进入2025年,人工智能领域竞争变得更加白热化,其中以阿里QWQ-32B 、DeepSeek R1 和 O1 Mini为代表的三大主力模型表现更加亮眼,这些模型以各自的优势突破了推理、编码和效率的极限,为AI应用开发带来新范式。
QWQ-32B主打“以小博大”
阿里QWQ-32B是一个拥有320亿参数的人工智能模型,专为数学推理和编码而设计。与大规模模型不同,QWQ-32B通过使用强化学习优化性能进而提升效率,使得用户在不需要过多算力情况下就具有很高的模型性能。
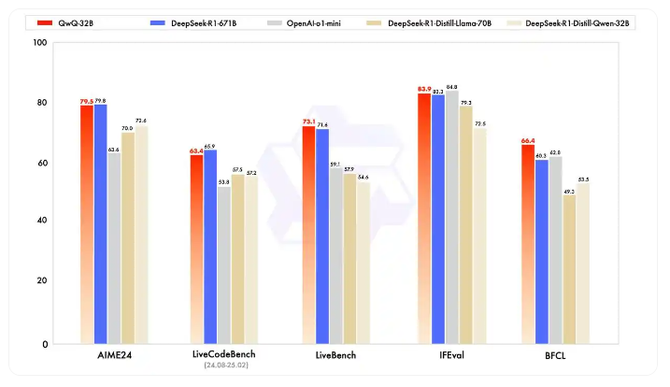
在推理基准测试中,QWQ-32B获得了79.5分的高分,尽管体积要小得多,但与DeepSeek R1竞争非常激烈。该模型能够在消费级硬件上运行,这使其成为企业和研究人员带来更经济实惠的大模型选择。
具备强大推理能力的DeepSeek R1
DeepSeek R1有6710亿个参数,但一次只能激活370个亿参数。这种结构在保持高水平推理能力的同时也提高了效率。DeepSeek R1在需要复杂逻辑的任务中占据主导地位,数学推理的基准得分为79.8分。DeepSeek R1可以集成到各种应用程序中,不管是教育,还是智能手机场景都能适用,已经成为通用模型的事实标准。
OpenAI O1 Mini成为速度与精度的完美结合
OpenAI的O1 Mini专注于stem相关的推理任务。这一版比上一代参数水平要小很多,但在速度和成本以及效率方面进行了优化。在推理基准测试中,O1 Mini的得分为63.6,落后于QWQ-32B和DeepSeek R1,但由于其精简的性能和可负担性,O1 Mini仍然是一个强大的对手。该模型可通过API集成广泛访问,使其成为需要在预算范围内提供人工智能解决方案的企业的实用解决方案。
基准测试不一定说明一切,但从一定程度上代表了行业竞争水平。QWQ-32B和DeepSeek R1在推理任务中占据主导地位,其中QWQ-32B得分为79.5分,DeepSeek R1得分为79.8分。o1mini虽然效率很高,但得分仅为63.6分。在编码方面,QWQ-32B的强化学习方法使其具有优势,在LiveCodeBench上获得63.4分,仅次于DeepSeek R1的65.9分。相比之下,OpenAI的o1mini稍显逊色,仅为53.8分。
那么问题来了,QWQ-32B为何能够脱颖而出?从技术变化的角度来看,QWQ-32B只拥有320亿个参数,但其性能水平与更大的型号不相上下,这一切都得益于技术迭代的结果,通过精炼推理的强化学习过程来达到效率。
另外,与智能体 Agent 的集成,是QWQ-32B的另一个能力。智能体与强化学习集成,使其更具主动适应性,提供批判性思考能力,而不仅仅依赖于知识库现有的信息进行刻板式反应。整体来看,DeepSeek R1在推理中提供的是缩小版参数的能力,同时消耗的资源显著减少,这应该是QWQ-32B成为颠覆者的根本原因。
人工智能大模型的未来已来
展望未来,人工智能的竞争已经走向新阶段,今天的大模型正趋向于小型化发展态势,并且性能更优。
QWQ-32B的最新表现说明,大模型在减少计算负荷的同时,变得更智能也是有可能的。同样,OpenAI的O1 Mini走的也是更经济高效的路径,适合那些可以花费较少投资将人工智能纳入其事务的企业。相信不久的将来,阿里巴巴vs OpenAI,将在开源人工智能领域展开霸主之战。
整体结论是,每个模型都有其擅长的点。在大规模推理方面,DeepSeek R1超越其他主流模型。与此同时,QWQ-32B在具体的路径实现上,则更具有竞争力,在保证应用性能的同时,而提供了更高的效率标准。同样的,O1 Mini是一款经济实惠的快速AI。当然未来还有很多不确定性,但可以准备判断的一点是,不管大模型技术路线如何演进,效率和适应性将是区分不同模型能力的显著特征。

