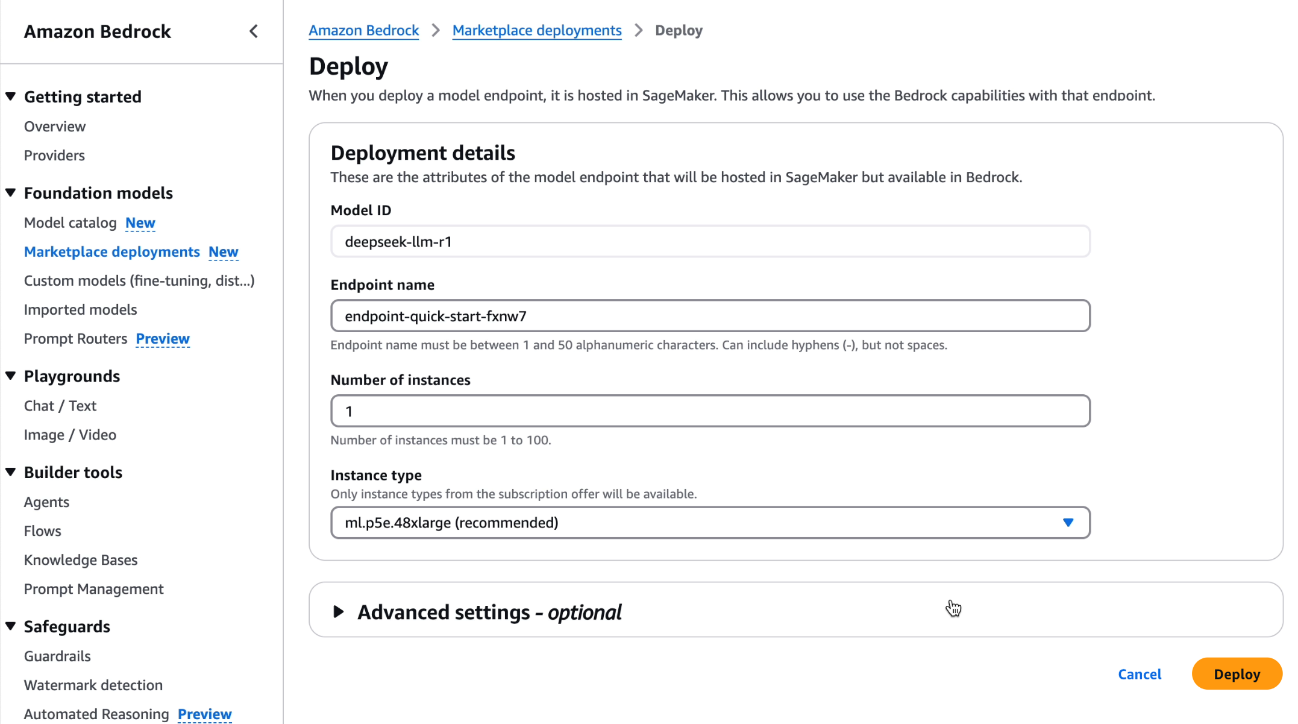
可选实例包括EC2 P5e的48xlarge型号,单个实例包含8颗H200 GPU,以及3200Gbps的网络带宽,充分满足DeepSeek-R1的性能需求。
2)通过Amazon SageMaker JumpStart部署DeepSeek-R1模型
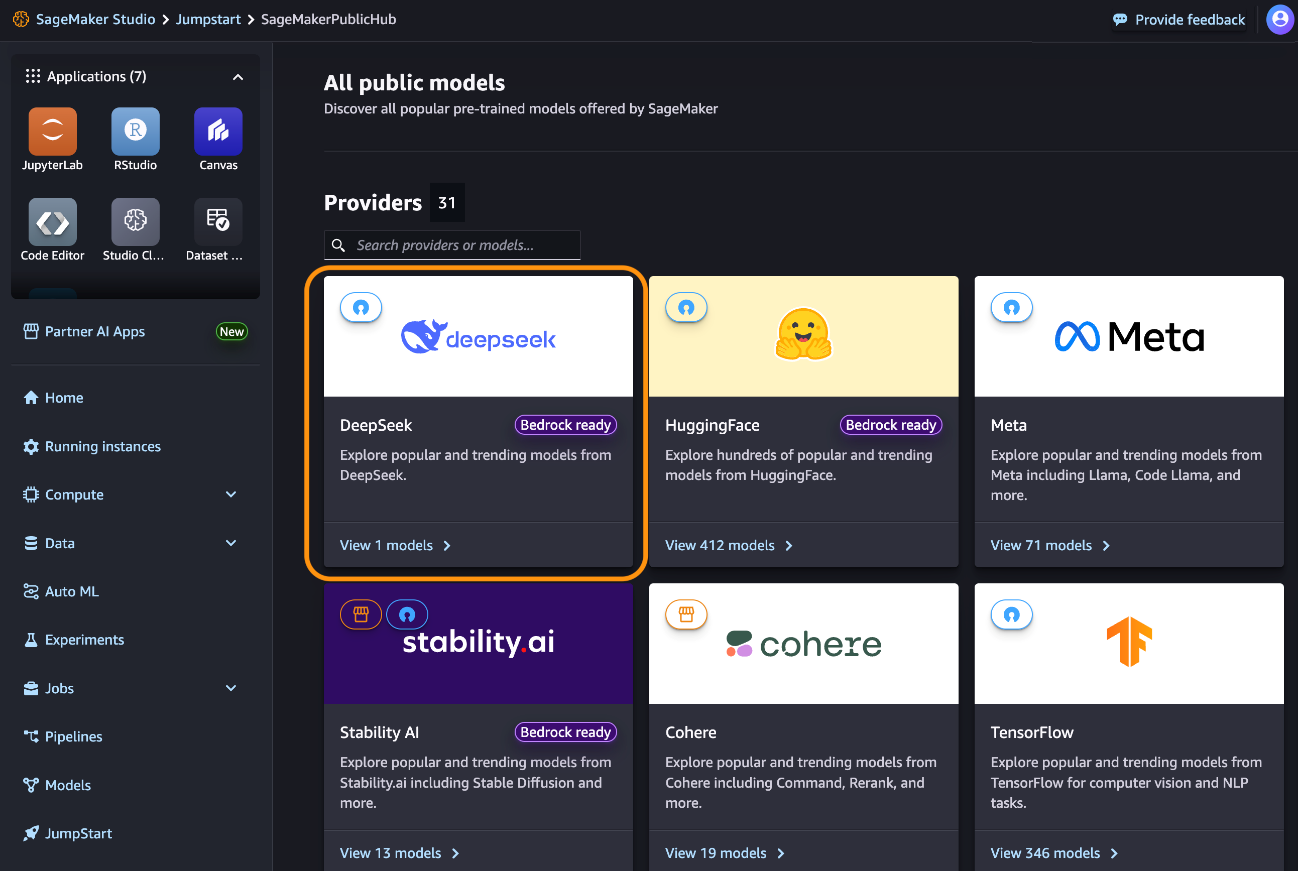
用户可以在Amazon SageMaker Unified Studio、Amazon SageMaker Studio、Amazon SageMaker AI控制台中找到DeepSeek-R1模型,或者通过Amazon SageMaker Python SDK以编程方式进行部署。
3)利用Amazon Bedrock的自定义模型导入功能部署DeepSeek-R1-Distill模型
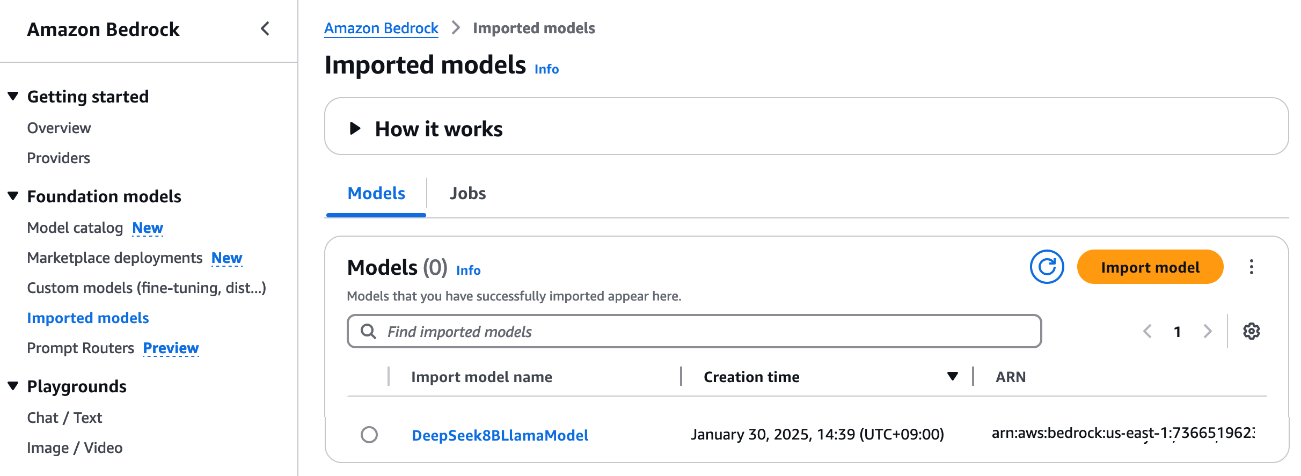
用户可以自定义导入参数规模在15亿到700亿之间的DeepSeek-R1-Distill Llama模型,同时可以利用6710亿参数的大型DeepSeek-R1模型,也可以蒸馏训练更小、更高效的模型。
4)使用Amazon EC2 Trn1实例部署DeepSeek-R1-Distill模型
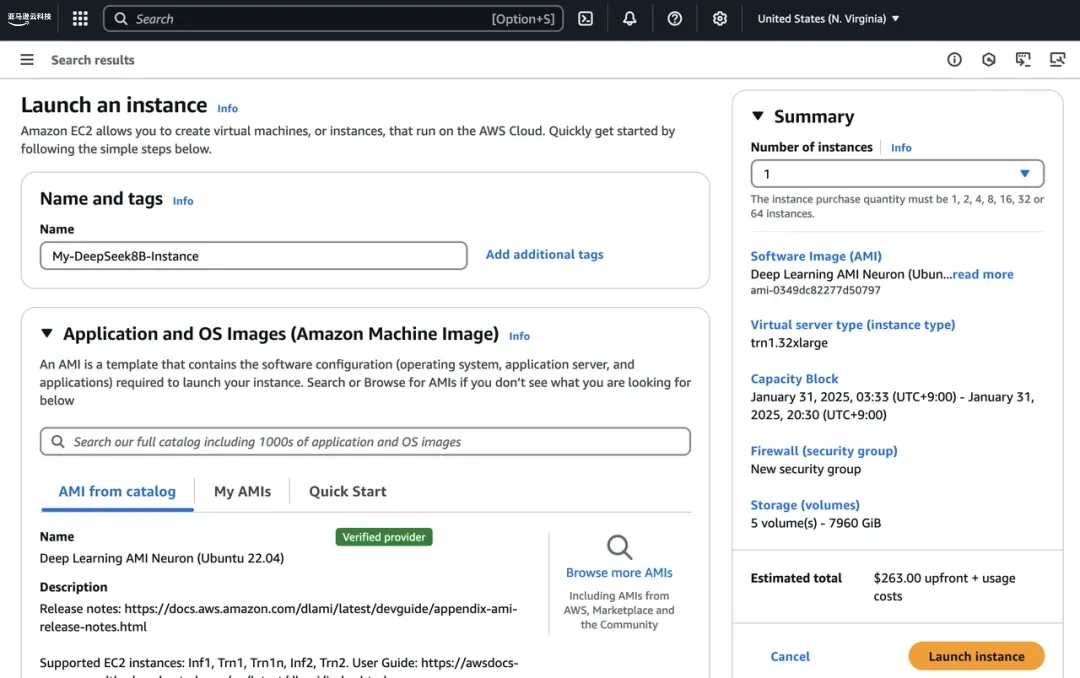
亚马逊云科技深度学习AMI(DLAMI)提供了定制化的镜像,用户可以使用Amazon EC2的任意实例类型,无论是仅配备CPU的小型实例,还是最新的高性能多GPU实例,都可以进行深度学习训练。
通过上述部署方式,用户可以零门槛体验新锐大模型。当然,选择接入DeepSeek的企业并非只有亚马逊云科技一家。DeepSeek霸榜春节热搜后,来自平台、算力、应用等各个层面的公司都在争抢这泼天的“流量”,选择与DeepSeek“联姻”。问题是,用户为什么不直接去应用DeepSeek,而是通过以亚马逊云科技为代表的第三方平台去接入?市场狂欢背后,我们看到先行者正在以更超前的远见和定力,从这场AI竞赛中跨越出周期性的桎梏,成为战略战术上的赢家。
三大优势助力企业加速生成式AI应用构建旅程
要知道,企业级生成式AI应用构建路径与2C应用不同。首先,在部署过程中,需要价格不菲的硬件。其次,需要提供稳定的API。再者,还需要构建面向用户端的应用并实施托管,更不用说高阶的针对企业私有数据的定制优化了。更重要的是,还需要考虑数据和模型的安全问题。
简单理解,要想让DeepSeek快速走向不同企业应用场景,需要的是全栈化技术能力以及生态上的大力支持。亚马逊云科技之所以成为企业构建和应用生成式AI的首选,是因为该企业不仅在云的核心服务层面持续创新,更在从芯片到模型,再到应用的每一个技术堆栈取得突破,让不同层级的创新相互赋能、协同进化。正如亚马逊云科技大中华区产品部总经理陈晓建所言:“只有全栈联动的大规模创新才能真正满足当今客户的发展需求,才能加速前沿技术的价值释放,助力各行各业重塑未来。”
综合而言,亚马逊云科技为企业运用全球领先模型提供了三大独特优势:
第一,云端优势。云既是生成式AI诞生的地方,也是企业运用生成式AI最好的方式。作为全球云计算的开创者和引领者,亚马逊云引领了一代又一代的云基础设施创新。例如,在自研芯片领域推出基于Amazon Trainium2的EC2 Trn2实例,性价比比当时GPU实例高30%-40%;第二代的UltraCluster网络架构,支持超过20,000个GPU协同工作,带宽达10Pb/s,延迟低于10ms,这一突破性升级将模型训练时间缩短至少15%;推出新一代Amazon SageMaker,将快速SQL分析、PB级大数据处理、数据探索和集成、模型开发和训练以及生成式AI等功能统一到一个集成平台,从而为客户提供一个单一的数据和AI开发环境,用户可以在其中查找和访问其组织中的所有数据,为各种常见的数据用例选择最 佳工具,并将数据和AI项目扩展至团队内不同分工角色以实现协作。
第二,多样化的模型选择优势。“不会有一个模型一统天下”,这是亚马逊云科技针对大模型发展的独特判断。在基于大模型构建应用时,不同的应用场景需要的技术指标也各不相同,延迟、成本、微调能力、知识库协调能力、多模态支持能力等等,都会因场景需求的不同而被取舍。以快速响应场景为例,DeepSeek R1的深层思考模式显然不太合适,据了解其生成首个token的用时超过30秒,而Amazon Nova则只需要数百毫秒即可生成响应。目前的DeepSeek-V3模型是文生文模型,并不支持图形等多模态信息的输入。显然,强如DeepSeek也不是万 能。
其于这一理念,亚马逊云科技在提供领先的模型如Amazon Nova系列之外,更加致力于为企业用户提供丰富的模型“选择”,为此构建了轻松接入全球领先模型的Amazon Bedrock,并不断扩展其模型“朋友圈”,现已有AI21 Labs、Anthropic、Cohere、Meta、Mistral AI、Stability AI、Luma AI和poolside等领先厂商。近期Amazon Bedrock正式上线了Luma AI Ray 2 模型。Ray2模型是一款由Luma AI推出的最新版本的视频生成模型,可以广泛用于内容创建、娱乐、广告和媒体使用案例,从而简化从概念到执行的创意流程。亚马逊云科技还推出了Amazon Bedrock Marketplace功能,为客户提供100多个热门、新兴及专业模型,这其中就包括DeepSeek-R1。
第三,构建企业级AI工具全家桶能力。基于场景选择合适的模型只是构建应用旅程的第一步,随着构建的深入,解决工程化难题的能力成为能否实现快速创新的关键。Amazon Bedrock聚焦企业应用AI的实际需求,在模型选择之外,增添了一系列重磅功能。借助Amazon Bedrock,包括DeepSeek-R1在内的领先模型都能轻松获取这些实用功能,并由此进入构建应用的快车道。这些实用型功能几乎涵盖企业级AI创新的方方面面,比如:低延迟优化推理、模型蒸馏、提示词缓存等功能,可以大幅提升推理效率,降低成本。同时,还可以对企业自有数据进行定制优化,让用户能够快速且经济高效地从文档、图像、音频以及视频中提取信息。另外,通过不断丰富 的Guardrails功能,可以简化企业实施负责任AI的投入。更重要的是,Amazon Bedrock不但提供智能体功能,还针对智能体的快速发展,进一步推出了多智能体协作功能,使客户能够轻松地构建和协调专业智能体来执行复杂的工作流程。
结语:
DeepSeek的爆火,既是AI技术体系独特性的彰显,也是整体生态不断进化的产物。从芯片指令集优化,到超大规模集群稳定保障,再到未来企业场景复杂度不断攀升,考验的是全栈技术能力。而以亚马逊云科技为代表的企业,在这场旷日持久的大模型战役中所扮演的角色是——既要躬身入局投入自己的大模型,也要以上帝的视角统领全局、聚焦应用,在与用户陪跑征程中进行长期投入。

