深度解析Tanzu Data Lake 4.0:私有云上的企业级大湖仓
在企业纷纷布局人工智能(AI)与大数据分析的今天,如何存储、管理并激活 PB 乃至 EB 级的结构化与非结构化数据,成为构建现代化 IT 架构的核心课题。
作为 Broadcom 旗下 VMware Tanzu 数据解决方案家族的明星组件,VMware Tanzu Data Lake (TDL) 4.0 于近期伴随 Tanzu Data Intelligence (TDI) 10.4 协同发布。它专为企业私有云环境(特别是 VMware Cloud Foundation, VCF)打造,提供了一套高度自动化、企业级安全、且与分布式数仓(Tanzu Greenplum)深度协同的现代数据湖(Data Lake)底座。
今天,我们就来深度剖析 Tanzu Data Lake 4.0 的技术架构、核心亮点以及它在 AI 时代为企业带来的独特价值。
什么是 Tanzu Data Lake (TDL)?
专为私有云优化的“云原生大数据中心”
传统的大数据架构(如自建 Hadoop/Spark)往往面临着部署繁琐、资源浪费、运维成本极高以及难以与云平台融合的痛点。
Tanzu Data Lake 4.0 则将经典的大数据技术栈与现代虚拟化技术深度融合。它基于 HDFS、YARN、Spark 和 Hive 等成熟技术,通过 Tanzu Data Intelligence Controller 实现了从物理底座到上层服务的一键式、全生命周期自动编排。
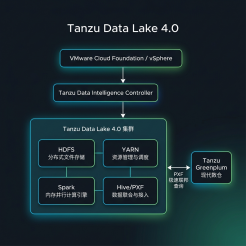
Tanzu Data Lake 4.0 架构图
TDL 4.0 的四大技术支柱:
1. 分布式存储(HDFS):高可靠、高弹性的分布式文件系统,能够存储和管理海量的任意格式文件,是冷热数据分级存储的理想载体。
2. 资源调度(YARN):集中式的资源管理器,协调和分配整个集群的 CPU 与内存资源,支持多租户、多作业的高效并发运行。
3. 极速并行计算(Spark):支持 Spark on YARN 以及 Spark Standalone 部署,专为大规模实时流处理、机器学习和数据挖掘设计。
4. 数仓黄金搭档(PXF / Hive):提供高效的元数据管理与外部表查询支持,与 Tanzu Greenplum 分布式数仓天然打通,直接实现“湖仓一体”联邦查询。
Tanzu Data Lake 4.0 核心重磅升级
Tanzu Data Lake 4.0 在高可用性、企业安全合规以及自动化 lifecycle 方面迎来了一系列突破性升级:
1.自动化 Lifecycle 掌舵者:TDI Controller 深度集成
在 4.0 版本中,Tanzu Data Lake 实现了与 Tanzu Data Intelligence Controller 的全方位深度集成。
模板化极速建湖:支持在 UI 界面中通过可视化向导,一键创建、编辑和管理数据湖集群。支持自定义模板属性,为不同业务场景量身定制集群规格。
自动化的基础设施同步:与 vSphere 和 VCF Automation 强强联合。管理员只需输入平台凭证, Controller 即可自动调配计算、存储(vSAN)与网络(NSX)资源,从零构建高性能大数据节点。
弹性主机管理(Host Management):支持对集群主机进行在线编辑、添加和安全下线,满足业务淡旺季的弹性资源缩扩容。
2.金融级安全合规:SSL 与 Kerberos 开箱即用
大数据集群的安全性一直是企业审计的重中之重。TDL 4.0 提供了完善的系统防护与加密功能:
强身份认证(Kerberos):在集群创建阶段,即可一键配置并同步 Kerberos 认证,确保只有授权的用户和作业能够访问核心 HDFS 存储和提交 YARN 任务。
全链路加密(SSL):支持在集群内部组件(如 NameNode、DataNode、YARN ResourceManager 等)之间自动配置并部署安全证书,保障数据传输过程中的绝对机密性。
3.平滑无感升级:NameNode Rolling Upgrade 机制
当数据湖的规模达到 PB 级别时,任何停机维护都可能对上层分析业务造成毁灭性打击。
TDL 4.0 引入了极其强健的 NameNode 滚动升级(Rolling Upgrade) 机制。
运维人员可以使用类似 hdfs dfsadmin -rollingUpgrade 的精细化控制流程,在完全不影响当前正在进行的读写作业(Read/Write Operations)的前提下,实现 NameNode 主备节点的平滑大版本升级,彻底告别“维护窗口期”的烦恼。
4.高可用的备份与灾备操作
一键式备份管理(Backup Operations):通过 Controller UI 集中管理集群元数据和系统配置的备份,支持定义定时备份策略、手动备份触发,大幅提升了极端故障情况下的灾难恢复时间(RTO)。
湖仓一体黄金拍档:Tanzu Greenplum + Tanzu Data Lake
在企业的实际生产中,Tanzu Data Lake 与 Tanzu Greenplum MPP 数据库往往形影不离,共同构建现代化“湖仓一体(Lakehouse)”架构:
┌────────────────────────────────┐
│ 企业数据应用 / AI 平台 │
└───────────┬────────────────────┘
│ (极速 SQL 查询)
▼
┌───────────────────────────┐
│ Tanzu Greenplum 数仓 │
│ (热数据 / 高并发事务查询) │
└─────────────┬─────────────┘
▲
│ (PXF 平台扩展框架)
▼
┌───────────────────────────┐
│ Tanzu Data Lake 4.0 │
│ (温冷数据 / Spark 流计算) │
└───────────────────────────┘
冷热数据分级存储:企业可将近期的、高频查询的“交易和流水热数据”存放在 Tanzu Greenplum 中以获取极致查询性能;而将历史长周期、低频访问的“温冷数据”自动归档至 Tanzu Data Lake 的 HDFS 存储中,大幅降低存储总拥有成本(TCO)。
免 ETL 的数据共享:借助平台扩展框架(PXF),Greenplum 可以直接读取 TDL 集群中的 Hive 表或 HDFS 原生数据,无需进行任何物理上的数据搬运(ETL),实现湖仓数据互通。
双模计算架构:面向高并发的交互式 BI 报表,由 Greenplum 的大规模并行计算引擎支撑;面向复杂的非结构化分析和长周期机器学习模型训练,则提交给 TDL 中的 Spark 集群运行,计算资源互不干扰。
总结:重塑大数据,助力 AI 落地
VMware Tanzu Data Lake 4.0 不仅是一次技术栈的升级,更是将“云原生运维”带入企业级大数据的关键里程碑。通过深度融合 VCF 9 虚拟化底座和强大的 Controller 自动化引擎,TDL 4.0 让原本沉重、复杂的 Hadoop/Spark 集群变得像云服务一样即开即用、安全合规、平滑弹性。
如果您希望在私有云中打造稳定、安全、并与 Greenplum 深度协同的 AI 时代大数据基石,Tanzu Data Lake 4.0 将是您的绝 佳之选!
附:Tanzu Data Lake 4.0.0 核心组件兼容一览
Controller: 深度兼容 vSphere 8.x / VCF 9.x
Spark: YARN 模式与 Standalone 模式双选
生态整合: 完美支持 OpenMetadata (元数据治理), OpenSearch (检索分析), Airflow (工作流调度), Spark & Hive。

