数字化浪潮汹涌而至,形成了一股强大的信息洪流。从单一视角来看,这些信息似乎并无实际业务价值,但当我们综合考量,却能为企业提供深刻且独到的见解。在此背景下,流处理技术应运而生,成为连接实时数据收集与可操作见解的桥梁,发挥着不可或缺的作用。
流处理能力需求增强是业务场景推动的结果
流处理是一种先进的数据处理实践,专注于处理来自众多来源的连续数据流。随着时代发展,实时数据流对现代AI模型的影响日益显著,尤其是在那些需要快速决策的应用程序中,实时数据处理能力是业务场景的基本要求。以自动驾驶汽车为例,必须在瞬间对路况变化做出反应,才能满足业务需求;在股票市场交易中,需迅速识别并防范欺诈行为,才能有效防范金融风险;智能工厂除了依靠传感器、机器人和数据分析等技术,在自动化和优化制造等流程同样依赖即时决策。在这些场景中,实时数据流为AI模型提供了关键支持,使其能够在数据进入时即时处理和响应,而非局限于使用陈旧的固定数据集。
实时处理能力除了在个别业务场景意义重大,对于那些决策结果影响重大的任务而言,也是至关重要。例如,有了实时处理能力,可以及时发现汇款中的欺诈行为,能够避免巨大经济损失。另外,对于调整在线商店的推荐内容而言,实时处理能力可提升用户体验和销售业绩;而自动驾驶汽车的即时决策,则直接关系到乘客的生命安全。通过利用实时数据,人工智能模型能够实时感知环境变化,快速适应新情况,并通过持续更新数据来优化性能,始终保持对环境的精准理解。
更为重要的是,实时流技术助力AI在边缘计算和物联网设置中高效运行。这些场景通常要求快速处理数据,若缺乏实时处理能力,人工智能系统将变得迟缓,在快速变化的数据密集型环境中失去竞争力,沦为“旧闻”的传递者。
从数据来源到流处理,技术架构的崛起
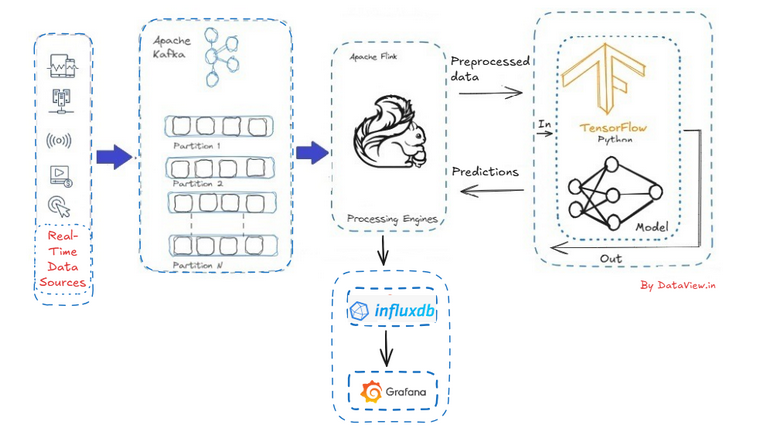
过去几年间,Apache Kafka已成为流数据领域的领军标准。如今,Kafka已无处不在,被财富100强中至少80%的企业所采用。其架构的多功能性使其非常适合大规模的“互联网”级数据流传输,同时确保了容错性和数据一致性,这对于支持关键任务应用程序至关重要。
而Flink则是一款高吞吐量、统一的批处理和流处理引擎,以大规模处理连续数据流的能力闻名于世。它与Kafka无缝集成,为精确一次语义提供强大支持,确保每个事件都能被精确处理一次,即使在系统故障时也不例外。因此,Flink自然成为Kafka的理想流处理器选择。尽管Apache Flink在实时数据处理领域取得了巨大成功并得到广泛应用,但获取足够资源和相关学习示例仍具有一定挑战性。
从数据流到洞察,实时特征工程的魔力
当实时数据流被插入多节点Apache Kafka集群,并与Flink集群集成后,便能够对摄取的流数据进行增强、过滤、聚合和转换等操作。这一过程对人工智能系统具有深远影响,因为它实现了实时特征工程,即在数据输入模型之前对其进行预处理。
以TensorFlow为例,这是一个开源的机器学习平台和框架,提供基于Python和Java的库和工具,旨在训练机器学习和深度学习模型。在Java环境下,我们可以通过伪代码展示如何将Apache Flink处理后的流数据传递给TensorFlow AI模型。具体而言,利用Flink的DataStream API从Kafka主题中摄取流数据,经过解析和处理后,将最终数据发送至TensorFlow进行预测。
从预测到可视化,构建完整的实时AI生态
然而,将TensorFlow的预测模型直接迁移至Grafana进行动态可视化并非易事。Grafana作为一款多平台、开源的分析和交互式可视化Web应用程序,本身并不适用于机器学习模型,而是专注于连接随时间存储数据的数据库。
因此,对于连续预测场景,我们需要借助InfluxDB、TimescaleDB(PostgreSQL扩展)或其他特定供应商的时间序列数据库。这种方法不仅适用于生产环境中的模型部署和跟踪,还支持实时监控、历史趋势分析以及机器学习模型的可观察性,为构建完整的实时AI生态系统提供了有力支持。
结论:实时AI,引领未来潮流
在快速变化的市场市场环境中,时间就是业务的生命线。缩小人工智能与实时数据之间的差距,已不仅仅是一项技术成就,更是我们在激烈竞争中脱颖而出的关键优势。通过Apache Kafka实现数据流式传输,并在实时仪表板上展示洞察结果,我们不仅能够实时观察正在发生的事情,更能主动塑造未来。
这种实时人工智能系统能够将原始数据转化为即时智能,无论是发现异常模式、优化推荐系统,还是指导运营决策,都发挥着重要作用。随着信息流动速度不断加快,那些能够迅速响应并利用数据的企业和个人,将引领时代潮流。因此,我们应积极连接数据流,让模型“思考”,为仪表板注入活力。当然,在这一过程中,我们仍需解决诸多技术难题,从数据清理到部署策略的选择,每一步都至关重要。但正是这些挑战,推动着我们不断探索和创新,迈向更加智能的未来。

